TL;DR:
1. Introduction to Multimodal AI: A New Dimension of Artificial Intelligence
1.1 Defining Multimodal AI: Integrating Multiple Senses for Enhanced Understanding
Multimodal Artificial Intelligence (AI) represents a significant evolution in the field, moving beyond the traditional focus on single data types to embrace the complexity of real-world information. At its core, multimodal AI involves the processing and integration of data from multiple distinct sources, known as modalities. These modalities can include a diverse range of inputs such as text, images, audio, video, and even sensor data. Unlike conventional AI models that are typically confined to analyzing one type of data at a time, multimodal AI systems are designed to simultaneously ingest and process information from these various streams, allowing for a more detailed and nuanced perception of the environment or situation.
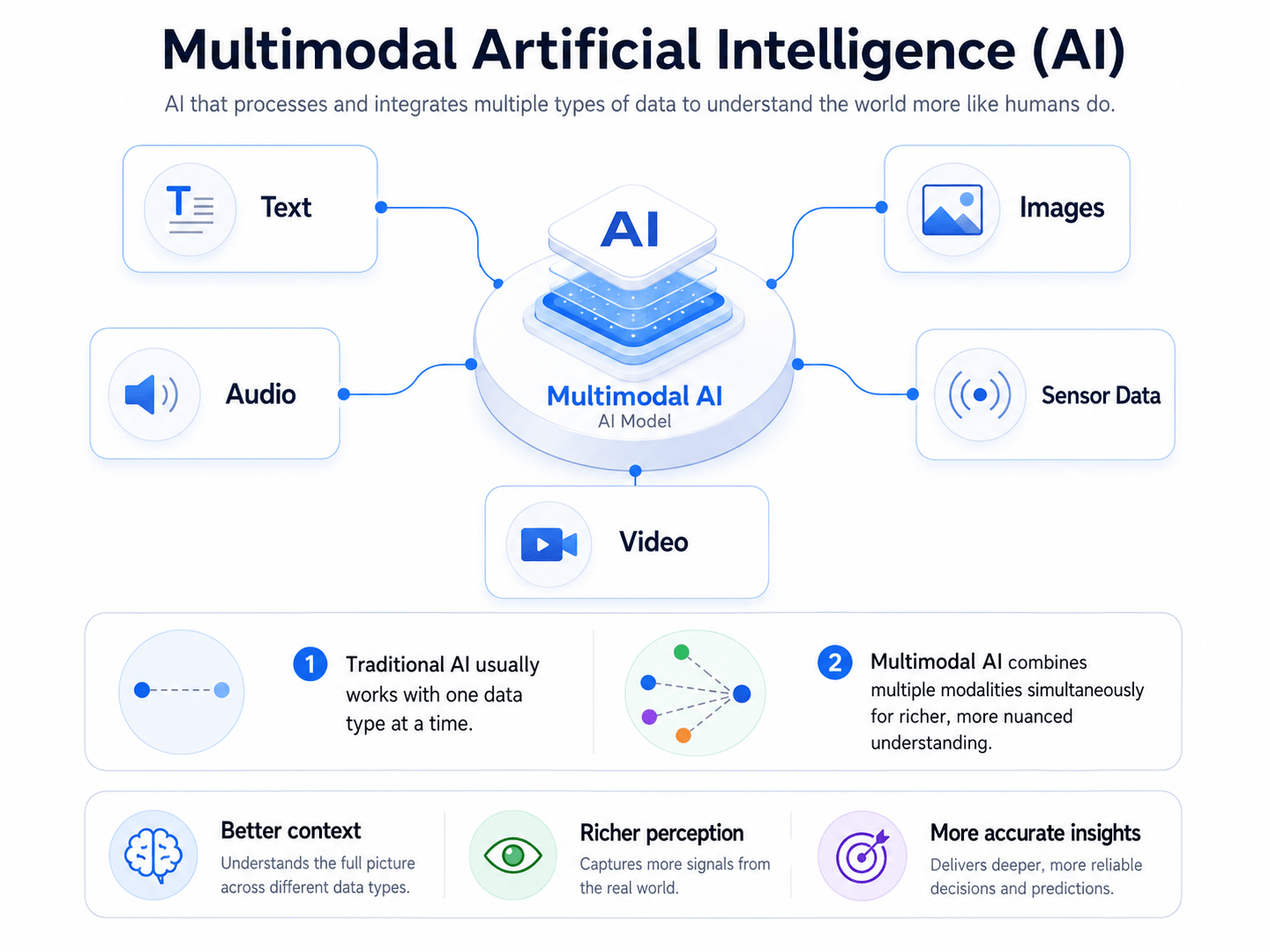 This capability enables these advanced models to generate not only more robust outputs but also outputs that can span across different modalities, such as producing a written recipe from an image of cookies or vice versa. The versatility of multimodal AI extends to allowing users to interact with these systems using virtually any type of content as a prompt, which can then be transformed into a wide array of outputs, not limited to the format of the initial input. This mirrors the innate human approach to understanding the world, where we seamlessly combine sensory inputs like sight, sound, and touch to form a more comprehensive grasp of reality.
This capability enables these advanced models to generate not only more robust outputs but also outputs that can span across different modalities, such as producing a written recipe from an image of cookies or vice versa. The versatility of multimodal AI extends to allowing users to interact with these systems using virtually any type of content as a prompt, which can then be transformed into a wide array of outputs, not limited to the format of the initial input. This mirrors the innate human approach to understanding the world, where we seamlessly combine sensory inputs like sight, sound, and touch to form a more comprehensive grasp of reality.
In essence, one can think of multimodal AI as a sophisticated multilingual translator, capable of comprehending and communicating across various ‘languages’ of data formats, such as textual descriptions, visual elements, or spoken words. By harmonizing the strengths of different AI models, such as Natural Language Processing (NLP) for text, computer vision for images, and speech recognition for audio, multimodal AI achieves a more holistic understanding of the information it processes.
1.2 Beyond Single Data Streams: How Multimodal AI Differs from Traditional AI Models
Traditional AI models, often referred to as unimodal AI, are designed to operate on a single type of data input. For instance, a natural language processing model traditionally deals only with text, while a computer vision model analyzes only images. This focus on a singular data stream inherently limits the context that the AI can understand and utilize for generating responses or making predictions. In stark contrast, multimodal AI distinguishes itself by its ability to integrate multiple data forms concurrently. This simultaneous processing of various modalities, such as text, images, audio, and video, allows multimodal AI to achieve a far more comprehensive understanding of its environment.
Consequently, these models can provide responses that are not only more accurate but also significantly more contextually aware. While unimodal AI models are restricted to producing outputs within the same modality as their input, multimodal AI possesses the flexibility to generate outputs in multiple formats, offering a richer and more versatile interaction. This capability to transcend the limitations of single data types enables multimodal AI to tackle tasks and interpret situations with a level of nuance that is simply unattainable for unimodal systems, which essentially operate with a restricted sensory perception.
1.3 Multimodal AI vs. Unimodal AI: When Should Businesses Use Each Approach?
The evolution of artificial intelligence has moved from systems designed to process a single type of data toward models capable of interpreting text, images, audio, video, and other inputs together. Early unimodal AI applications, such as text-based chatbots, speech-recognition tools, and image-classification systems, performed effectively within narrowly defined domains. However, they often struggled when the information required to complete a task was distributed across multiple data formats—for example, analysing a video while interpreting its spoken dialogue, reviewing a document containing text and visual elements, or responding to a user through both voice and images.
Advances in deep learning, computing infrastructure, and large-scale multimodal datasets have enabled the development of more capable multimodal AI systems. Early multimodal applications focused primarily on areas such as image captioning, audiovisual speech recognition, and multimedia indexing. More recent large multimodal models can connect information across several modalities, allowing users to analyse images, interpret documents, hold voice-based conversations, and generate content through more natural interactions. The emergence of models such as GPT-4V and Google Gemini brought these capabilities into mainstream generative AI, demonstrating how multiple data types can be processed within a more unified system.
The main advantage of multimodal AI is not simply that it accepts more input formats. Its value comes from combining information across those formats to build a more complete understanding of context. A system reviewing an insurance claim, for example, could analyse the claimant’s written description, photographs of the damage, scanned forms, and supporting audio or video evidence. This cross-modal reasoning can improve accuracy, strengthen decision-making, and support automation scenarios that text-only systems cannot handle effectively.
Multimodal AI can also improve human–computer interaction. Users may communicate through the format most appropriate to their situation, whether that means typing a question, speaking naturally, uploading an image, or combining several methods. These flexible interactions can make AI systems feel more intuitive and accessible, particularly for users who may find traditional text-based interfaces difficult to use.
However, multimodal AI is not automatically the best option for every use case. Unimodal AI remains highly effective for focused tasks where the required information exists in a single, consistent data type. A text-only model may be sufficient for summarising structured reports, classifying emails, generating written content, or answering questions from a text knowledge base. In these cases, introducing additional modalities may increase infrastructure requirements, processing costs, testing complexity, and governance risks without creating meaningful business value.
| Decision factor | Unimodal AI | Multimodal AI |
|---|---|---|
| Data inputs | Uses one primary data type, such as text, images, or audio | Combines two or more data types |
| Best suited for | Narrow, clearly defined tasks | Tasks where context is distributed across formats |
| System complexity | Generally simpler to build, test, and maintain | Requires modality integration and more complex architecture |
| Implementation cost | Typically lower | Often higher due to computing and data requirements |
| Evaluation burden | Performance can be assessed within one modality | Requires testing individual modalities and cross-modal reasoning |
| Typical use cases | Email classification, text summarisation, image recognition | Document intelligence, visual inspection, voice assistants, video analysis |
| Key advantage | Efficiency and task-specific performance | Richer context and more comprehensive understanding |
When to Choose Multimodal AI
Choose a multimodal AI approach when a business decision depends on information contained across multiple data types, when users need to interact through different formats, or when a workflow requires the AI system to connect visual, textual, audio, and contextual evidence. Choose unimodal AI when the task is narrow, the input format is consistent, and adding further modalities would create unnecessary cost and operational complexity.
Ultimately, the decision should be based on the problem being solved rather than the sophistication of the technology. Unimodal AI offers an efficient and practical solution for specialised processes, while multimodal AI becomes valuable when richer context, cross-modal reasoning, accessibility, and more natural user experiences are essential.
1.4 Why Combining Modalities Improves Context
Multimodal AI improves contextual understanding by combining complementary information from different data types. A single input often provides only part of the evidence required to interpret a situation accurately. An image may show what an object looks like but not explain its purpose, while a written description may provide specifications without revealing visible damage, layout, or environmental conditions. When these inputs are analysed together, each modality can fill gaps left by the other, helping the system form a more complete interpretation.
This process also helps resolve ambiguity. The same word, sound, image, or gesture can carry different meanings depending on the surrounding context. For example, a product image alone may not indicate whether an item is defective, incorrectly packaged, or simply photographed from an unusual angle. Combining the image with a product description, customer complaint, or order record gives the AI additional signals to distinguish between these possibilities. Similarly, audio can provide spoken content, while video adds facial expressions, physical actions, and environmental cues that clarify what is happening.
Multiple modalities can also provide corroborating evidence. When separate inputs support the same conclusion, the system may have a stronger basis for making a decision. In document processing, for instance, an AI system could compare extracted text with tables, signatures, stamps, and related database records. In healthcare administration, it might review a scanned document alongside a clinical note to identify missing information or inconsistencies, without relying on either source in isolation.
However, more inputs do not automatically produce better results. Additional modalities can introduce irrelevant information, conflicting signals, privacy concerns, and higher processing costs. Poor-quality images, inaccurate transcripts, or outdated metadata may reduce rather than improve reliability. Multimodal systems therefore require careful input selection, validation, alignment, and testing.
A practical way to evaluate multimodal AI is to compare context gain against complexity cost:
| Evaluation factor | Context gain | Complexity cost |
|---|---|---|
| Complementary information | Fills gaps left by one data source | Requires multiple data pipelines |
| Ambiguity resolution | Clarifies uncertain or incomplete inputs | Conflicting signals must be reconciled |
| Evidence corroboration | Strengthens confidence through supporting signals | More extensive validation is required |
| User interaction | Supports text, voice, image, and video inputs | Increases interface and accessibility testing |
| Automation potential | Enables richer end-to-end workflows | Raises infrastructure, governance, and monitoring demands |
2. Multimodal AI Examples: 10 Practical Use Cases
Multimodal AI creates business value by combining information that would otherwise need to be reviewed separately. Instead of processing only text, images, audio, video, or sensor data in isolation, a multimodal system can connect evidence across formats and use that combined context to support classification, analysis, content generation, recommendations, and workflow automation.
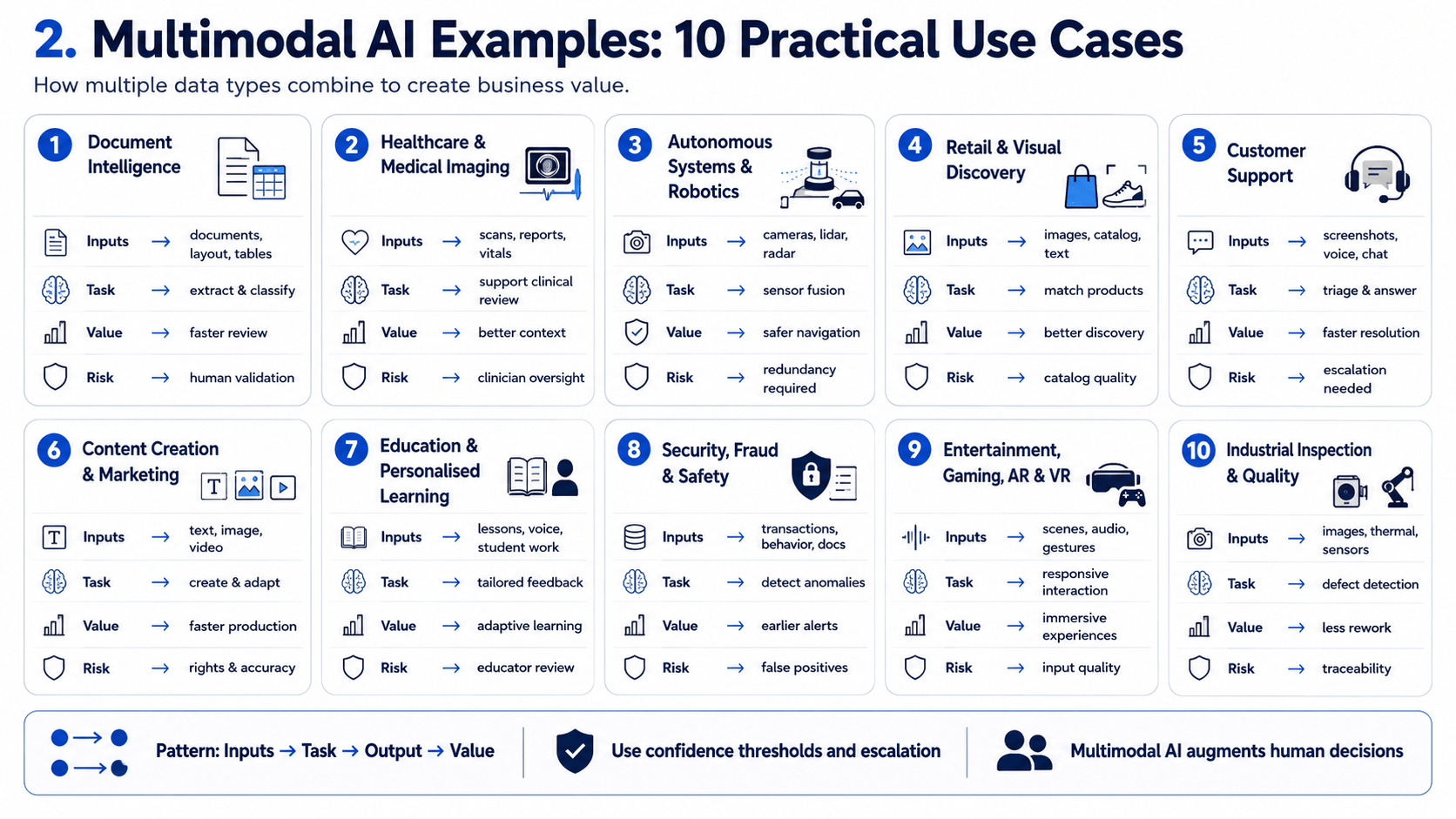 For example, a document-processing system may analyse written text together with tables, signatures, stamps, and page layouts. A customer-support assistant may combine a spoken explanation, an uploaded image, and account information to understand an issue more accurately. In manufacturing, AI may interpret camera footage alongside machine readings and maintenance records to identify potential equipment problems.
For example, a document-processing system may analyse written text together with tables, signatures, stamps, and page layouts. A customer-support assistant may combine a spoken explanation, an uploaded image, and account information to understand an issue more accurately. In manufacturing, AI may interpret camera footage alongside machine readings and maintenance records to identify potential equipment problems.
The following multimodal AI examples show how different industries can apply this technology. Each use case follows a consistent pattern:
Inputs → AI task → Output → Business value → Human control
This structure helps organisations evaluate not only what the technology can do, but also what data it requires, what operational outcome it produces, and where human review remains necessary.
2.1 Multimodal AI Example Matrix
| Use case | Input modalities | AI task | Output | Business value | Principal control or risk |
|---|---|---|---|---|---|
| Document intelligence | Text, page layout, tables, images, signatures | Classify documents, extract fields, interpret structure, and identify inconsistencies | Structured data, document summaries, validation flags | Reduces manual document review and accelerates downstream workflows | Confidence thresholds, access controls, and human validation |
| Multimodal customer support | Voice, text, screenshots, photos, customer records | Understand the issue, retrieve relevant information, and recommend a response | Suggested answer, support summary, or routed case | Improves issue resolution by combining customer explanations with visual evidence | Response approval, personal-data protection, and escalation rules |
| Visual product search | Product image, text query, catalogue metadata | Match visual and semantic characteristics to available products | Ranked product recommendations | Makes product discovery easier when users cannot describe an item precisely | Incorrect matching, catalogue quality, and recommendation bias |
| Healthcare document review | Scanned records, clinical notes, forms, charts, and images | Extract, organise, and compare information across patient documents | Structured patient information and review alerts | Supports faster administrative review and more complete record processing | Clinical oversight, privacy protection, and regulatory compliance |
| Manufacturing quality inspection | Camera images, video, sensor readings, and production specifications | Detect defects and compare observed conditions with expected standards | Defect classification, alerts, and inspection records | Improves consistency and enables earlier identification of production issues | False positives, sensor quality, and human confirmation |
| Driver and vehicle assistance | Cameras, audio, maps, radar or sensor data | Interpret road conditions, driver commands, nearby objects, and navigation context | Alerts, navigation guidance, or assisted actions | Creates more context-aware driving and fleet-management systems | Safety validation, environmental uncertainty, and manual override |
| Retail store analytics | Video, shelf images, inventory data, and transaction records | Identify stock gaps, product placement issues, and customer-flow patterns | Restocking alerts and operational insights | Improves shelf availability and store planning | Customer privacy, image retention, and inaccurate detection |
| Insurance claims assessment | Claim forms, photographs, video, voice notes, and policy data | Compare reported incidents with visual evidence and policy conditions | Claim summary, damage categorisation, and review flags | Accelerates initial assessment and helps prioritise complex claims | Human adjudication, fraud bias, and explainability |
| Robotics and warehouse operations | Video, depth data, spoken or written instructions, and location signals | Recognise objects, understand instructions, plan movements, and adapt to surroundings | Robotic actions, route updates, or exception alerts | Enables safer and more flexible automation in dynamic environments | Physical safety, environmental changes, and emergency controls |
| Media search and content moderation | Text, images, audio, video, and metadata | Index content, detect policy violations, and understand cross-modal meaning | Searchable media records, classifications, or moderation alerts | Improves content discovery and supports scalable platform governance | Context errors, cultural bias, appeals, and human moderation |
The matrix illustrates that multimodal AI is not one specific application. It is an architectural approach used when a workflow depends on evidence distributed across several data types. Its greatest value appears when combining those inputs improves the quality of the decision, reduces fragmented manual review, or enables a task that cannot be completed reliably from one modality alone.
However, organisations should not assume that adding more inputs will automatically improve performance. Each modality creates additional requirements for data integration, security, storage, model evaluation, and operational governance. High-risk applications should therefore include clear confidence thresholds, traceable outputs, escalation procedures, and appropriate human oversight.
2.4 Autonomous Vehicles, Robotics, and Physical-World Systems
Multimodal AI supports autonomous vehicles and robotic systems by combining multiple sources of information about the physical environment. Unlike software applications that work mainly with text or structured data, physical-world systems must continuously interpret objects, movement, distance, location, spoken instructions, and changing operating conditions. No single sensor can capture all of this context reliably, so these systems often depend on sensor fusion.
Sensor fusion is the process of combining signals from cameras, lidar, radar, GPS, maps, telemetry, microphones, and other sensors to create a more complete representation of the environment. Each modality contributes different information: cameras provide high-resolution detail on lane markings, signs, and object classification but can struggle in low light, while radar and lidar continue to estimate distance, speed, and spatial position under conditions such as fog or heavy rain where cameras lose reliability. GPS and maps support localisation and route planning, and telemetry provides information about the vehicle or robot itself.
Multimodal AI supports robotics by integrating visual, spatial, numerical, and language-based inputs so that a system can perceive its surroundings, interpret instructions, plan actions, and respond to changing conditions. A typical physical-world AI workflow may follow this pattern:
Sensor inputs → data synchronisation → multimodal perception → environment modelling → action planning → safety checks → assisted or autonomous action
Autonomous Vehicles
In autonomous and driver-assistance systems, multimodal AI may combine camera feeds with radar, lidar, map data, GPS, and vehicle telemetry. The system can use these inputs to recognise lanes, detect nearby vehicles or pedestrians, estimate movement, and support navigation decisions.
The value of combining modalities becomes clear when one sensor is incomplete or unreliable. A camera may provide detailed visual information but perform less effectively in darkness, glare, fog, or heavy rain. Radar may continue to detect movement and distance under some of these conditions but provide less visual detail; this complementary relationship that cameras reading signs and classifying objects, radar and lidar handling distance and robustness in poor weather is why camera-radar-lidar fusion has become the dominant sensing architecture across major manufacturers’ autonomous-driving stacks.
However, many vehicles described as intelligent or autonomous still operate as assisted or supervised systems. Their capabilities may be limited to particular roads, speeds, weather conditions, or geographic areas. Marketing terms should therefore not be treated as evidence of full autonomy.
Industrial and Service Robotics
In manufacturing, logistics, healthcare facilities, and other controlled environments, robots may combine cameras, depth sensors, force sensors, location signals, and written or spoken instructions. These inputs help robots identify objects, navigate around obstacles, manipulate equipment, and coordinate with human workers.
For example, a warehouse robot may use camera and depth data to identify a package, map information to locate its destination, and telemetry to monitor battery levels and movement. A robotic arm may combine visual recognition with force feedback so that it can adjust its grip when handling items of different shapes or materials.
Language input can add another layer of flexibility. Vision-language-action systems may allow a user to describe a task in natural language while the robot uses visual information to identify the relevant objects and environment. These capabilities remain dependent on controlled testing, clear operating boundaries, and appropriate supervision.
Why Redundancy Matters
In safety-critical systems, multiple inputs do more than improve context. They also provide redundancy. When one sensor fails, becomes obstructed, or produces uncertain data, another modality may provide supporting evidence. This does not eliminate risk, but it can help the system identify disagreement and respond more cautiously.
A controlled system may apply rules such as:
- Continue only when several signals support the same interpretation.
- Reduce speed or pause when sensor confidence falls.
- Request human intervention when inputs conflict.
- Move to a safe state when essential data becomes unavailable.
This failure-mode thinking is essential because multimodal systems can still make mistakes. Sensors may be misaligned, delayed, damaged, or affected by environmental conditions. Models may also encounter unfamiliar objects or situations that were not adequately represented during testing.
For this reason, safety depends not only on model capability but also on robust engineering. Autonomous and robotic systems require scenario-based testing, sensor-health monitoring, fallback procedures, cybersecurity controls, operational boundaries, and clear human override mechanisms. The goal of multimodal AI in physical-world systems is therefore not simply to make machines more autonomous. It is to help them perceive and act with greater contextual awareness while maintaining defined limits, redundancy, and human control wherever the consequences of failure are significant.
2.5 Retail, E-Commerce, and Visual Product Discovery
Multimodal AI can improve retail and e-commerce product discovery by combining product images, catalogue information, natural-language queries, and customer interaction data. Traditional keyword search depends on users describing an item with the same terms used in the product catalogue. This can be difficult when shoppers do not know the product name, style, material, or technical specification. Visual product discovery provides an alternative by allowing users to search with an image and refine the results through text.
Multimodal AI in visual product discovery uses images, product metadata, and natural-language intent together to identify and rank relevant products. Rather than matching only exact keywords, the system can compare visual characteristics such as shape, colour, pattern, style, and product category with catalogue descriptions and structured attributes.
A typical image-to-product matching journey may follow this pattern:
Customer image or screenshot → visual feature analysis → catalogue and metadata matching → natural-language refinement → ranked product results → customer selection
For example, a shopper may upload a photograph of a chair and ask for “a similar design in dark wood under a specific price.” The system can use the image to identify the general product type and visual style, then apply the written constraints to filter the catalogue. The output may include visually similar items, related products, or alternatives that meet the requested size, material, availability, and price criteria.
How Visual Search Differs from Keyword Search
| Factor | Conventional keyword search | Multimodal visual product discovery |
|---|---|---|
| Primary input | Written keywords | Image, text, or both |
| User requirement | Must describe the product accurately | Can show the desired product visually |
| Matching approach | Text and metadata matching | Visual similarity combined with semantic and catalogue matching |
| Best suited for | Known products and precise searches | Style-led, exploratory, or difficult-to-describe products |
| Typical limitation | Vocabulary mismatch between users and catalogue data | Visual similarity may not reflect practical product requirements |
| Key dependency | Search taxonomy and keyword quality | Image quality, metadata accuracy, and catalogue coverage |
Visual search is particularly relevant in categories where appearance influences purchasing decisions, such as fashion, furniture, home décor, beauty, automotive parts, and consumer electronics. A customer can photograph an item in a store, upload a screenshot from social media, or select part of an existing image to find comparable products. Text can then clarify intent through instructions such as “show this in another colour,” “find a smaller version,” or “look for a more affordable alternative.”
Multimodal AI can also support related retail workflows. Product teams may use it to identify missing catalogue attributes, generate draft product descriptions from images and specifications, or group visually similar items. Customer-service teams may combine product photographs, order information, and written complaints to understand issues such as damage, incorrect items, or missing components. In physical stores, shelf images can be analysed alongside inventory data to identify possible stock gaps or misplaced products.
The usefulness of these applications depends heavily on catalogue quality. Product records must contain accurate descriptions, consistent categories, current availability, and reliable attributes. When metadata is incomplete or images are inconsistent, the system may return products that look similar but differ in size, compatibility, material, or intended use.
Customer behaviour data can help refine relevance, but it must be used carefully. Click history, purchases, saved items, and previous searches may support more personalised rankings, yet they can also create repetitive recommendations or reinforce narrow assumptions about user preferences. Retailers therefore need clear privacy controls, appropriate consent mechanisms, and ways for users to reset or adjust personalisation.
Human control remains important in areas such as catalogue management, restricted-product handling, pricing, and customer disputes. Retail teams should also evaluate whether recommendations are accurate across different product categories, image conditions, customer groups, and devices.
The main value of multimodal AI in retail is not simply that customers can search with photographs. It is that the system can connect visual intent with language, product attributes, availability, and commercial rules. When these inputs are aligned, visual product discovery can make search more intuitive and help customers navigate large catalogues. When catalogue information is weak or visual similarity is treated as sufficient evidence, conventional filters and keyword search may remain more reliable.
2.6 Customer Support Using Text, Voice, Images, and Screenshots
Multimodal AI can support customer-service workflows by analysing several forms of customer evidence together, including written messages, voice recordings, screenshots, photographs, documents, chat history, and product or account data. This gives the system more context than a text-only chatbot, particularly when the issue is difficult to explain in words alone. Consumer expectations already reflect this shift: in Zendesk’s 2026 CX Trends research, more than three-quarters of consumers said they would choose a company that lets them share text, images, and video within the same conversation without having to start over.
For example, a customer experiencing a software problem may upload an error screenshot and describe what happened through chat or voice. The AI system can examine the visible error message, interface state, device information, previous conversation, and relevant product documentation before suggesting troubleshooting steps. In retail or insurance, the same pattern could combine a customer’s written explanation with photographs of a damaged product, order details, receipts, and warranty information.
Multimodal AI in visual product discovery uses images, product metadata, and natural-language intent together to identify and rank relevant products. Rather than matching only exact keywords, the system can compare visual characteristics such as shape, colour, pattern, style, and product category with catalogue descriptions and structured attributes. This is no longer a niche behaviour: Google has reported that Google Lens now handles close to 20 billion visual searches a month, around one-fifth of them shopping-related, matched against a shopping graph of tens of billions of product listings.
A typical support workflow may follow this pattern:
Customer message and supporting evidence → multimodal analysis → issue classification → severity and confidence assessment → automated response, agent assistance, or escalation
How Multimodal AI Supports Issue Resolution
A text-only support system depends heavily on the customer describing the problem accurately. Customers may use incorrect terminology, omit important details, or struggle to explain what they see. Images, screenshots, and voice inputs can provide additional evidence that helps clarify the issue.
A screenshot may reveal an error code, missing button, payment status, or incorrect configuration. A product photograph may show visible damage, missing components, or the wrong item. Voice can capture a customer’s explanation while reducing the effort required to type a detailed request. Documents such as invoices, contracts, or installation guides can add further context when the issue depends on specific terms or technical information.
Multimodal AI can use these inputs to perform tasks such as:
- Classifying the issue and identifying the relevant product or service.
- Extracting error codes, order numbers, dates, or other useful details.
- Comparing screenshots with known interface states or troubleshooting documentation.
- Summarising the customer’s explanation and supporting evidence.
- Recommending next steps to the customer or support agent.
- Routing the case to the correct team based on severity and subject matter.
Severity-Based Handoff Model
Not every support request should be handled in the same way. A practical implementation should distinguish between cases that can be automated, cases where AI should assist an agent, and cases that require immediate human escalation.
| Support level | Appropriate use | AI role | Human control |
|---|---|---|---|
| Automate | Common, low-risk, and well-documented issues | Identify the problem and provide approved troubleshooting steps | Customer can request an agent at any time |
| Assist | More complex issues requiring interpretation or account context | Summarise evidence, recommend actions, and prepare a response | Support agent reviews and approves the action |
| Escalate | High-severity, sensitive, uncertain, or regulated cases | Organise evidence and route the case with priority indicators | Qualified staff make the final decision |
Automation may be suitable for issues such as password resets, basic configuration guidance, order-status checks, or common error messages. Agent assistance is more appropriate when the system must interpret several sources of evidence or when the solution affects an account, refund, warranty, or service entitlement. Immediate escalation is necessary when the case involves safety, fraud, legal disputes, sensitive personal information, repeated system failure, or low model confidence.
A support triage decision may therefore consider:
Issue severity + model confidence + customer impact + data sensitivity + required authority
When any of these factors exceed a defined threshold, the system should transfer the case to an authorised human representative rather than continue autonomously.
Business Value and Operational Limits
The principal value of multimodal AI in customer support is its ability to reduce fragmented investigation. Instead of asking customers to repeatedly explain the same issue, the system can organise their message, screenshot, documents, and account context into a single case summary. This may help agents understand the problem more quickly and provide a more consistent response.
However, more inputs can also create additional risks. Screenshots and photographs may contain passwords, payment details, personal messages, addresses, or other sensitive information. Voice recordings may capture background conversations or identifying information unrelated to the request. Organisations therefore need clear consent, secure storage, access controls, retention limits, and methods for masking unnecessary personal data.
Multimodal systems may also misinterpret unclear screenshots, low-quality photographs, accents, background noise, or incomplete account information. Their outputs should therefore include confidence indicators and traceable evidence showing which inputs informed the recommendation.
The objective is not to replace support agents in every interaction. It is to automate predictable requests, assist agents with complex evidence, and escalate cases where human judgement, authority, or empathy is required. This automate–assist–escalate model allows businesses to use multimodal AI while preserving appropriate customer protection and operational accountability.
2.7 Content Creation, Marketing, and Creative Production
Multimodal AI can support content creation and marketing workflows by working across text, images, video, audio, design references, and existing brand assets. Instead of treating each format as a separate production task, a multimodal system can interpret the relationship between them and help teams develop, adapt, and organise content across multiple channels.
For example, a marketing team may provide a campaign brief, brand guidelines, product images, customer research, and examples of previously approved content. The AI system can use these inputs to propose campaign concepts, draft copy, suggest visual directions, create content variations, or adapt a core message for different formats.
The resulting materials may include social posts, website copy, video scripts, storyboards, image concepts, captions, and voice-over drafts. A multimodal content workflow uses AI to interpret and transform text, visual, audio, and video assets while applying relevant brand and campaign context. Human review remains necessary to confirm accuracy, quality, usage rights, and suitability for publication.
A typical workflow may follow this sequence: Creative brief and source assets → multimodal interpretation → concept development → content generation or adaptation → brand and factual review → approval → publication
How Multimodal AI Supports Creative Workflows
Multimodal AI can assist at several stages of content production. During ideation, it can analyse a written brief alongside reference images, audience insights, and previous campaign materials to suggest themes or creative directions. During production, it can generate draft copy, image concepts, video scripts, shot lists, captions, or audio treatments. Besides, for adaptation, it can convert a long-form asset into shorter formats designed for different platforms or audiences.
Common applications include:
- Developing campaign concepts from written and visual references.
- Creating draft copy that reflects an approved tone of voice.
- Generating image or video concepts from product information.
- Producing captions, transcripts, summaries, and subtitles.
- Converting webinars or interviews into articles and social content.
- Adapting one campaign across languages, formats, and channels.
- Creating initial storyboards or scripts for creative teams.
- Organising and tagging large libraries of marketing assets.
A single source asset may also be transformed into several outputs. For example, a recorded webinar could be transcribed, summarised into an article, divided into short video clips, converted into social posts, and supported with suggested captions or visual assets.
Example Multimodal Content Workflow
Consider a product launch campaign requiring a landing page, social content, email copy, and a short promotional video.
The marketing team provides:
- A written product brief.
- Product photographs and demonstration videos.
- Brand guidelines and approved terminology.
- Audience profiles and campaign objectives.
- Previous examples of approved marketing materials.
The multimodal AI system may analyse these inputs and produce:
- A campaign message hierarchy.
- Draft landing-page copy.
- Suggested social-media posts.
- An email sequence.
- A video script and storyboard.
- Alternative headlines and calls to action.
- A list of assets requiring human creation or approval.
The outputs can accelerate early production, but they should remain drafts until reviewed by the relevant content, design, product, legal, or brand stakeholders.
Content Generation vs. Content Governance
The ability to generate content does not establish that the content is accurate, compliant, original, or authorised for commercial use. Marketing teams therefore need governance controls around every source asset and generated output.
| Governance area | Key review question |
|---|---|
| Asset provenance | Where did the source material come from, and can its origin be verified? |
| Usage rights | Does the organisation have permission to use, modify, and publish the asset? |
| Brand alignment | Does the output follow approved visual identity, terminology, and tone? |
| Factual accuracy | Are product claims, statistics, quotations, and descriptions correct? |
| Personal data | Does the content contain identifiable or sensitive information? |
| Disclosure | Is AI-generated or altered content required to be labelled? |
| Approval | Has the appropriate owner reviewed the final asset before publication? |
This review process is particularly important when content includes customer testimonials, public figures, employee images, licensed music, third-party logos, product claims, or regulated information.
Brand Consistency and Human Review
Multimodal AI can use brand guidelines, design examples, and approved content to support consistency. However, it may still produce language that sounds generic, visuals that conflict with brand identity, or adaptations that lose important cultural context.
Human reviewers should therefore assess:
- Whether the content communicates the intended message clearly.
- Whether visual and written elements work together.
- Whether the tone is appropriate for the audience and channel.
- Whether claims are supported by approved evidence.
- Whether the output could create reputational or legal risk.
- Whether local adaptation preserves the original meaning.
Creative judgement is especially important for campaigns involving humour, emotion, cultural references, or sensitive social topics. AI may assist with production, but it does not fully understand brand reputation, audience reaction, or the strategic consequences of publication.
Intellectual Property and Commercial Use
Marketing teams should not assume that an output is commercially usable simply because a platform can generate it. Commercial use may depend on the platform’s terms, the source material, applicable intellectual-property rules, licensing arrangements, and the way the content is produced.
Teams should maintain records of source assets, prompts, model versions, approvals, and modifications where appropriate. They should also avoid uploading confidential brand materials or unreleased product information into systems that have not been approved for such data.
The main value of multimodal AI in content creation is its ability to connect creative inputs and accelerate the movement from idea to draft. It can help teams interpret briefs, reuse existing materials, create format variations, and organise complex production workflows. However, final responsibility for accuracy, originality, brand suitability, rights clearance, and publication should remain with authorised human reviewers.
2.8 Education and Personalised Learning Experiences
Multimodal AI can support education by interpreting different forms of learner input, including written answers, spoken responses, diagrams, handwritten work, images, video, and interaction data from learning platforms. By combining these signals, an AI system can provide feedback that reflects not only a learner’s final answer but also how they approached the task.
For example, a student solving a mathematics problem may submit a handwritten calculation and explain their reasoning aloud. A multimodal learning system could examine the written steps, transcribe the explanation, identify where the reasoning diverged from the expected method, and provide a targeted hint. In language learning, the system might combine a learner’s spoken pronunciation, written vocabulary exercises, and previous lesson history to suggest further practice.
Multimodal AI in education uses textual, visual, spoken, and structured learning data to support instruction, practice, and feedback. It should assist educators and learners rather than independently determine high-stakes academic outcomes.
A typical learner feedback loop may follow this sequence:
Learning activity → student response in one or more formats → multimodal interpretation → feedback or suggested next activity → learner revision → educator review
How Multimodal AI Can Support Learning
Multimodal systems can support several parts of the educational process:
- Explaining concepts through combinations of text, diagrams, audio, and video.
- Interpreting handwritten work or visual problem-solving steps.
- Providing feedback on written and spoken language exercises.
- Converting learning materials into alternative formats.
- Generating practice questions based on course content.
- Summarising lectures, discussions, or uploaded learning resources.
- Helping educators identify areas where learners may require further support.
- Supporting interactive tutoring through text, voice, and visual examples.
The principal advantage is flexibility. Learners may demonstrate understanding in different ways, while educators may present the same concept through several formats. A student who struggles with a long written explanation may benefit from a diagram or spoken walkthrough. Another learner may prefer captions, transcripts, simplified text, or additional visual examples.
Practical Personalised Learning Example
Consider a student completing a science assignment about electrical circuits. The student uploads a photograph of a hand-drawn circuit diagram, submits a short written explanation, and records a voice message describing how current moves through the circuit.
The multimodal AI system may:
- Interpret the components and connections shown in the diagram.
- Analyse the written explanation for key scientific concepts.
- Transcribe and review the spoken reasoning.
- Compare the three inputs to identify consistent understanding or possible misconceptions.
- Provide a targeted hint or suggest an appropriate revision activity.
- Prepare a summary for the teacher when further support may be required.
The AI could point out that the explanation does not match the arrangement shown in the diagram, but the teacher should remain responsible for deciding how the work is assessed and what instructional response is appropriate.
Personalisation Without Over-Automation
Personalised learning does not simply mean generating a different lesson for every student. It can also involve adjusting the pace, explanation format, practice difficulty, or type of feedback based on demonstrated needs.
| Learning need | Possible multimodal support | Required human control |
|---|---|---|
| Difficulty understanding a concept | Provide text, visual, and spoken explanations | Educator confirms instructional suitability |
| Language-learning practice | Analyse written and spoken responses | Teacher reviews consequential assessments |
| Visual or handwritten work | Interpret diagrams, annotations, and calculation steps | Learner can correct misread content |
| Revision planning | Suggest exercises based on previous activity | Educator aligns tasks with curriculum goals |
| Accessibility support | Produce captions, transcripts, descriptions, or alternative formats | Users verify that outputs meet individual needs |
| Progress monitoring | Summarise patterns across learning activities | Educators interpret patterns within broader context |
This approach helps distinguish between low-priority anomalies, cases requiring analyst assistance, and events that may need immediate escalation.
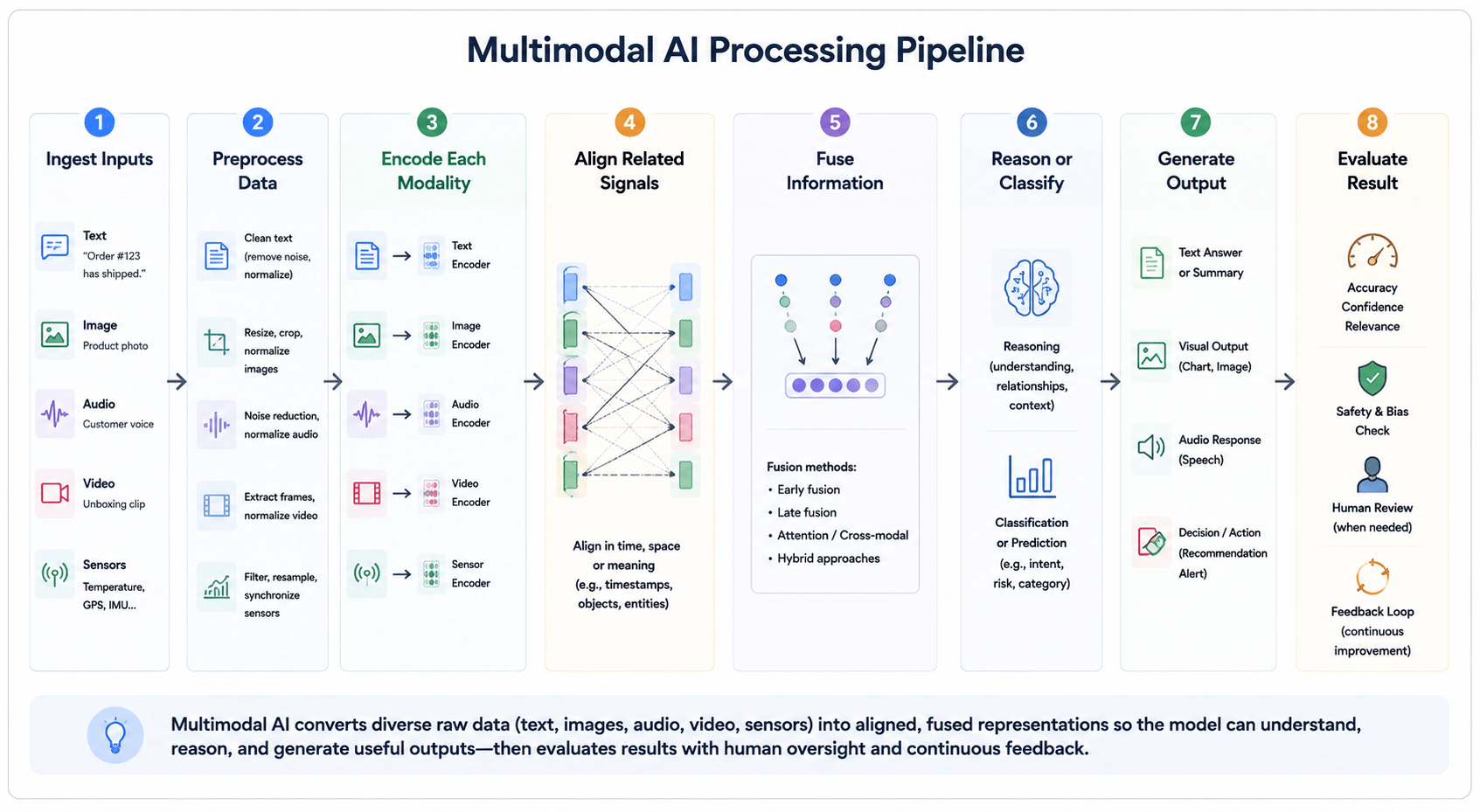 The exact architecture varies by model and task. A document-intelligence system may combine text with page layout and tables, while a robot may process camera feeds, depth measurements, location data, and language instructions in real time. Despite these differences, implementation quality generally depends on three factors: whether the input data is reliable, whether the modalities are aligned correctly, and whether the final system is evaluated under realistic operating conditions.
The exact architecture varies by model and task. A document-intelligence system may combine text with page layout and tables, while a robot may process camera feeds, depth measurements, location data, and language instructions in real time. Despite these differences, implementation quality generally depends on three factors: whether the input data is reliable, whether the modalities are aligned correctly, and whether the final system is evaluated under realistic operating conditions.| Pipeline stage | Main purpose | Example failure |
|---|---|---|
| Ingestion | Receive and identify inputs | A supporting file is missing or incorrectly linked |
| Preprocessing | Clean and standardise data | A poor transcript changes the meaning of a spoken statement |
| Encoding | Represent each modality numerically | The encoder fails to capture domain-specific features |
| Alignment | Connect corresponding information | A sentence is linked to the wrong video frame |
| Fusion | Combine complementary signals | One modality overwhelms more reliable evidence |
| Reasoning | Interpret relationships and perform the task | The model draws an unsupported conclusion |
| Output | Produce a usable result or action | A confident answer is shown without uncertainty indicators |
| Evaluation | Test performance and operational reliability | Only ideal examples are tested before deployment |
This pipeline is a general model rather than a universal technical design. Some systems combine stages, use external tools, retrieve information from enterprise databases, or rely on several specialised models instead of one end-to-end model.
3.2 How Models Align Text, Images, Audio, Video, and Sensor Data
Alignment is the process of determining which information from one modality corresponds to information in another. It allows the model to understand that a sentence describes a particular image, that a sound occurred during a specific video moment, or that a sensor measurement relates to a particular machine or location.
Without reliable alignment, a multimodal system may combine accurate inputs in the wrong context. This can produce outputs that appear coherent because the individual pieces of information are valid, even though the relationship between them is not.
Alignment generally occurs in three forms: temporal, spatial, and semantic alignment.
Temporal Alignment
Temporal alignment connects events that occur at the same or related times. It is especially important for audio, video, telemetry, and other streaming data.
Examples include:
- Matching spoken words with the correct video frames.
- Connecting a machine vibration alert with footage from the same moment.
- Synchronising GPS position with camera and radar data.
- Linking a customer’s spoken explanation to the screen action being demonstrated.
Timestamps are often used to support this process, but timestamps may be missing, delayed, or generated by systems with different clocks. Real-time applications therefore require mechanisms for synchronisation, buffering, and latency management.
Spatial Alignment
Spatial alignment identifies where elements are located and how they relate within a visual or physical environment.
Examples include:
- Connecting a label with the correct field in a form.
- Matching a written annotation to a region in a medical image.
- Determining which object a user is pointing toward.
- Relating radar or lidar measurements to objects detected by a camera.
- Identifying which table header applies to a specific value.
Spatial relationships may be represented through coordinates, bounding boxes, page layouts, depth measurements, or learned visual features.
Semantic Alignment
Semantic alignment connects information that has related meaning even when it does not share the same time or physical location.
For example:
- Matching the phrase “red leather chair” with a visually similar catalogue item.
- Connecting a written product complaint with a photograph of the fault.
- Relating a question to the relevant chart or document section.
- Comparing a clinical note with information shown in a scan.
- Associating a spoken instruction with an available robotic action.
Models may learn semantic relationships from paired datasets containing text and images, audio and transcripts, or other combinations. Similar concepts are represented closer together within a shared embedding space.
A Misalignment Failure Example
Consider a warehouse-monitoring system that receives video, equipment telemetry, and maintenance notes. A temperature alert is recorded at 10:05, while the camera system operates with a two-minute timestamp delay. If the system aligns the alert with footage labelled 10:05 rather than the actual moment at 10:03, it may associate the event with the wrong machine activity.
The AI could then produce a plausible explanation based on unrelated footage. The error does not come from inaccurate video or faulty sensor data. It comes from incorrectly connecting two valid inputs. This illustrates why multimodal evaluation must test the relationships between modalities, not only the quality of each source independently.
How Alignment Is Implemented
Alignment methods vary depending on the application:
| Alignment method | How it works | Typical use |
|---|---|---|
| Timestamps | Connects inputs recorded at the same time | Audio-video, telemetry, monitoring |
| Spatial coordinates | Links information by physical or visual location | Documents, robotics, medical images |
| Metadata | Uses file IDs, device IDs, user IDs, or source records | Enterprise workflows and data platforms |
| Paired examples | Learns relationships from labelled modality pairs | Image–text and audio–text models |
| Embedding similarity | Matches inputs with related semantic representations | Search, retrieval, and recommendations |
| Cross-modal attention | Learns which parts of one input relate to another | Vision-language and multimodal generative models |
| Human annotation | Uses manually defined correspondences | Specialist and high-accuracy applications |
In production systems, alignment is often a data-engineering challenge as much as a model-design challenge. Reliable identifiers, timestamps, metadata, and source governance may be as important as the neural architecture.
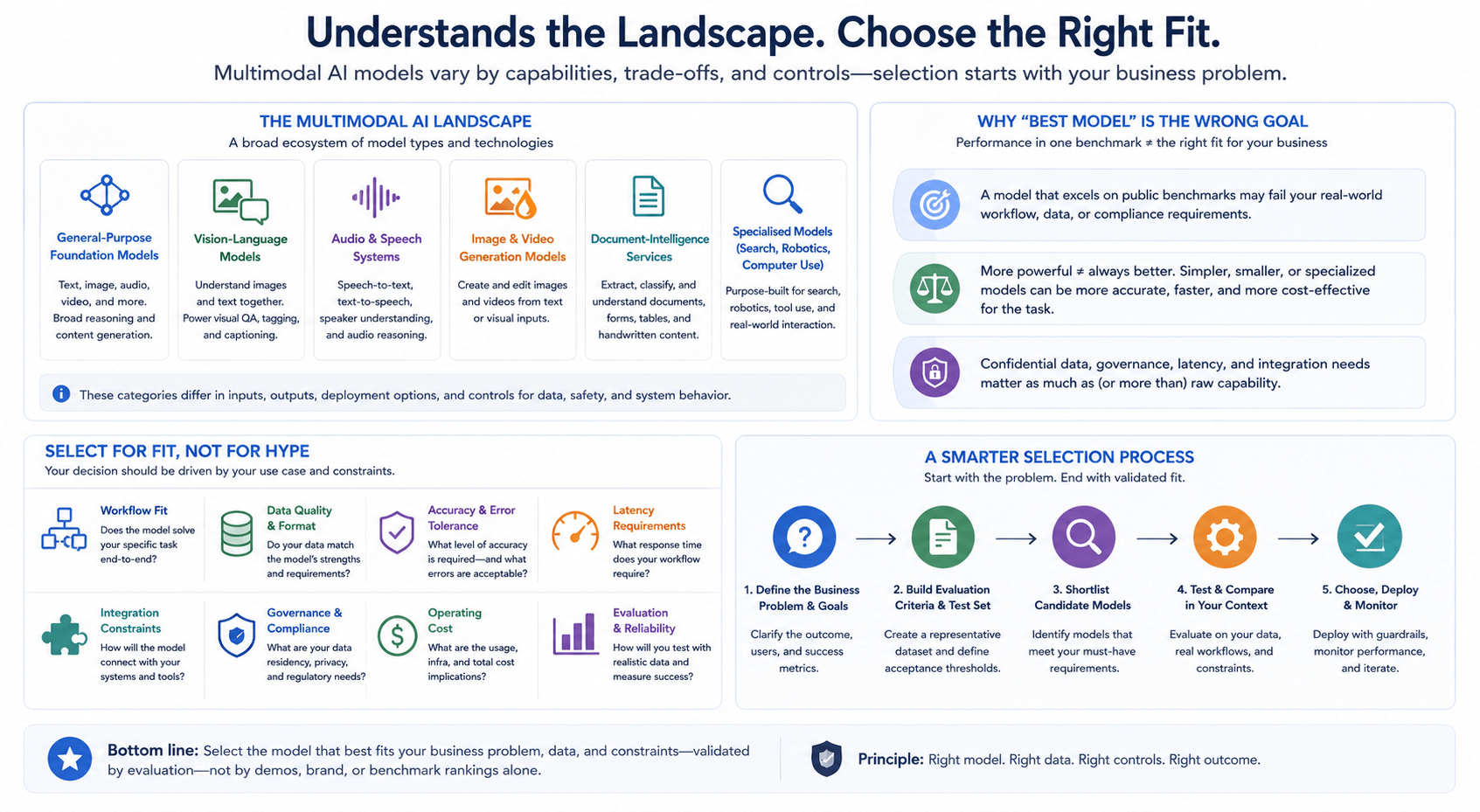 For business teams, the objective should not be to identify a universally “best” multimodal AI model. Model selection depends on the workflow, the quality and format of available data, acceptable error levels, latency requirements, integration constraints, governance obligations, and operating cost.
For business teams, the objective should not be to identify a universally “best” multimodal AI model. Model selection depends on the workflow, the quality and format of available data, acceptable error levels, latency requirements, integration constraints, governance obligations, and operating cost.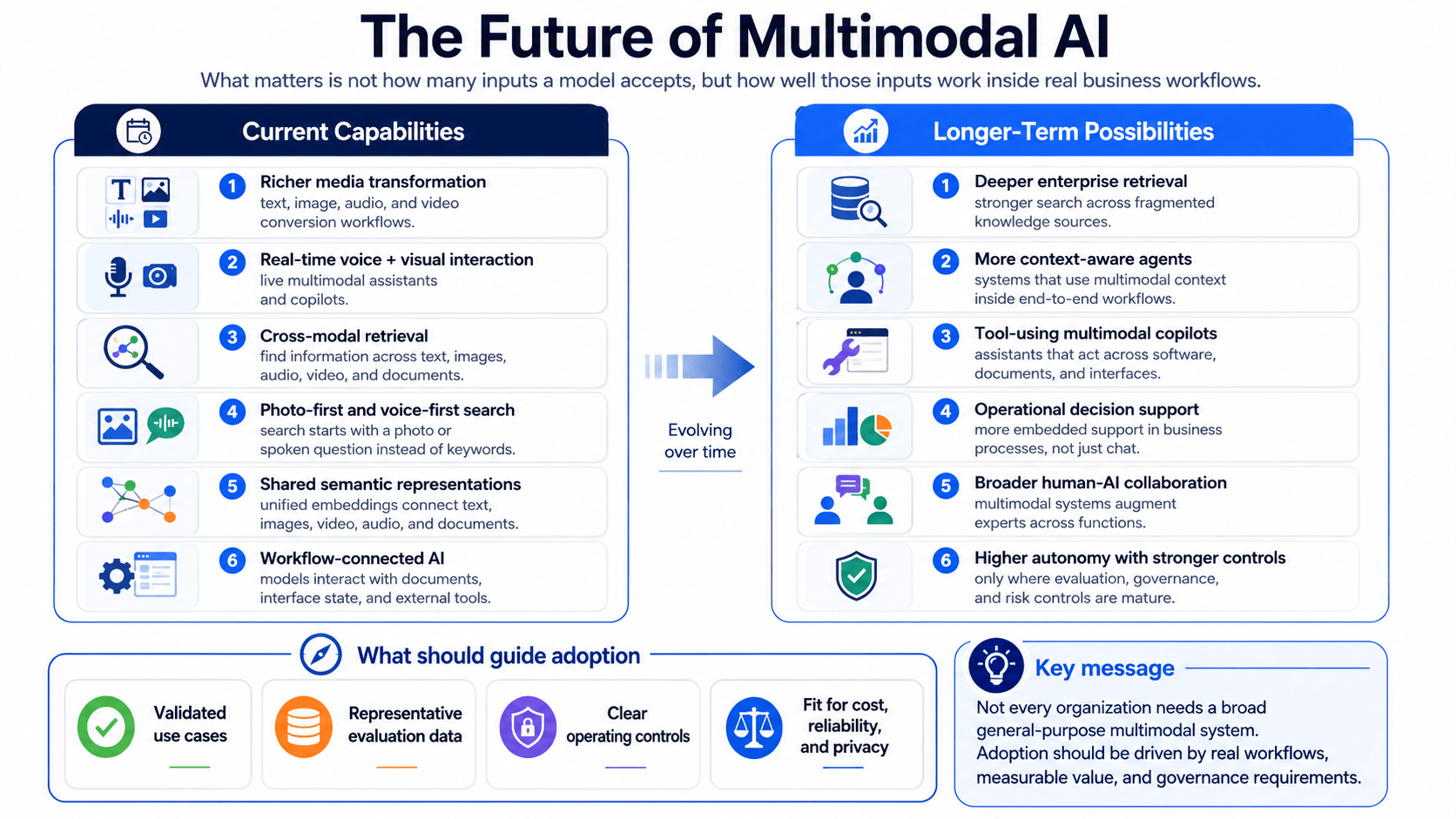 Recent platform developments indicate several clear directions. Multimodal models are supporting richer media transformation, real-time voice and visual interaction, cross-modal retrieval, and search experiences that begin with photographs or spoken questions rather than keywords. Google has also introduced unified multimodal embeddings that map text, images, video, audio, and documents into a shared semantic space, illustrating how multimodality is expanding from generation into enterprise search and retrieval.
Recent platform developments indicate several clear directions. Multimodal models are supporting richer media transformation, real-time voice and visual interaction, cross-modal retrieval, and search experiences that begin with photographs or spoken questions rather than keywords. Google has also introduced unified multimodal embeddings that map text, images, video, audio, and documents into a shared semantic space, illustrating how multimodality is expanding from generation into enterprise search and retrieval.









