
Enterprise knowledge management is broken —Fortune 500 companies lose $31.5 billion yearly while employees waste 20% of their time searching for information, and most companies don’t even realize it. While your teams waste 2.5 hours daily searching for information across disconnected systems, forward-thinking organizations are implementing RAG (Retrieval-Augmented Generation) systems that make knowledge instantly accessible and contextually relevant.
The problem isn’t just inefficiency—it’s the cascade of errors that follow. When employees can’t find accurate information quickly, they make decisions based on outdated data, duplicate efforts, and create inconsistent outputs that damage customer experience and operational effectiveness.
This article shows you exactly how to implement enterprise RAG systems that don’t just improve knowledge access, but do it with proven testing methodologies that reduce post-release issues. You’ll learn the architecture decisions, implementation timeline, and testing strategies that separate successful deployments from expensive failures.
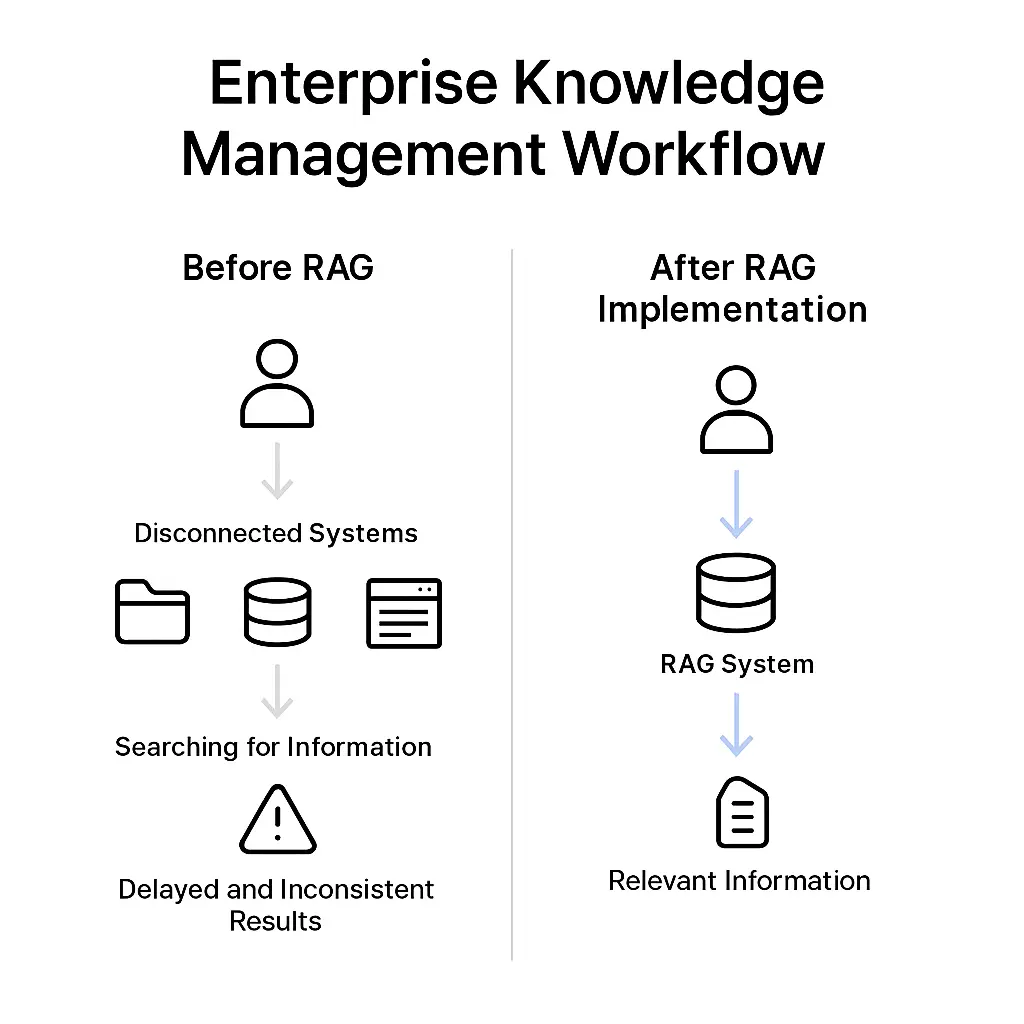
Fig.1 Enterprise knowledge management workflow comparison – before and after RAG implementation
What Are RAG Systems and Why Your Enterprise Actually Needs Them
RAG systems solve enterprise knowledge management by combining information retrieval with generative AI to create contextually accurate responses from your existing knowledge bases. Unlike traditional search that relies on keyword matching, RAG understands context and intent, making it possible to find relevant information even when users don’t know the exact terminology.
The core architecture consists of three components that work together:
- Vector database that stores document embeddings (mathematical representations of your content)
- Retrieval mechanism that finds semantically similar information based on user queries
- Generation model that synthesizes coherent responses from the retrieved content
Here’s what actually happens in practice: instead of your sales team spending 20 minutes searching through multiple systems to find pricing guidelines for a specific customer scenario, they ask a natural language question and get accurate, sourced information in under 10 seconds. The system doesn’t just return documents—it provides specific answers with citations to the original sources.
Over 90% of organizations use cloud technologies, which creates the foundational infrastructure necessary for RAG’s scalability and flexibility. This widespread cloud adoption means your enterprise likely already has the basic infrastructure components needed for RAG implementation.
Business Impact Beyond Convenience
Well-implemented RAG systems deliver measurable improvements in enterprise operations. Based on implementations across various industries, organizations typically see:
- Faster information retrieval through semantic understanding
- Reduced redundant documentation through centralized knowledge access
- Improved knowledge worker productivity through streamlined workflows
- Decreased training costs through consistent information delivery
But here’s the critical part most implementations miss: RAG systems reduce compliance risks by ensuring consistent information delivery and maintaining audit trails for knowledge access patterns. This systematic approach to knowledge management prevents costly errors from outdated or misinterpreted information—errors that often don’t surface until after deployment.
How to Design RAG Architecture That Actually Scales for Enterprise Use
Your vector database choice determines whether your RAG system handles enterprise scale or becomes a performance bottleneck within months. Here’s how the major options compare:
Vector Database Options
Pinecone provides managed scaling, which means less operational overhead but higher costs per query. Check current Pinecone pricing for your specific volume requirements.
Weaviate offers hybrid search capabilities that combine dense vector search with traditional keyword search—particularly valuable for technical content with specific terminology.
Chroma delivers cost-effective self-hosting options but requires more in-house expertise for maintenance and scaling.
The decision comes down to your specific requirements: if you need to handle millions of embeddings with minimal operational complexity, Pinecone’s managed service makes sense despite higher costs. If your content includes technical terms and proper nouns that benefit from exact keyword matching, Weaviate’s hybrid approach delivers better accuracy.
Embedding Strategy Matters More Than You Think
OpenAI’s text-embedding-ada-002 works well for general business content, but specialized industries benefit from domain-specific models. BioBERT provides better accuracy for medical and pharmaceutical content, while FinBERT handles financial terminology more effectively. The wrong embedding model can reduce retrieval accuracy, which compounds into poor user experience and reduced adoption.
Document Preprocessing Creates Quality Foundation
Your preprocessing pipeline needs systematic text extraction, metadata preservation, and quality filtering. Remove redundant content early—duplicate information confuses vector search and leads to inconsistent responses. Normalize formatting across document types and extract structured data elements like tables and lists for separate processing.
Chunking strategy directly impacts both retrieval precision and response quality. Chunk documents into 200-500 token segments with 50-100 token overlaps to maintain context while ensuring retrieval precision. Use semantic chunking for complex documents, breaking content at logical boundaries like section headers and paragraph breaks rather than arbitrary character limits.
Here’s a practical example: a 10-page technical specification document should be chunked at section boundaries, with each chunk containing enough context to be understood independently. Include the document title and section header in each chunk’s metadata so responses can provide proper attribution.
Hybrid Search Implementation
Hybrid search implementation combines dense vector search with sparse keyword search to achieve better retrieval accuracy than either method alone. Use a weighted scoring system that favors semantic similarity while preserving exact keyword matches for technical terms and proper nouns.
Query enhancement techniques improve retrieval recall for complex enterprise queries. Implement query expansion using synonyms, acronym resolution, and context injection from conversation history. These enhancements are particularly valuable for enterprise environments where users often use different terminology than the source documents.
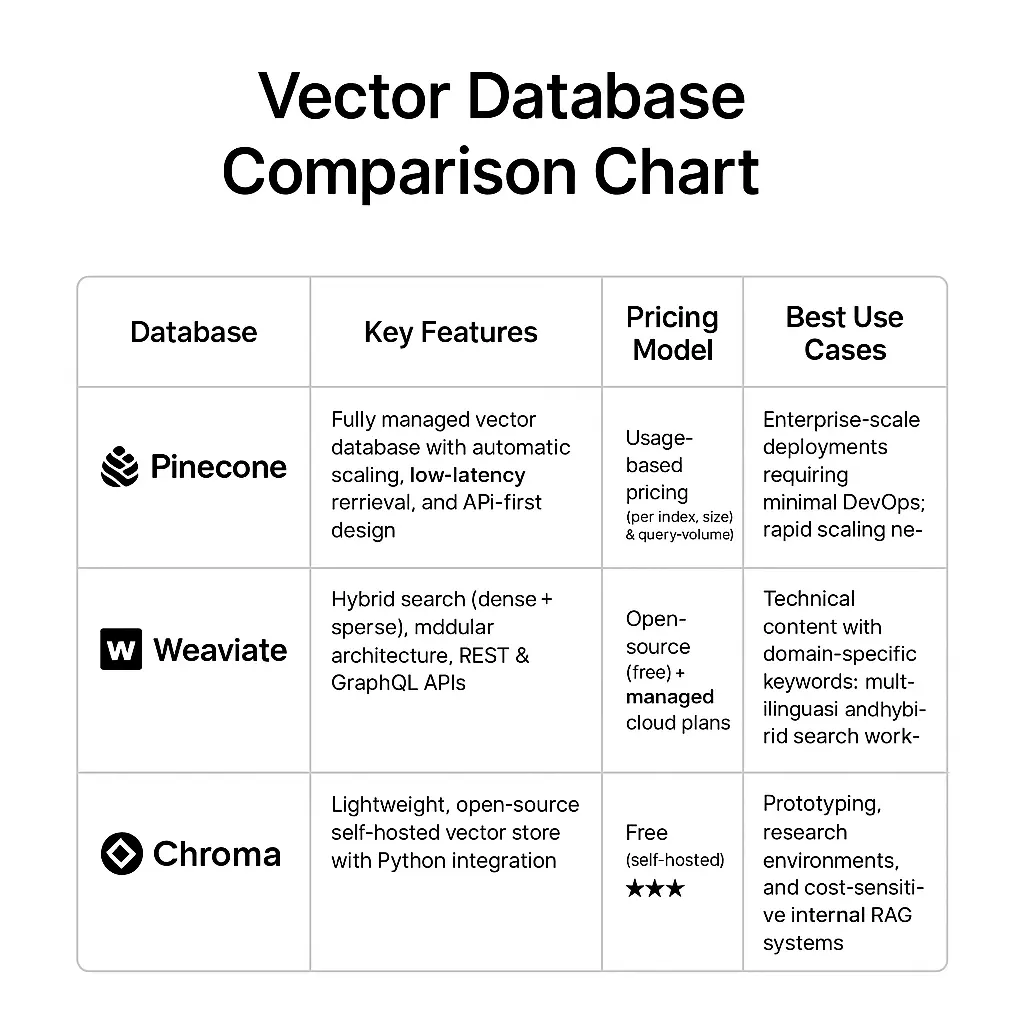
Fig.2 Vector database comparison chart showing features, pricing models, and use case recommendations
Why Comprehensive QA Testing Reduces RAG System Failures (And How to Implement It)
Comprehensive QA testing for RAG systems addresses failure points that traditional testing consistently misses. RAG systems fail in edge cases: ambiguous queries, conflicting information in the knowledge base, and context switching between different topics.
Three-Level Testing Framework
The testing framework requires three levels of validation:
- Retrieval accuracy testing validates that the system finds relevant documents for diverse query types
- Generation quality testing ensures responses are coherent, factually accurate, and properly attributed
- End-to-end testing validates the complete user workflow from query to actionable response
Here’s what comprehensive test coverage actually looks like:
- Automated tests that validate semantic relevance scores for test queries
- Factual accuracy checks against ground truth datasets
- Response coherence scoring using language models trained specifically for evaluation tasks
Continuous Testing Pipeline Integration
Integrate QA testing into CI/CD pipelines with automated regression testing, performance monitoring, and accuracy benchmarking. This approach prevents the gradual degradation that kills RAG system adoption over time.
Key performance indicators for monitoring include:
- Retrieval precision@k (how often the top k results contain relevant information)
- Answer relevance scores (semantic similarity between questions and responses)
- User satisfaction ratings collected through embedded feedback mechanisms
Real-time monitoring flags responses with low confidence scores or unusual retrieval patterns. Implement automated feedback collection systems that learn from user interactions, correction patterns, and expert validations.
Proactive Issue Detection
Proactive issue detection through comprehensive testing identifies potential problems before deployment by testing edge cases, adversarial inputs, and corner scenarios. The testing process generates test cases based on production query patterns, ensuring coverage of real-world usage scenarios that don’t appear in traditional test suites.
Automated regression testing implements test generation that creates new test cases based on production queries and failure patterns. This dynamic testing approach ensures consistent quality as systems scale and evolve.
Ready to make your RAG implementation cost-effective and scalable?
Partner with SmartDev’s AI experts to design, deploy, and maintain efficient, compliant, and enterprise-ready RAG systems tailored for your business needs.
Optimize long-term ROI, reduce knowledge-search overhead, and scale confidently with our AI-powered delivery framework.
Start My RAG Implementation PlanYour 12-Week Implementation Road map (That Actually Works)
Weeks 1-4: Foundation Setup
Foundation setup determines whether your RAG implementation succeeds or becomes another abandoned AI project. Establish vector database infrastructure first, focusing on scalability requirements and performance benchmarks.
Week 1-2 Tasks:
- Set up vector database infrastructure
- Implement basic document processing pipelines
- Create initial embedding indexes with representative content subset
Week 3-4 Tasks:
- Deploy basic QA testing infrastructure
- Implement accuracy measurement tools
- Set up performance monitoring dashboards
Create initial embedding indexes with a representative subset of your knowledge base—typically 10-20% of total content across different document types and departments. This subset approach validates architecture decisions before full-scale processing and helps identify content quality issues early.
Weeks 5-8: Content Integration Phase
Content integration requires systematic knowledge migration that maintains quality standards. Process and index enterprise content in batches, validating retrieval quality at each stage. Start with high-value, frequently accessed content that provides immediate user value and demonstrates ROI to stakeholders.
Implementation priorities:
- High-frequency access documents (policies, procedures)
- Customer-facing knowledge (product documentation, FAQs)
- Technical documentation (APIs, troubleshooting guides)
- Historical reference materials
Implement content versioning and change tracking to maintain knowledge base integrity over time. Your content management strategy needs to handle updates, deletions, and new additions without breaking existing functionality or creating inconsistent responses.
Expand testing to cover full content scope with automated accuracy validation, edge case testing, and performance optimization. This comprehensive QA approach ensures reliable system behavior at enterprise scale.
Weeks 9-12: Production Deployment
Production deployment requires gradual rollout strategy that builds confidence and collects real-world feedback. Deploy RAG systems to pilot user groups with comprehensive monitoring and feedback collection.
Deployment phases:
- Internal pilot (weeks 9-10): IT and knowledge management teams
- Department pilot (week 11): Single business unit with high knowledge needs
- Gradual expansion (week 12): Additional departments based on pilot feedback
Implement ongoing improvement processes including automated retraining, content freshness monitoring, and user experience optimization. This iterative approach maintains system effectiveness as enterprise needs change.
The deployment strategy should target power users first—employees who frequently search for information and can provide detailed feedback about system performance. These early adopters become internal champions who drive broader organizational adoption.
How to Measure RAG Success (Beyond User Satisfaction Surveys)
Technical Performance Indicators
Technical performance indicators provide objective measures of system health and user experience quality:
- Query response times: Target under 2 seconds for 95% of queries
- Retrieval accuracy: Above 85% relevance for top-5 results
- System availability: Above 99.5% uptime
- Content freshness: Automated detection of outdated information
Response time measurement requires end-to-end monitoring from query submission to final response delivery. Break down timing into components: query processing, vector search, document retrieval, and response generation. This granular monitoring helps identify performance bottlenecks before they impact user experience.
Business Impact Measurement
Track knowledge worker productivity gains, reduced support ticket volumes, and improved decision-making speed through direct measurement rather than surveys. Establish baseline metrics before implementation to demonstrate concrete business value.
Productivity metrics to track:
- Time spent on information retrieval tasks
- Number of internal support requests related to knowledge access
- Decision-making cycle times for standard business processes
- Employee onboarding completion times
The financial impact calculation should include reduced training costs, decreased onboarding time for new employees, and improved compliance through consistent information access.
Long-term Optimization Strategies
Long-term optimization focuses on continuous learning implementation through feedback loops that automatically improve system performance. Establish feedback mechanisms that capture user corrections, relevance ratings, and usage patterns to train improved models and refine content organization.
Scalability planning requires designing expansion strategies for additional content types, user groups, and integration requirements. Plan for 3-5x growth in content volume and user base over two years to ensure sustainable system performance.
Common Implementation Pitfalls (And How to Actually Avoid Them)
Vector Database Performance Issues
Vector database performance issues kill more RAG implementations than any other technical factor. Poor indexing strategies, inadequate query optimization, and missing caching mechanisms lead to response times that drive users back to traditional search methods.
Monitor query patterns during pilot deployment to identify optimization opportunities. Common patterns include geographic clustering of similar queries, temporal patterns in content access, and user role-based query types. Use these patterns to optimize index structure and caching strategies.
Content Quality Management
Content quality management requires automated content validation, duplication detection, and freshness monitoring. Poor content quality is the leading cause of RAG system failures because users quickly lose trust in systems that provide outdated or contradictory information.
Quality control measures:
- Automated content quality scoring
- Document completeness evaluation
- Consistency checking across sources
- Recency validation and update alerts
Flag content that hasn’t been updated within defined timeframes and establish workflows for content review and validation.
User Adoption Challenges
User adoption challenges stem from inadequate training, complex interfaces, and unclear value propositions. Involve end users in the design process to create systems that integrate naturally into existing workflows rather than requiring new habits or extensive training.
Create intuitive interfaces that work within existing tools where possible. Integration with Microsoft Teams, Slack, or other collaboration platforms reduces adoption friction and provides immediate value within established workflows.
Governance and Compliance Frameworks
Governance and compliance frameworks prevent regulatory issues and maintain information security standards. Establish clear policies for content management, access control, audit trails, and data retention.
Essential governance elements:
- Content ownership and update responsibilities
- Access permissions and security controls
- Audit trails for compliance reporting
- Regular review cycles for accuracy maintenance
- Clear escalation paths for content disputes
Ready to Implement Enterprise RAG Systems?
 Successful RAG implementation requires careful planning, systematic testing, and ongoing optimization. The combination of proper architecture design, comprehensive QA testing, and phased deployment creates the foundation for sustainable enterprise knowledge management improvement.
Successful RAG implementation requires careful planning, systematic testing, and ongoing optimization. The combination of proper architecture design, comprehensive QA testing, and phased deployment creates the foundation for sustainable enterprise knowledge management improvement.
Ready to implement RAG systems that actually deliver on their promises? Contact SmartDev’s AI development team to discuss your specific requirements and learn how our proven methodology reduces implementation risks while achieving measurable business outcomes.











