In the ever-evolving landscape of artificial intelligence, ensuring the reliability, fairness, and performance of AI models has become a critical priority. As organizations increasingly depend on AI for decision-making, innovation, and problem-solving, the need for rigorous testing is more crucial than ever.
This blog post dives deep into AI model testing, offering actionable insights, best practices, and industry strategies to help you build models that inspire trust and deliver results. Whether you’re a data scientist, QA engineer, or AI enthusiast, this guide is your roadmap to mastering AI testing.
As you explore the essentials of AI model testing, remember that robust validation is most effective when integrated into a holistic development process. If you’re interested in how organizations are leveraging end-to-end AI-powered software development to deliver reliable, production-ready solutions, you’ll find practical strategies throughout our broader resources.
Introduction to AI Model Testing
 What is AI Model Testing?
What is AI Model Testing?
AI model testing is the systematic process of validating and evaluating an AI model to ensure it performs as expected. It involves assessing various aspects of the model, including:
- Accuracy and precision of predictions
- Bias or unfair outputs across different groups
- Scalability and performance under real-world conditions
Whether it is for machine learning, deep learning, or natural language processing, the motive remains the same – to produce reliable and unbiased results.
Why is Testing Crucial for AI Models?
Testing AI models is essential for several reasons:
- Ensuring Accuracy: Accurate results are the foundation of effective AI systems. Errors in predictions can lead to costly mistakes and loss of user trust.
- Eliminating Bias: Bias in AI can result in unfair outcomes, harming both users and businesses. Rigorous testing helps identify and minimize bias.
- Performance Validation: Models must perform well under various scenarios and handle large-scale datasets efficiently.
- Compliance with Regulations: In industries like healthcare and finance, AI systems must adhere to strict regulatory standards, making AI model testing mandatory.
By testing AI models, businesses can ensure their systems deliver consistent, ethical, and high-quality results, minimizing risks in real-world deployments.
Overview of Current Industry Challenges
Despite its importance, AI model testing faces several challenges:
- Data Quality and Bias: Ensuring high-quality, unbiased data is a significant hurdle, as models trained on flawed data can perpetuate inaccuracies and unfairness.
- Model Complexity and Interpretability: Advanced AI models, such as deep learning networks, often operate as “black boxes,” making it difficult to interpret their decision-making processes and identify errors.
- Lack of Standardized Testing Frameworks: The absence of universally accepted testing standards leads to inconsistencies in evaluation methods, complicating the assessment of AI models across different applications.
- Scalability and Computational Resources: Testing AI models, especially large-scale systems, requires substantial computational power, posing challenges in terms of scalability and resource allocation.
Addressing these challenges is crucial for the development of robust, ethical, and effective AI systems.
Key Principles of AI Model Testing
 Accuracy and Reliability
Accuracy and Reliability
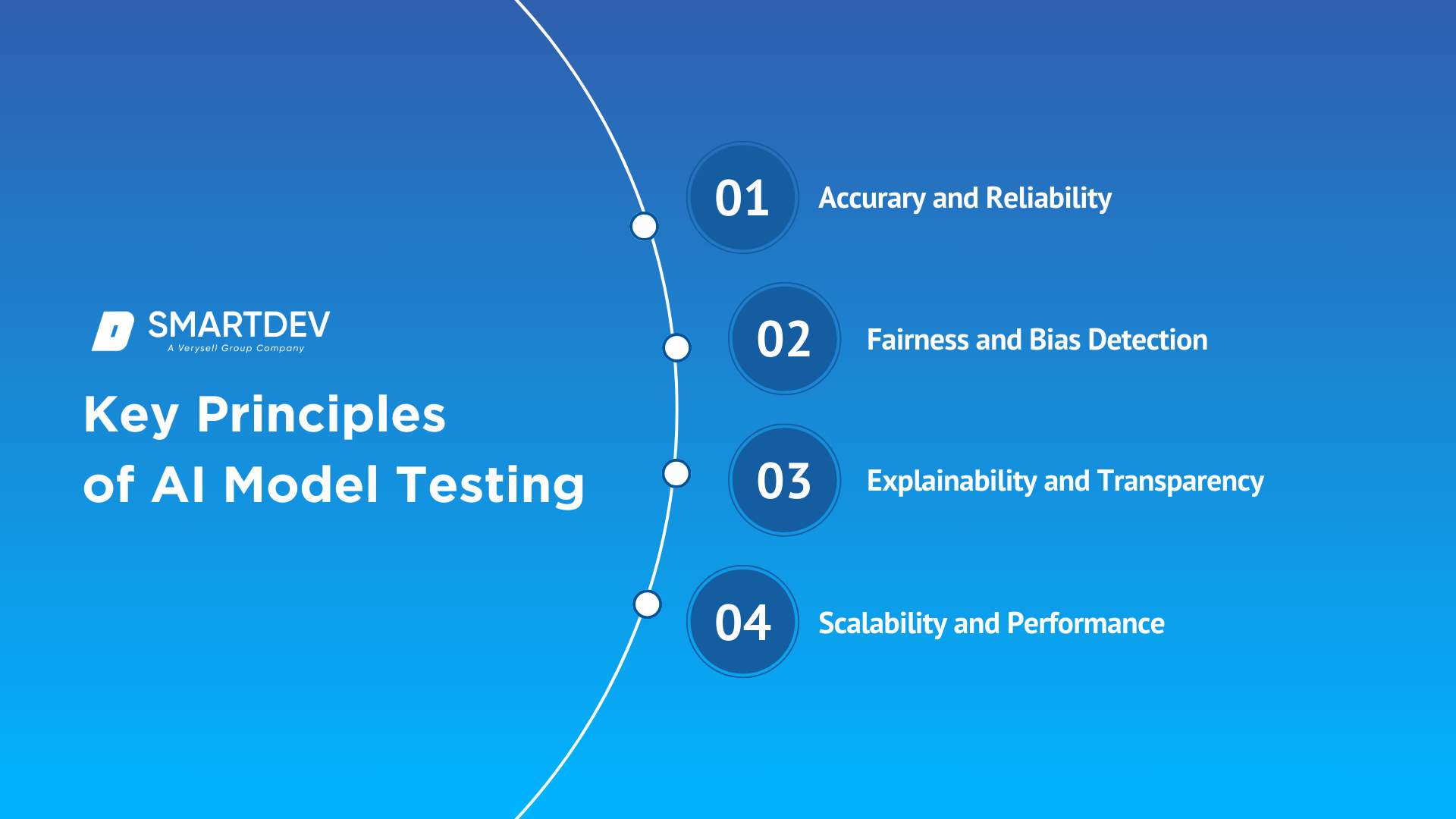 Accuracy and Reliability
Accuracy and ReliabilityAccuracy refers to an AI model’s ability to produce correct outputs, while reliability pertains to its consistency across different datasets and scenarios. Evaluating these aspects involves metrics like precision, recall, and F1 scores to ensure the model meets performance expectations.
Fairness and Bias Detection
AI models should generate fair results on different classes of users. The testing of models shall be done in a way that it could detect and remove biases to avoid unfair treatment/discrimination. Disparate impact analysis and some fairness-aware algorithms are in use to test the fairness of the models for improvement.
Explainability and Transparency
Understanding how an AI model makes decisions is vital for building trust and ensuring compliance with ethical standards. Explainability involves making the model’s internal mechanics interpretable, often through methods like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations).
Scalability and Performance
AI models should maintain performance efficiency as they scale to handle larger datasets and more complex tasks. Testing for scalability involves assessing the model’s ability to process increasing workloads without degradation in speed or accuracy.
Types of AI Models and Their Testing Needs
Machine Learning Models
 Machine Learning Models
Machine Learning ModelsMachine learning encompasses supervised, unsupervised, and reinforcement learning models, each with distinct testing requirements:
- Supervised Learning: Testing focuses on the model’s ability to predict outcomes correctly based on labeled data.
- Unsupervised Learning: Evaluation revolves around the model’s capability of finding hidden patterns or groupings in unlabeled data.
- Reinforcement Learning: Testing checks how well the model learns a strategy to maximize the total rewards through trial and error.
Deep Learning Models
Deep learning models, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), require testing for:
- Model Generalization: Ensuring the model performs well on unseen data.
- Overfitting Detection: Identifying whether the model has learned noise instead of underlying patterns.
- Computational Efficiency: Assessing resource utilization during training and inference.
Natural Language Processing (NLP) Models
NLP models are checked for:
- Language Understanding: Accuracy in understanding and processing human language.
- Contextual Relevance: The ability to keep context in tasks such as translation or summarization.
- Sentiment Analysis: Correct identification and interpretation of sentiments expressed in text.
Generative AI Models
Generative models, including Generative Adversarial Networks (GANs) and Large Language Models (LLMs), are evaluated based on:
- Output Quality: Realism and coherence of generated content.
- Creativity: To generate novel and diverse outputs.
- Ethical Considerations: Not to generate harmful or biased content.
Computer Vision Models
Testing for computer vision models involves:
- Image Recognition Accuracy: Correct identification and classifications of images.
- Object Detection Precision: Ability to accurately locate and identify multiple objects within an image.
- Robustness to Variations: Performance consistency across different lighting, angles, and backgrounds.
AI Model Testing Lifecycle
Pre-Testing: Dataset Preparation and Preprocessing
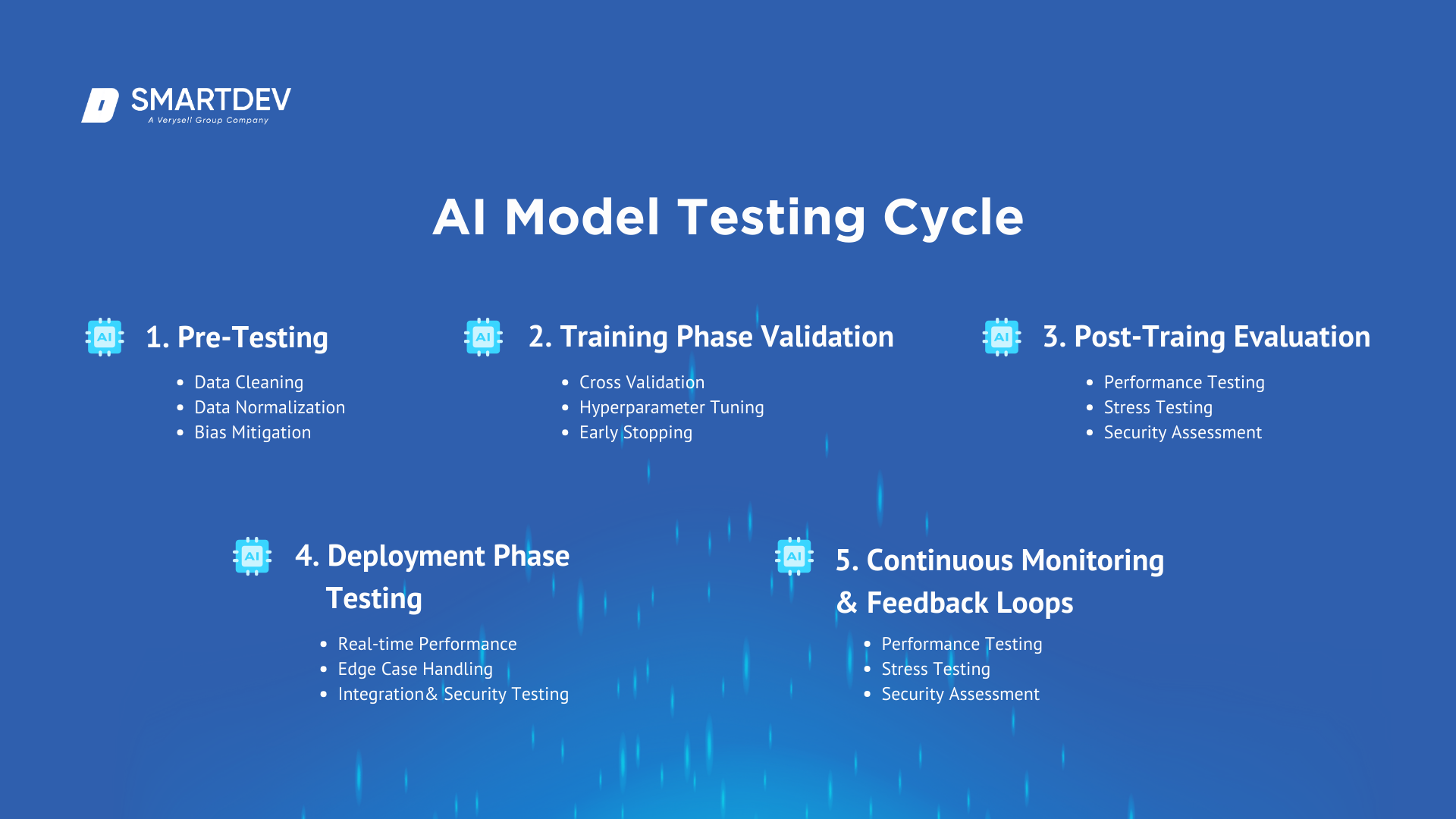 Pre-Testing: Dataset Preparation and Preprocessing
Pre-Testing: Dataset Preparation and PreprocessingThis initial phase involves:
- Data Cleaning: Removing inaccuracies and inconsistencies.
- Data Normalization: Standardizing data formats.
- Bias Mitigation: Ensuring the dataset is representative and fair.
Training Phase Validation
During training, validation includes:
- Cross-Validation: Splitting data to train and validate the model iteratively.
- Hyperparameter Tuning: Adjusting model parameters to optimize performance.
- Early Stopping: Halting training when performance ceases to improve to prevent overfitting.
Post-Training Evaluation
After training, the model undergoes:
- Performance Testing: Assessing accuracy, precision, recall, and other relevant metrics.
- Stress Testing: Evaluating model performance under extreme or unexpected inputs.
- Security Assessment: Identifying vulnerabilities to adversarial attacks.
Deployment Phase Testing
Testing in the deployment phase ensures that AI models fit well into production environments and perform well under real conditions. Key considerations include:
- Real-Time Performance: The ability of the model to process data efficiently and deliver on time is considered. This includes response times and throughput to meet application requirements.
- Edge Case Handling: Identifying and testing unusual or rare scenarios that the model may encounter ensures robustness and prevents unexpected failures.
- Integration Testing: Validating the model’s compatibility with existing systems, databases, and workflows is crucial to ensure smooth operation within the broader application infrastructure.
- Security Testing: This is important to determine the model‘s vulnerability to adversarial attacks or data breaches in order to preserve the integrity and confidentiality of the system.
These testing strategies, if implemented at deployment, will help mitigate risks and guarantee that the AI model works as it should in a live environment.
Continuous Monitoring and Feedback Loops
Continuous monitoring after deployment is very essential to achieve sustainability and improvement in the performance of AI models over time. Key aspects include:
- Performance Metrics Tracking: Tracking key performance indicators such as accuracy, precision, recall, and latency will help in identifying performance degradation and suggesting necessary changes.
- Data Drift Detection: Identifying changes in the distribution of input data that may affect the predictions of the model will keep the model relevant and accurate.
- Automated Retraining Pipelines: Automated processes are to be designed for model retraining with new data that will keep the model updated and fit for the newest evolving pattern.
- User Feedback Integration: Gathering and analyzing user feedback provides insight into model performance, offering opportunities for improving satisfaction and accuracy.
Testing Strategies for AI Models
 By implementing continuous monitoring and establishing feedback loops, organizations can proactively address issues, adapt to changing data landscapes, and ensure sustained AI model performance and reliability.
By implementing continuous monitoring and establishing feedback loops, organizations can proactively address issues, adapt to changing data landscapes, and ensure sustained AI model performance and reliability.
Unit Testing for AI Components
Testing is very component-by-component, or function-wise, in an AI model to ensure that the single entity is correct. This approach tends to find bugs that lead to a more robustness assurance and will save time by catching most bugs early in the system design process. Unit tests may also be automatically generated with available automated testing generation tools.
Integration Testing in AI Pipelines
Integration testing assesses the interaction between combined components within an AI pipeline to ensure they function cohesively. This step is vital for identifying issues that may arise when individual modules are integrated, ensuring seamless data flow and functionality across the system.
System Testing for AI-Based Applications
System testing verifies the complete and integrated AI application for compliance with specified requirements. This test suite evaluates the system under conditions of end-to-end functionality, performance, and reliability to ensure the correct performance of the AI system in real-world scenarios.
Exploratory Testing and Scenario Testing
Exploratory testing involves simultaneous learning, test design, and execution to uncover defects that may not be identified through formal testing methods. This approach is particularly useful in AI systems where unexpected behaviors can emerge. Scenario testing, a subset of exploratory testing, focuses on evaluating the AI model’s performance in specific, real-world situations to ensure robustness and adaptability.
Challenges in Testing AI Models
 Testing AI models presents several challenges that can impact their effectiveness and reliability. Key issues include:
Testing AI models presents several challenges that can impact their effectiveness and reliability. Key issues include:
Data Imbalance and Bias
AI models trained on imbalanced datasets may produce biased outcomes, leading to unfair or inaccurate predictions. Addressing this requires careful data collection and preprocessing to ensure diverse and representative samples. Techniques such as re-sampling, synthetic data generation, and fairness-aware algorithms can help mitigate these biases.
Model Interpretability Issues
Complex AI models, especially deep learning networks, often operate as “black boxes,” making it difficult to understand their decision-making processes. This lack of transparency can hinder trust and compliance with regulatory standards. Implementing explainable AI (XAI) techniques, such as SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations), can enhance interpretability by providing insights into model behavior.
Scalability and High Computational Requirements
As AI models grow in complexity and are applied to larger datasets, they demand significant computational resources, posing scalability challenges. Efficient algorithm design, utilization of high-performance computing infrastructure, and optimization techniques are essential to manage these demands and ensure models can scale effectively.
Lack of Standardized Testing Frameworks
The absence of universally accepted testing frameworks for AI models leads to inconsistencies in evaluation and validation processes. Developing standardized protocols and benchmarks is crucial to ensure comprehensive testing, facilitate comparison across models, and promote best practices in AI development.
Addressing these challenges is vital for developing robust, fair, and reliable AI systems that perform effectively across diverse applications.
Tools and Frameworks for AI Model Testing
 Selecting the appropriate tools and frameworks is essential for effective AI model testing, ensuring accuracy, reliability, and efficiency. Below is an overview of various solutions:
Selecting the appropriate tools and frameworks is essential for effective AI model testing, ensuring accuracy, reliability, and efficiency. Below is an overview of various solutions:
Automated Testing Tools
Automated testing tools leverage AI to enhance the efficiency and coverage of software testing processes. Notable examples include:
- Selenium: An open-source framework for web application testing, supporting multiple browsers and platforms.
- Katalon Studio: An all-in-one test automation tool with AI-driven features for scriptless and script-based testing, supporting mobile, web, API, and desktop testing.
Open-Source Frameworks
Open-source frameworks provide flexibility and community-driven support for AI model testing. Prominent options include:
- TensorFlow Model Analysis (TFMA): A powerful tool that allows developers to evaluate the performance of their machine learning models, providing various metrics to assess model performance.
- DeepChecks: An open-source Python framework for testing machine learning models, offering comprehensive checks for data integrity and model performance.
Commercial Solutions
Commercial AI testing solutions offer advanced features, dedicated support, and integration capabilities. Examples include:
- KaneAI by LambdaTest: An AI-powered smart test assistant for high-speed quality engineering teams that automates various aspects of the testing process, including test case authoring, management, and debugging.
- Applitools: A visual UI testing and monitoring program powered by artificial intelligence, enhancing the efficiency of software quality assurance.
Custom Testing Frameworks
For custom needs, companies can create a custom testing framework for their AI models and applications. This allows them to include unique test scenarios and integrate the same with their existing workflows, ensuring that the testing aligns closely with the organizational needs.
Selecting the appropriate tools and frameworks depends on factors such as project requirements, budget constraints, and the complexity of the AI models involved. A combination of open-source and commercial solutions often provides a balanced approach, leveraging the strengths of both to achieve comprehensive AI model testing.
Advanced Techniques in AI Model Testing
 Implementing advanced techniques in AI model testing is essential to enhance robustness, transparency, and fairness. Key methodologies include:
Implementing advanced techniques in AI model testing is essential to enhance robustness, transparency, and fairness. Key methodologies include:
Adversarial Testing
Adversarial testing involves exposing AI models to intentionally crafted inputs designed to elicit incorrect or unexpected behaviors. This process evaluates a model’s resilience to adversarial attacks and its ability to maintain performance under challenging conditions. By identifying vulnerabilities, developers can enhance model robustness and security.
Synthetic Data Generation for Robustness
Synthetic data generation creates fake datasets that have the same statistical properties as real-world data. This is useful in many scenarios where data sparsity, privacy issues, and coverage of edge cases for testing are concerns. In this regard, techniques like GANs and VAEs are widely used.
Testing Explainability with SHAP and LIME
Explainability testing utilizes tools like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) to interpret AI model decisions. These tools provide insights into feature importance and decision pathways, enhancing transparency and building trust in AI systems. Understanding model behavior is crucial for debugging and ensuring alignment with ethical standards.
Automated Bias Detection Tools
Automated bias detection tools analyze datasets and model outputs to uncover hidden biases that could lead to unfair or discriminatory outcomes. Implementing these tools helps in creating equitable AI systems by ensuring that models do not perpetuate existing biases present in training data. Addressing bias is essential for compliance with ethical guidelines and regulatory standards.
Ethical and Regulatory Considerations
 Ensuring that AI systems operate ethically and comply with regulatory standards is paramount. Key considerations include:
Ensuring that AI systems operate ethically and comply with regulatory standards is paramount. Key considerations include:
Ensuring AI Fairness and Inclusion
Rigorous testing is essential to ensure AI systems are ethical and unbiased. By implementing fairness-aware algorithms and conducting thorough evaluations, developers can mitigate biases and promote inclusivity in AI applications. This approach fosters trust and aligns with societal values.
GDPR and Other Regulatory Frameworks for AI Testing
Adhering to legal standards, such as the General Data Protection Regulation (GDPR), is critical for deploying AI responsibly. Compliance involves ensuring data privacy, obtaining user consent, and maintaining transparency in data processing activities. Understanding and implementing these regulations help in avoiding legal pitfalls and building user trust.
Building Ethical AI Models Through Rigorous Testing
The development of ethical AI models demands attention to rigorous testing across every stage of the development cycle. This includes constant bias policing, transparency in decision making, and adherence to guidelines, both ethical and regulatory. Such diligence ascertains that AI is a force for good and exists within the legal and ethical orbit.
These advanced testing techniques, together with considerations of ethics and regulations, will enable the creation of robust, transparent, fair, and legally valid AI models.
Case Studies: How Companies Test Their AI Models
Real-World Success Stories & SmartDev’ Case Studies and Lessons Learned
AI-Powered Floor Plan Design Platform: SmartDev collaborated with a client to develop an AI-driven platform capable of generating detailed floor plans and 3D home designs within minutes. This innovation revolutionized the real estate and home design industries by enhancing efficiency and accuracy. The project’s success was attributed to rigorous testing phases, including dataset validation, model performance evaluation, and user feedback integration, ensuring the AI system met high standards of reliability and user satisfaction.
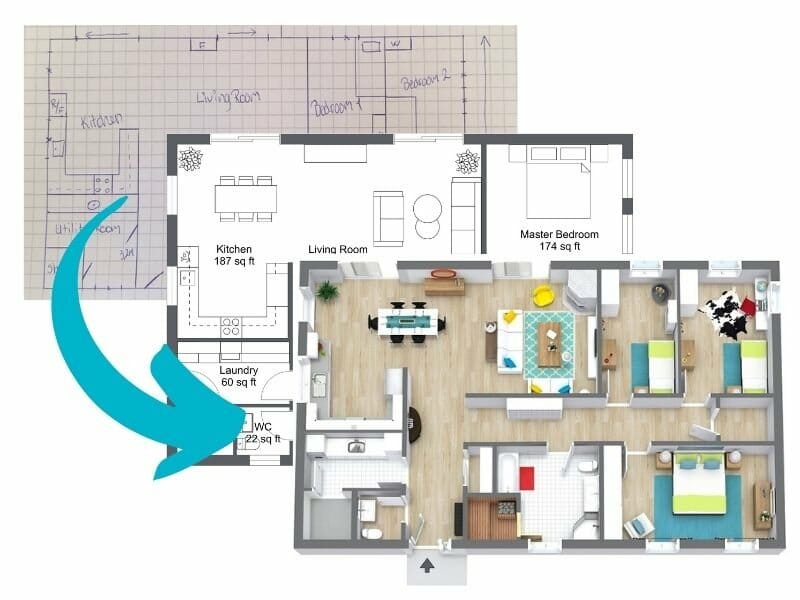
Source: SmartDev – AI Leading the Way in Advanced Floor & 3D House Plan Design
AI-Enhanced Communication Application: In partnership with a leading European toll systems provider, SmartDev developed an AI-powered countdown app that enhanced user communication through personalized avatars and messages. Comprehensive testing strategies, encompassing functional testing, user acceptance testing, and performance assessments, were pivotal in delivering a seamless user experience and achieving project objectives.
Real-World Failures and Lessons Learned
IBM Watson for Oncology: IBM’s AI system, Watson for Oncology, aimed to provide cancer treatment recommendations. However, it faced significant challenges due to reliance on synthetic data and insufficient validation against real clinical scenarios, leading to inaccurate suggestions. This case underscores the necessity of rigorous data validation protocols and the limitations of overreliance on synthetic data in AI model training.

Source: STAT Youtube
Amazon’s Algorithmic Hiring Tool: Amazon developed an AI-driven recruitment tool intended to streamline the hiring process. The system, however, exhibited bias against female candidates, as it was trained predominantly on resumes submitted over a decade, which were largely from male applicants. This failure highlights the critical importance of ensuring diversity and fairness in training datasets to prevent the perpetuation of existing biases in AI models.

Source: The Guardian
These case studies illustrate the critical importance of comprehensive testing, data validation, and ethical considerations in AI model development. Successes are often built on rigorous testing and validation processes, while failures frequently stem from overlooked biases, inadequate data validation, or insufficient real-world scenario testing. Learning from these examples can guide future AI projects toward more reliable and ethical outcomes.
Best Practices for Testing AI Models
 Implementing best practices in AI model testing is crucial for developing reliable and efficient AI systems. Key strategies include:
Implementing best practices in AI model testing is crucial for developing reliable and efficient AI systems. Key strategies include:
Establishing a Comprehensive Testing Strategy
Developing a thorough testing plan that encompasses all stages of the AI model lifecycle—from data collection and preprocessing to deployment and monitoring—is essential. This strategy should define clear objectives, success metrics, and methodologies for various testing phases, ensuring systematic evaluation and validation of the model’s performance.
Collaborating Between Data Scientists and QA Engineers
Effective collaboration between data scientists and QA engineers enhances the testing process. Data scientists bring expertise in model development, while QA engineers contribute insights into testing methodologies and software quality standards. This interdisciplinary approach ensures comprehensive testing coverage and the identification of potential issues from multiple perspectives.
Continuous Integration and Continuous Delivery (CI/CD) for AI
Implementing CI/CD practices in AI development facilitates automated testing and seamless integration of new model versions. CI/CD pipelines enable rapid detection of issues, consistent performance monitoring, and efficient deployment processes, thereby enhancing the reliability and scalability of AI systems.
Leveraging Cloud Platforms for Scalable Testing
Cloud platforms provide scalable resources for testing AI models, accommodating large datasets and complex computations. Testing environments on the cloud are flexible, cost-effective, and can simulate a wide range of scenarios, making AI models more robust and resilient.
Following these best practices guarantees that there is a structured and, therefore, effective way of performing testing on an AI model to come up with high-quality AI solutions that guarantee performance, reliability, and ethical standards.
Future Trends in AI Model Testing
The Role of AI in Automating AI Testing
 The Role of AI in Automating AI Testing
The Role of AI in Automating AI TestingArtificial Intelligence is increasingly being utilized to automate the testing of AI models themselves. This meta-application of AI streamlines the testing process, enabling the identification of defects and optimization opportunities with greater speed and accuracy. For instance, AI-driven tools can automatically generate test cases, detect anomalies, and predict potential failure points, thereby reducing manual effort and improving test coverage.
Continuous Testing for Evolving AI Models
As AI models are frequently updated to adapt to new data and changing requirements, continuous testing has become essential. Implementing Continuous Integration and Continuous Delivery (CI/CD) pipelines ensures that AI models are consistently evaluated for performance, reliability, and compliance throughout their lifecycle. This approach facilitates the early detection of issues, supports rapid iterations, and maintains the robustness of AI systems in dynamic environments.
Emergence of AI Testing Standards and Certifications
Standardized testing frameworks and certifications are underway to establish consistent benchmarks in the evaluation of AI models. Organizations like the International Organization for Standardization and the Institute of Electrical and Electronics Engineers are working out guidelines to make sure AI systems are tested stringently not only for safety and ethics but also for effectiveness. The ISO/IEC JTC 1/SC 42 committee, for instance, focuses on the standardization of technologies related to AI, including AI testing methodologies.
Besides, certifications such as the Certified Tester AI Testing by ISTQB actually equip professionals with the necessary skills to perform effective testing of AI based systems and ensure that industry standards and best practices are met.
These trends reflect a serious effort towards better quality and reliability in AI models through superior testing methodologies, continuous evaluation, and standardized practices.
In conclusion, rigorous testing of AI models is essential to ensure their accuracy, fairness, and performance. By comprehensively understanding the AI model lifecycle, implementing best practices, and utilizing appropriate testing tools, businesses can develop reliable and scalable AI solutions.
Conclusion
Recap of Key Takeaways
 Recap of Key Takeaways
Recap of Key Takeaways- Invest in Robust Testing Strategies: Develop comprehensive testing plans that encompass all stages of the AI model lifecycle, from data preparation to deployment and monitoring. This approach ensures that models perform as intended and can adapt to new data and requirements.
- Combine Automation and Human Expertise for Success: Leverage AI-driven testing tools alongside human judgment to enhance testing efficiency and effectiveness. This combination allows for the identification of nuanced issues that automated tools might miss and ensures a thorough evaluation process.
- Prioritize Ethical AI with Bias Detection Tools: Implement tools and practices that identify and mitigate biases, ensuring AI models operate fairly and ethically. Addressing biases is crucial to prevent discriminatory outcomes and to build trust with users.
The Importance of Investing in Robust AI Testing
Investing in robust AI testing is not merely a technical necessity but a strategic imperative. It ensures that AI systems are reliable, perform optimally, and adhere to ethical standards, thereby safeguarding an organization’s reputation and fostering user trust. Moreover, thorough testing can prevent costly errors and reduce the risk of deploying flawed AI models that could lead to significant operational and legal challenges.
Building a Better Future with Reliable AI
As we move forward in a world that is getting increasingly driven by artificial intelligence, the onus of deploying trusted AI systems lies with businesses and developers. Comprehensive testing strategies using automated tools and human judgment, along with ethics at the forefront, hold the key to building AI solutions that are not only technically correct but also socially beneficial.
Ready to build trust in your AI systems? Start implementing comprehensive testing strategies today to ensure your AI models are accurate, fair, and reliable. Investing in robust AI testing is a step toward a future where AI serves as a beneficial and trusted tool in various facets of life and industry.
References
- Of Sisyphus and Heracles: Challenges in the effective and efficient testing of AI applications | Lamarr Institute
- Fairness and Bias in Artificial Intelligence | GeeksforGeeks
- Common AI Models and When to use them | GeeksforGeeks
- Four Principles of Explainable Artificial Intelligence | National Institute of Standards and Technology
- AI in Production Guide | Azure GitHub
- The Key Steps of AI Model Testing: A Comprehensive Guide | AIUPBEAT
- Automated Support for Unit Test Generation: A Tutorial Book Chapter | ArXiv
- Integration Testing and Unit Testing in the Age of AI | Aviator
- AI Fairness in Data Management and Analytics: A Review on Challenges, Methodologies and Applications | MDPI
- How Ethics, Regulations And Guidelines Can Shape Responsible AI | Forbes











