Artificial intelligence (AI) is reshaping the world at an electrifying pace! From revolutionizing healthcare diagnostics to powering self-driving cars and supercharging financial predictions, AI is taking over.
But here’s the catch: An AI model is only as good as its performance. If your AI isn’t hitting peak performance, you’re leaving potential—and profits—on the table.
This guide will take you on a deep dive into AI model performance, giving you the insights and strategies to push your models to their absolute limits.

As you dive into the strategies and metrics for optimizing AI model performance, it’s important to recognize that true efficiency comes from integrating robust models into real-world solutions. For organizations aiming to translate high-performing AI into business value, explore our AI-driven software development services—designed to deliver scalable, production-ready applications that maximize your investment in artificial intelligence.
1. Introduction to AI Model Performance
1.1. What is AI Model Performance?
Obviously, everyone must know what AI model is, but AI model performance is something you may be unfamiliar with. In a simple way, AI model performance refers to how well an AI system accomplishes its intended tasks. It’s not only about accuracy but also about precision, recall, efficiency, scalability, and adaptability.
A high-performing AI model not only makes correct predictions but does so reliably, quickly, and efficiently across different real-world scenarios.
1.2. Why is AI Model Performance Critical?
AI model performance can make or break a system’s success. A poorly optimized AI model can lead to catastrophic outcomes such as a self-driving car misjudging a pedestrian’s movement, a fraud detection system overlooking fraudulent transactions, or a medical AI misdiagnosing a life-threatening condition. These failures not only cost businesses time and money but also impact human lives.
On the flip side, a high-performing AI model unlocks immense potential. It enhances:
- Unmatched Accuracy: Ensuring models make precise and reliable predictions, improving decision-making across industries.
- Lightning-Fast Efficiency: Reducing computational burden while improving scalability and responsiveness in real-time applications.
- Unshakable Trust: Increasing user and stakeholder confidence in AI-driven solutions, paving the way for broader adoption.
- Unstoppable Adaptability: Allowing AI models to thrive even in dynamic, ever-changing environments by learning and improving over time.
1.3. The Role of Performance in AI Lifecycle: Training, Testing and Deployment
AI model performance is not a one-time achievement; it’s an ongoing battle at every stage of its lifecycle. From initial training to deployment, each phase plays a critical role in ensuring the model functions optimally in real-world environments.
Training
This is where the foundation is built. AI models digest vast amounts of data to learn patterns, correlations, and relationships. However, if the training data is not diverse or properly labeled, the model risks being biased or ineffective. Ensuring high-quality data and robust learning processes here determines how well the AI will generalize in the future.
Testing
Once trained, the model faces the ultimate challenge—handling unseen data. This phase evaluates the model’s ability to make accurate predictions beyond the dataset it learned from. Rigorous testing through cross-validation and real-world simulations helps identify weaknesses, allowing for refinements before full deployment.
Deployment
The AI is finally set free into production environments where it interacts with real-world data and users. However, deployment is not the finish line—it’s where continuous monitoring and fine-tuning become crucial. Factors like data drift, changing user behavior, and system updates can degrade performance over time, requiring proactive maintenance to sustain efficiency and accuracy.
Neglecting performance at any of these stages can lead to poor results, unreliable predictions, and loss of trust in AI systems. A well-optimized AI lifecycle ensures not just accuracy but also longevity and adaptability in an ever-evolving landscape.
2. Core Concepts and Terminology
2.1. Model Accuracy vs. Model Performance: Understanding the Difference

Accuracy is often mistaken for performance, but the two are distinct. Accuracy refers to the fraction of correct predictions out of total predictions. However, performance is a broader concept that includes precision, recall, speed, efficiency, and scalability.
A model can be highly accurate but still fails miserably in a production environment due to slow response times, lack of adaptability, or biases in decision-making. True performance accounts for not just accuracy but also robustness, reliability, and real-world applicability.
2.2. Key Performance Metrics Explained
Since AI model performance is a multi-faceted concept, it requires evaluating various aspects with great care and precision. The key metrics to monitor include:
- Precision: Ensures your AI doesn’t generate false positives. Crucial for fraud detection and medical applications.
- Recall: Measures how well your model identifies actual positives. Vital applications like cancer detection where missing a case can have dire consequences.
- F1 Score: The golden balance between precision and recall, ensuring that neither false positives nor false negatives are overly prioritized.
- ROC-AUC: Evaluates performance across different classification thresholds, providing insight into how well a model distinguishes between categories.
- Mean Absolute Error (MAE) & Mean Squared Error (MSE): The go-to metrics for regression models, helping refine prediction accuracy.
- Log Loss & Cross-Entropy: Used in probabilistic classification to quantify confidence levels and minimize prediction uncertainty.
2.3. Generalization Overfitting and Underfitting
One of the biggest challenges in AI model development is ensuring that the model generalizes well to new data. A model that performs exceptionally on training data but poorly on unseen data is overfitting—it has memorized patterns instead of learning general rules.
On the other hand, underfitting occurs when a model is too simplistic and fails to capture essential patterns in the data, leading to poor predictive performance. The key to high AI model performance is finding the right balance, ensuring the model learns meaningful patterns without being overly dependent on the training dataset.
By understanding these fundamental principles, businesses can develop AI models that perform well not just in test environments but in real-world applications where stakes are high, and failure is not an option.
3. How to Measure AI Model Performance

Evaluating AI model performance is essential to ensuring its effectiveness in real-world applications. A model that performs well during training but fails in production can lead to costly errors and inefficiencies. To avoid such pitfalls, data scientists and engineers must adopt robust measurement techniques to assess accuracy, generalization, and efficiency.
3.1. Overview of Performance Measurement Techniques
Evaluating AI model performance is a critical step in ensuring that a model functions effectively in real-world applications. Performance measurement is not a one-time task but an ongoing process that spans the entire AI lifecycle from development to deployment and beyond. Proper evaluation helps identify potential weaknesses, optimize model accuracy, and ensure generalization to new data.
The process typically begins with defining the key objectives of the model, selecting relevant metrics, and establishing benchmarks for comparison. Models are tested using structured evaluation methods to assess their accuracy, robustness, and ability to handle unseen data. This involves not only measuring how well a model performs on historical data but also how it adapts to evolving patterns in production environments.
Model performance measurement is an iterative task, requiring continuous monitoring and refinement. In dynamic settings, real-world data shifts can impact predictions, making it crucial to track performance over time. Regular evaluation allows businesses to make informed decisions about retraining, fine-tuning, or even replacing models when necessary. By adopting a systematic approach to performance measurement, organizations can ensure their AI systems remain reliable, efficient, and aligned with business goals.
3.2. Model Validation Techniques
Measuring AI model performance requires a systematic approach rather than just running a few tests to validate reliability across diverse scenarios. Some of the essential techniques include:
- Train-Test Split: The most basic validation method, where the dataset is divided into a training set and a test set to evaluate performance on unseen data.
- Cross-Validation: A more robust technique that involves dividing the dataset into multiple subsets, ensuring that every data point is used for both training and validation at some stage. The most popular form, k-fold cross-validation, divides the dataset into multiple subsets, training the model on some while testing on others. This technique helps mitigate issues related to random variations in training data, producing a more reliable performance estimate.
- Leave-One-Out Validation (LOOCV): A rigorous method where the model is trained on all but one data point and then tested on the excluded data point, providing deep insight into model performance stability.
- Bootstrapping: The technique offers an alternative resampling technique where random subsets of the data are drawn with replacement. This method is particularly useful for estimating confidence intervals in model performance.
- Real-world performance tracking: Beyond dataset splits, models can be evaluated through this method, where deployed models are continuously monitored for accuracy and drift. This helps identify when a model begins to degrade over time due to changing data patterns.
3.3. Tools for Model Evaluation
Several tools can help assess AI model performance:
- Confusion Matrix: Analyzes classification model errors, breaking down true positives, false positives, true negatives, and false negatives.
- Learning Curves: Provides a visual representation of how well a model learns over time, helping detect issues like underfitting or overfitting.
- Calibration Curves: Evaluates how well the model’s predicted probabilities align with actual outcomes, ensuring reliable decision-making.
Expanding further, performance assessment must align with the specific type of AI model being used, whether it’s for classification, regression, clustering, NLP, or computer vision.
4. Performance Evaluation Metrics for Different AI Models
A one-size-fits-all approach does not work because classification, regression, clustering, NLP, and computer vision models all have distinct goals and error considerations. By using the appropriate metrics, organizations can gain a clear understanding of how well their models perform and where improvements are needed.
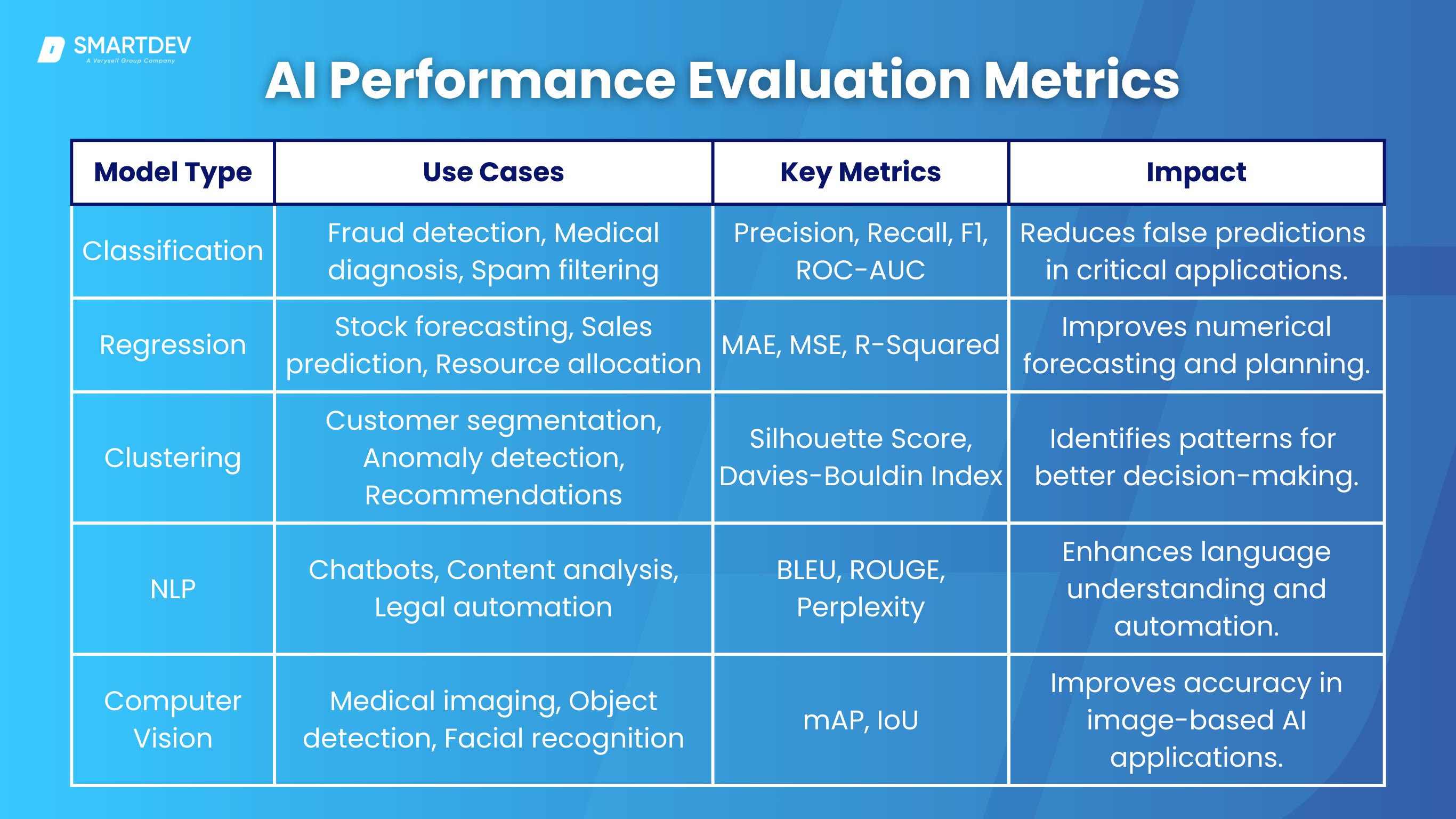
4.1. Classification Models
Classification models are ideal for businesses that need to categorize data into distinct groups. They are widely used in industries like finance, healthcare, and cybersecurity. Banks use classification models for fraud detection, while hospitals rely on them for disease diagnosis and risk assessment.
Metrics such as Precision and Recall are crucial for ensuring minimal false positives and false negatives, making them highly valuable for decision-making in high-stakes environments. F1 Score balances both metrics, while ROC-AUC helps organizations evaluate the model’s trade-off between sensitivity and specificity.
4.2. Regression Models
Regression models are essential for businesses that require continuous value predictions. These models are widely adopted in finance for stock price forecasting, sales prediction in retail, and resource allocation in manufacturing.
Mean Absolute Error (MAE) and Mean Squared Error (MSE) help businesses understand prediction accuracy, while R-Squared determines how well independent variables influence the outcome. These metrics are crucial for organizations that depend on precise numerical forecasting to drive revenue and operational strategies.
4.3. Clustering Models
Clustering models are beneficial for businesses that aim to segment their data into meaningful groups without predefined labels. They are commonly used in marketing for customer segmentation, in cybersecurity for anomaly detection, and in e-commerce for personalized recommendations. Silhouette Score measures how distinct and well-separated clusters are, while Davies-Bouldin Index evaluates cluster compactness. These models enable businesses to derive insights from raw data, helping tailor services to specific customer groups and improving decision-making.
4.4. Natural Language Processing (NLP) Models
NLP models are crucial for businesses that work with large volumes of text data, such as customer service, media, and legal industries. Chatbots, virtual assistants, and automated content analysis rely on NLP for efficiency.
BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) measure translation and summarization accuracy, while Perplexity assesses the fluency of language models. Businesses using NLP can automate customer interactions, extract valuable insights from text data, and improve communication systems
4.5. Computer Vision Models
Computer vision models are essential for businesses that analyze visual data, including healthcare, automotive, and security sectors. Hospitals use these models for medical imaging diagnostics, autonomous vehicle manufacturers rely on them for object detection, and security firms implement them for facial recognition.
Mean Average Precision (mAP) evaluates detection accuracy, while Intersection over Union (IoU) ensures precise localization of detected objects. Companies investing in computer vision can enhance automation, improve safety measures, and streamline image-based decision-making.
5. Best Practices for Optimizing AI Model Performance
5.1. Data Preprocessing Techniques: Cleaning and Normalization
Data preprocessing is the foundation of AI model performance. Cleaning data involves removing duplicates, handling missing values, and correcting inconsistencies, while normalization ensures numerical stability by scaling features to a common range. These steps reduce noise and enhance the model’s ability to detect patterns accurately.
Netflix’s Recommendation System
Netflix processes massive user interaction data to refine recommendations. By cleaning noisy data—such as accidental clicks—and normalizing viewing habits, it improved personalization. This led to better content suggestions, boosting engagement and subscriber retention. This case highlights how effective data preprocessing ensures AI models generate meaningful and reliable insights.

5.2. Feature Engineering and Feature Selection
Feature engineering transforms raw data into meaningful inputs for AI models, while feature selection focuses on retaining only the most relevant features. These techniques improve model accuracy, reduce complexity, and prevent overfitting.
Amazon’s Product Recommendation System
Amazon optimized its recommendation engine by selecting key features like purchase frequency and browsing behavior. Eliminating redundant data improved efficiency, leading to more accurate suggestions and increased customer purchases. This case emphasizes how businesses can optimize AI models by selecting the most impactful data attributes.
Source: Stratoflow
5.3. Hyperparameter Tuning
Hyperparameter tuning involves optimizing settings such as learning rate, batch size, and regularization strength to enhance model performance. Selecting optimal hyperparameters prevents inefficiencies, reduces errors, and ensures models generalize well to new data.
DeepMind’s AlphaGo
DeepMind fine-tuned AlphaGo’s hyperparameters using Bayesian optimization, improving its strategy evaluation. This allowed the AI to surpass human champions, proving the impact of precise tuning on performance. This case demonstrates the transformative impact of optimizing hyperparameters in high-stakes AI applications.

Source: BBC News
5.4. Techniques for Avoiding Overfitting and Underfitting
Overfitting occurs when a model memorizes training data rather than learning generalizable patterns, while underfitting results from an overly simplistic model that fails to capture underlying structures. Addressing these issues involves techniques such as dropout, cross-validation, and increasing dataset diversity.
Facebook’s Facial Recognition Algorithm
Facebook addressed overfitting in DeepFace by applying dropout techniques and dataset augmentation. This improved recognition accuracy across diverse images, enhancing user experience and security. However, the initial is still considered controversial by most people.
Source: The New York TImes
5.5. The Role of Transfer Learning and Pre-Trained Models
Transfer learning leverages pre-trained models to accelerate AI deployment in specialized tasks, reducing the need for extensive labeled data. This approach allows businesses to adapt existing models to new applications with minimal retraining.
OpenAI’s GPT for Customer Support
Companies fine-tune GPT models for industry-specific queries, reducing chatbot training time while improving customer service accuracy. This approach enhances response efficiency and lowers operational costs.

6. Advanced Techniques to Improve Model Performance
Optimizing AI models requires more than just standard tuning—it involves advanced techniques that push the boundaries of what’s possible. Businesses and researchers are constantly exploring innovative methods to refine performance, enhance efficiency, and ensure AI is both scalable and explainable.
6.1. Ensemble Learning: Bagging, Boosting, and Stacking
Ensemble learning improves model performance by combining multiple models to make better predictions. Bagging (Bootstrap Aggregating) reduces variance by training multiple models in parallel and averaging their outputs. Boosting sequentially adjusts weak models to focus on difficult cases, enhancing accuracy. Stacking combines different models and learns the best way to blend their predictions.
6.2. Fine-Tuning and Incremental Learning
Fine-tuning allows models to adjust pre-trained parameters for a new task, while incremental learning ensures AI adapts continuously to new data without starting from scratch. These techniques are critical for industries where data evolves, such as healthcare and autonomous systems.
6.3. Active Learning: Leveraging Unlabeled Data
Active learning reduces the need for vast labeled datasets by selecting the most valuable samples for annotation. Instead of labeling all data, models query human experts for only the most uncertain or impactful examples, saving resources while improving performance.
6.4. Model Distillation for Resource Efficiency
Model distillation transfers knowledge from a large, complex model (teacher) to a smaller, faster model (student), maintaining performance while reducing computational overhead. This technique is critical for deploying AI on edge devices with limited resources.
6.5. Integrating Explainable AI (XAI) for Transparent Performance
As AI systems become more complex, ensuring transparency is crucial. Explainable AI (XAI) techniques, such as SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-agnostic Explanations), help stakeholders understand how models make decisions, fostering trust and compliance.
These advanced techniques showcase how AI can evolve to be more accurate, efficient, and transparent. As industries continue to innovate, integrating these strategies will be key to maximizing AI’s impact while ensuring its responsible deployment.
7. Tools and Platforms for Monitoring and Evaluating Performance
Selecting the right tools for AI model evaluation is crucial for ensuring accuracy, efficiency, and scalability. Below are some of the most widely adopted tools, along with reasons they stand out and real-world examples of their use.
- TensorBoard: Developed by Google, TensorBoard is a powerful visualization tool used to analyze deep learning models. Many AI-driven companies, including Tesla for its autonomous vehicle research, leverage TensorBoard to track neural network training performance in real time.
- MLflow: OpenAI and Airbnb use MLflow to manage the entire lifecycle of AI models, from experimentation to deployment. It helps standardize machine learning processes, making it easier to compare different versions of models and choose the most effective one.
- AWS SageMaker Model Monitor: Amazon uses this tool internally and offers it to enterprises, allowing businesses to continuously track model performance in production environments. Companies like Netflix use SageMaker to maintain the quality of their recommendation algorithms, adapting them dynamically to user behavior changes.
- Google Vertex AI: A fully managed machine learning platform used by major corporations, including Spotify, to build and evaluate AI models. It offers automated hyperparameter tuning and performance tracking, ensuring AI models operate at peak efficiency.
- Scikit-learn Evaluation Modules: A comprehensive suite of evaluation tools for classification, regression, and clustering models. It is widely used by organizations such as Microsoft and academic institutions to benchmark AI models and refine predictive performance.
These tools are widely trusted in various industries because they offer robust, scalable, and insightful ways to evaluate model performance. Selecting the right tool depends on the AI application’s requirements, whether for fraud detection, autonomous driving, medical diagnostics, or personalized recommendations.
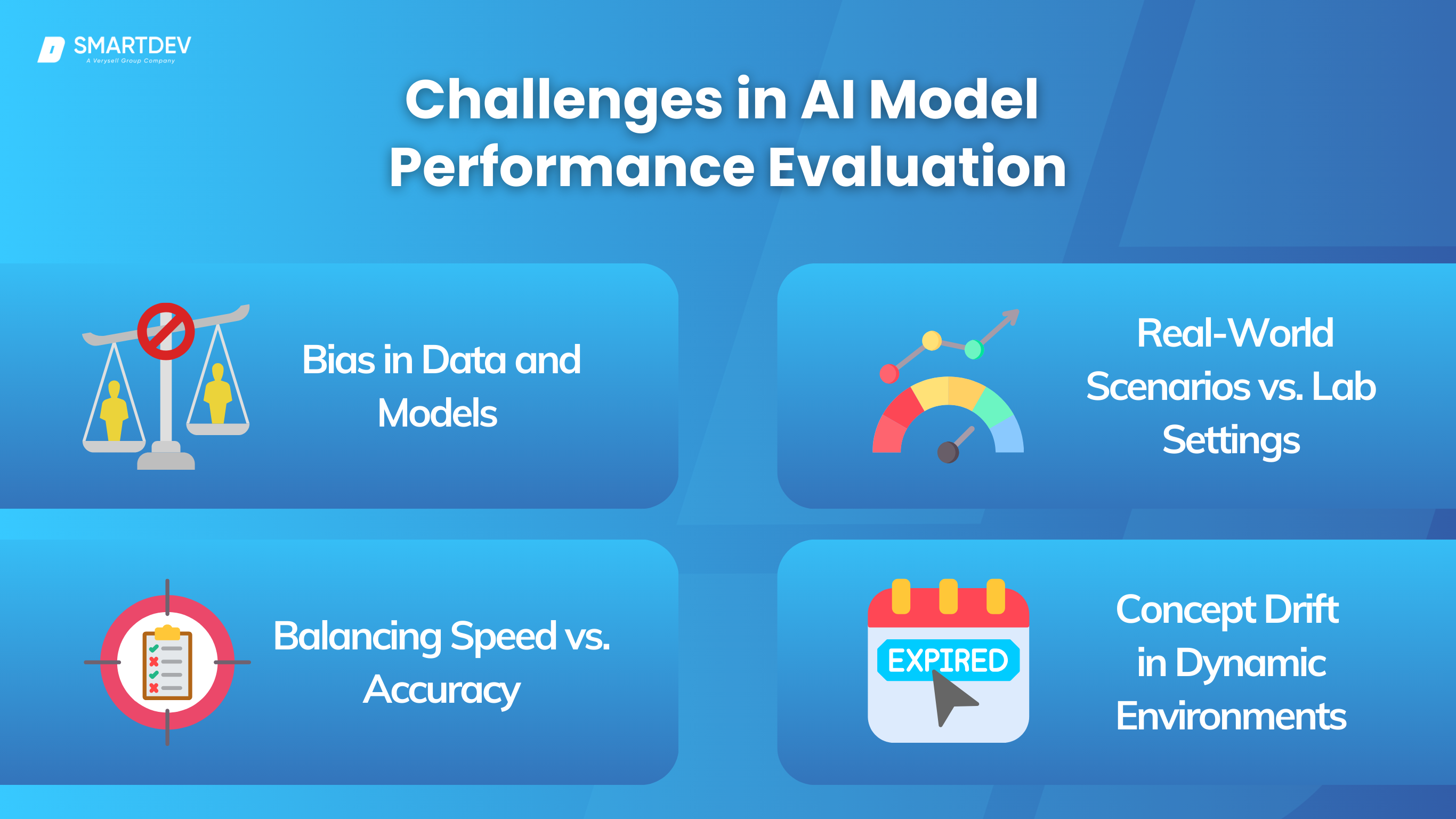
8. Challenges in AI Model Performance Evaluation
Despite advancements in AI, ensuring consistent and reliable model performance remains a challenge. Several key issues can impact the effectiveness of AI systems, particularly when transitioning from controlled environments to real-world applications.
8.1. Bias in Data and Models
AI models are only as good as the data they are trained on. If the dataset contains biases—whether based on demographics, geography, or historical trends—those biases will be reflected in the model’s predictions. This is particularly problematic in applications like hiring, credit scoring, and law enforcement, where biased models can reinforce societal inequalities.
To mitigate bias, organizations should prioritize diverse and representative training datasets. Implementing fairness-aware algorithms, regularly auditing model predictions for biases, and utilizing explainable AI techniques can help reduce unintended discrimination and improve fairness in AI decision-making.
8.2. Performance in Real-World Scenarios vs. Lab Settings
Many AI models achieve high accuracy in controlled testing environments but struggle when deployed in real-world conditions. Differences in data distribution, unexpected user interactions, and environmental variations can cause performance degradation.
To bridge the gap between lab performance and real-world effectiveness, AI models should be continuously tested on diverse real-world data. Implementing robust monitoring systems, regularly retraining models with updated data, and stress-testing AI in unpredictable environments can improve resilience and adaptability.
8.3. Balancing Speed vs. Accuracy
In many AI applications, there is a trade-off between model speed and accuracy. Highly complex models may achieve superior accuracy but require significant computational power, leading to slower inference times. On the other hand, lightweight models may provide faster predictions but sacrifice precision.
Striking a balance between speed and accuracy requires optimizing model architecture, employing model pruning, and leveraging hardware acceleration. Businesses should assess computational trade-offs based on application needs, ensuring that models remain both efficient and precise in time-sensitive environments.
8.4. Dealing with Concept Drift in Dynamic Environments
Concept drift occurs when the statistical properties of incoming data change over time, causing the model’s assumptions to become outdated. This is a common challenge in fields like fraud detection, stock market prediction, and personalized recommendations.
Handling concept drift requires continuous monitoring of incoming data streams, updating models with the latest patterns, and using adaptive learning techniques. Implementing drift detection mechanisms ensures AI systems remain relevant and responsive to changing conditions.
9. Case Studies of AI Model Performance
Real-world applications of AI illustrate how model performance directly impacts outcomes in various industries. By analyzing successful implementations, we can understand how organizations optimize AI to achieve groundbreaking results.
9.1. Healthcare AI: Google’s DeepMind
Google’s DeepMind has significantly advanced medical imaging through AI. Their AI-powered model, trained on thousands of retinal scans, detects eye diseases with accuracy comparable to leading ophthalmologists. The model’s performance was optimized through extensive preprocessing of medical images, fine-tuning hyperparameters, and continual retraining with real-world clinical data.
This AI has enhanced early diagnosis, reduced blindness risks and improved patient outcomes. The key takeaway is that robust data preprocessing and continuous learning are critical in healthcare AI applications.
Source: Silicon UK
9.2. Autonomous Vehicles: Tesla’s Self-Driving AI
Tesla’s Autopilot system is a prime example of AI model performance optimization in autonomous vehicles. The model leverages deep neural networks trained on millions of miles of real-world driving data.
Tesla continuously improves model performance by integrating real-time feedback from its fleet, retraining models to recognize new road conditions, and fine-tuning computer vision algorithms. Despite challenges in unpredictable environments, Tesla’s iterative updates and real-world testing highlight the necessity of adaptive learning in AI-driven transportation.
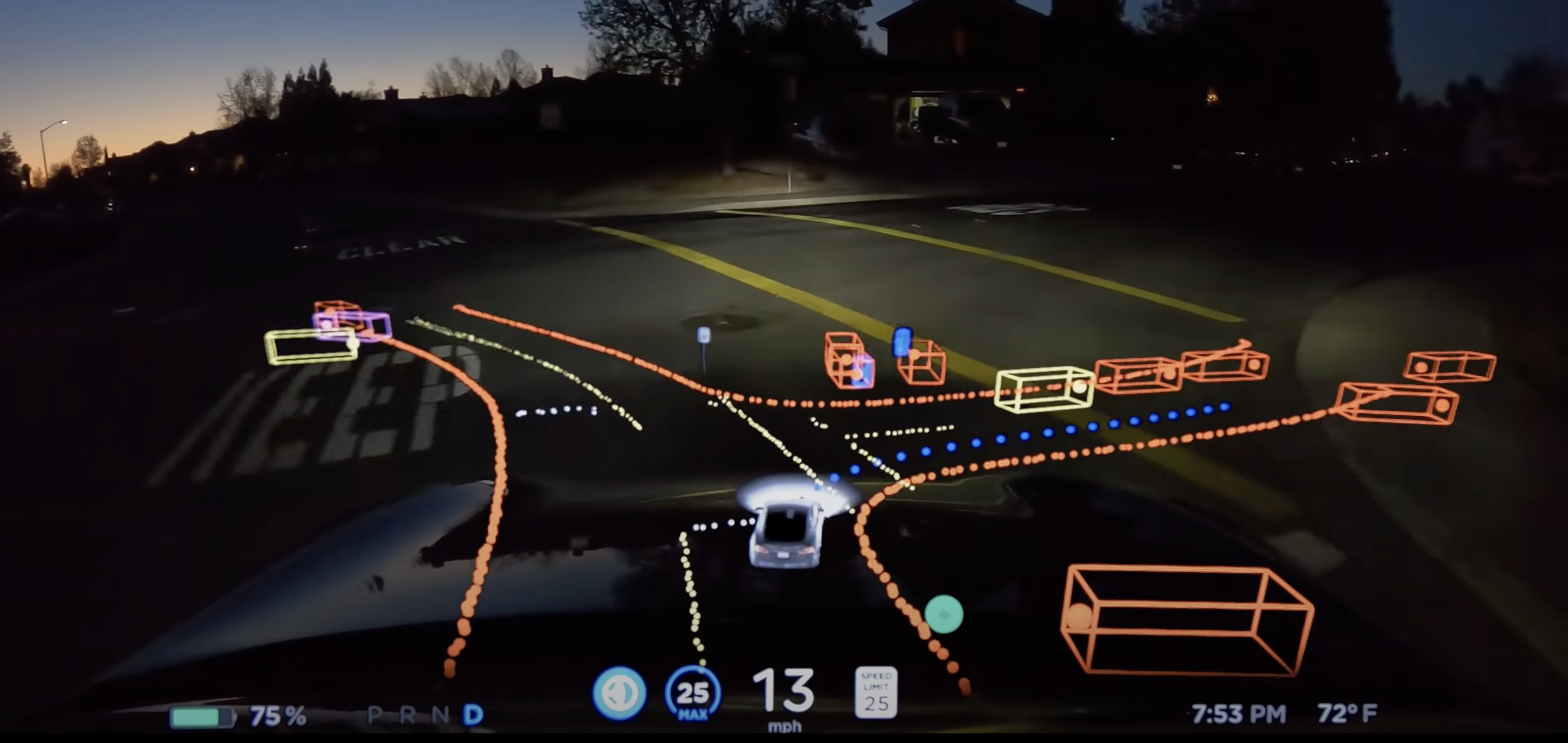
Source: Electrek
9.3. Financial Fraud Detection: Mastercard’s AI-Powered Fraud Prevention
Mastercard employs AI-driven fraud detection models that analyze transaction patterns in real-time to identify suspicious activities. The model’s success comes from ensemble learning techniques, which combine decision trees, neural networks, and anomaly detection algorithms. By continuously monitoring evolving fraud patterns, Mastercard updates its models to prevent financial crimes effectively. This case highlights the importance of dynamic retraining and real-time anomaly detection in financial AI applications.
9.4. Retail Recommendations: Amazon’s Personalization Engine
Amazon’s AI-driven recommendation system uses machine learning models to analyze customer behavior and deliver personalized product suggestions. By employing collaborative filtering and deep learning algorithms, Amazon achieves high recommendation accuracy, leading to increased customer engagement and sales.
The model’s performance improves through A/B testing, continuous optimization, and feature engineering based on real-time shopping behaviors. This case demonstrates how AI model performance directly enhances customer experience and business growth.

Source: Mario Gavira – LinkedIn
9.5. AI in Social Media: Facebook’s Content Moderation AI
Facebook’s AI-powered content moderation system detects harmful and inappropriate content at scale. The model uses a combination of convolutional neural networks (CNNs) and natural language processing (NLP) to analyze images, videos, and text.
Facebook optimizes performance through reinforcement learning, incorporating human feedback to fine-tune AI decision-making. The challenge lies in maintaining accuracy while avoiding false positives, emphasizing the need for explainable AI and constant validation.

Source: WIRED
Key Lessons from These Case Studies
Each of these AI applications highlights key strategies for optimizing model performance:
- Continuous Learning & Retraining: Tesla and Mastercard improve their models by continuously incorporating new data.
- Feature Engineering & Data Optimization: Amazon and Google refine their AI models by selecting the most relevant data features.
- Adaptive AI for Dynamic Environments: Fraud detection and self-driving AI must adjust to ever-changing real-world conditions.
- Human-AI Collaboration: Facebook’s moderation AI benefits from human feedback to reduce bias and improve accuracy.
10. Future Trends in AI Model Performance
10.1. Real-Time Performance Monitoring with AI Operations (AIOps)
AI Operations (AIOps) integrate artificial intelligence into IT operations, enabling real-time monitoring and automated issue resolution. By analyzing vast amounts of operational data, AIOps platforms can detect anomalies, predict potential system failures, and implement corrective actions without human intervention.
In many AIOps architectures, these automated actions are carried out by an AI agent — an autonomous system capable of perceiving its environment, making decisions, and executing tasks without continuous human input.
This proactive approach ensures optimal AI model performance and minimizes downtime. The accelerated adoption of technologies such as generative AI and predictive analytics is redefining IT operations, making AIOps a cornerstone of modern infrastructure management.
10.2. Federated Learning and Performance Optimization
Federated learning is revolutionizing data privacy and AI model performance by enabling models to train on decentralized data sources without aggregating sensitive information. This approach allows AI systems to learn from data stored on local devices or servers, enhancing model accuracy while preserving privacy.
Incorporating federated learning models facilitates data analysis from various sources—both on-premises and cloud—without compromising data security.
10.3. Evolution of Model Performance Metrics with Explainability
As AI systems become integral to decision-making processes, the demand for transparency and trustworthiness has grown. Explainable AI (XAI) addresses this need by providing clear insights into how models arrive at specific conclusions.
In 2025, performance metrics are evolving to include explainability as a key component, ensuring that AI models are not only accurate but also interpretable. This shift enhances user trust and facilitates compliance with regulatory standards.
10.4. AI in Resource-Constrained Environments: Edge AI and TinyML
Deploying AI capabilities in resource-constrained environments has become increasingly feasible with advancements in Edge AI and Tiny Machine Learning (TinyML). These technologies enable on-device data processing with minimal power consumption, making AI applications more efficient and accessible. The field of TinyML is rapidly growing, focusing on low-power, on-device sensor data processing, which is essential for real-time applications like autonomous vehicles and smart home devices.
In summary, the convergence of AIOps, federated learning, explainable AI, and Edge AI is driving the next wave of AI model performance enhancements. These trends emphasize the importance of real-time monitoring, data privacy, transparency, and efficiency in deploying AI solutions across diverse and dynamic environments.
11. Conclusion
AI model performance is not just about achieving high accuracy in a controlled environment—it is about delivering reliable, scalable, and interpretable results in the real world. From healthcare diagnostics and fraud detection to autonomous vehicles and personalized recommendations, AI’s impact depends on how well models are optimized and continuously refined.
Key Takeaways
- AI models must be monitored, retrained, and fine-tuned regularly to maintain accuracy and adapt to evolving data.
- High-quality, well-preprocessed data is crucial for minimizing biases and ensuring meaningful predictions.
- Techniques like ensemble learning, hyperparameter tuning, and explainable AI help optimize performance and build trust.
- Emerging trends like AIOps, federated learning, and Edge AI will continue to shape the efficiency and accessibility of AI models.
At SmartDev, we specialize in helping businesses maximize AI potential through cutting-edge development, optimization, and deployment strategies. Whether you’re looking to refine an existing AI model or build one from the ground up, our team ensures that your AI solutions are efficient, scalable, and aligned with the latest industry trends.
Let’s work together to unlock the full potential of AI for your business. Contact SmartDev today to start your AI transformation!
References:
- AIOps 2025: Redefining IT Operations with AI-Driven Automation Scalable Innovation | Futran Solutions
- 7 Machine Learning Trends to Watch in 2025 | Machine Learning Mastery
- AI & Machine Learning Trends 2025: How Intelligent Systems Shape Our World | Ecosmob
- AI and ML perspective: Performance optimization | Google Cloud
- Scalable, Distributed AI Frameworks: Leveraging Cloud Computing for Enhanced Deep Learning Performance and Efficiency | Cornell University
- Optimizing AI with NVIDIA Tools: Best Practices for Performance and Efficiency | AI Today










