In today’s world, Artificial Intelligence (AI) has evolved from a niche research field to a mainstream technology that shapes industries and everyday life. From predicting customer preferences to powering self-driving cars, AI models are transforming how businesses operate and how we interact with technology. But behind every successful AI application is an AI model — a complex, powerful tool that learns from data to solve problems and make decisions without explicit programming.
As AI continues to mature, understanding how to build these models is more crucial than ever. Whether you’re a data scientist, a business leader, or an AI enthusiast, the ability to create and deploy AI models opens up endless possibilities for innovation and problem-solving.
But how exactly does one go about building an AI model from scratch?
What does the process involve, and what are the key steps to ensure success?
In this blog post, we will take you through the foundational steps of AI model development, providing insights into the underlying processes, key technologies, and best practices you need to build powerful AI systems that deliver real-world value.

As you explore the foundational steps of building AI models, it’s important to recognize that successful outcomes depend on more than just algorithms—they require a holistic approach that bridges strategy, technology, and real-world deployment. For organizations ready to turn AI concepts into production-ready solutions, discover how AI-assisted software development can help accelerate your journey from idea to impactful business results.
1. Introduction to AI Model Development
In this section, you will learn about what AI models really are, how they power modern applications, and the key differences between machine learning, deep learning, and generative AI. You’ll also discover how AI models stand apart from traditional software and why this matters for innovation.
Whether you’re building your first model or planning your next AI project, this foundational knowledge will set you up for success—so keep reading to unlock the right model for your business needs.
a. What is an AI Model?
At its core, an AI model is a mathematical representation of a problem or task that learns from data. It can recognize patterns, make predictions, or automate decision-making. AI models are the driving force behind advancements in machine learning (ML), deep learning (DL), and even more advanced technologies like generative AI.
But how do these models learn?
They are trained on vast amounts of data and use algorithms to detect patterns, relationships, or correlations that would be nearly impossible for humans to define manually.
b. The Importance of AI in Modern Applications
AI has become indispensable in today’s tech-driven world. It powers personalized experiences, enhances business intelligence, and even predicts future trends. From virtual assistants like Siri and Alexa to sophisticated fraud detection systems in banking, AI models are integrated into our daily lives in ways we often take for granted. For businesses, AI presents opportunities for automation, efficiency, and more accurate decision-making. In healthcare, AI models can predict patient outcomes or assist in drug discovery, improving lives and optimizing costs.
The transformative power of AI is vast, but it’s the AI model, the structure that powers this intelligence, that makes it all possible.
c. Types of AI Models
As AI continues to evolve, different types of AI models are emerging, each designed for specific tasks and applications:
- Machine Learning (ML) Models: These models use statistical techniques to learn from historical data and make predictions. Examples include regression models and decision trees, which are widely used for tasks like classification and regression.
- Deep Learning (DL) Models: A subset of machine learning, deep learning involves neural networks with many layers, enabling the model to perform complex tasks like image recognition, speech recognition, and more. These models require vast amounts of data and computing power but can deliver impressive results in fields like computer vision and natural language processing.
- Generative AI Models: These models generate new data, rather than simply analyzing or classifying existing data. They include Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), which are used for tasks like creating realistic images or generating new pieces of text, music, and video.
d. Key Differences Between AI Models and Traditional Software
While traditional software follows explicit programming instructions to perform specific tasks, AI models are designed to learn and adapt based on the data they receive. In other words, rather than relying on pre-programmed rules, AI models improve over time by analyzing new data, making them far more flexible and capable of handling complex, unpredictable scenarios.
This adaptability is what sets AI models apart. They can recognize patterns in data that would otherwise be impossible for a human programmer to identify. But this also means that the development of AI models requires a deep understanding of data, algorithms, and evaluation metrics — elements that are not typically part of traditional software development.
2. Understanding the AI Development Lifecycle
Building a successful AI model is not an overnight task. It involves a carefully structured lifecycle — a series of well-defined stages that guide the model from inception to deployment, and beyond. Each stage plays a critical role in ensuring that the final product is robust, accurate, and ready for real-world application. Understanding this lifecycle is essential for anyone involved in AI model development, as it provides the roadmap for creating AI solutions that deliver value.
In this section, we will explore the key stages of the AI development lifecycle and the crucial steps involved in each phase.
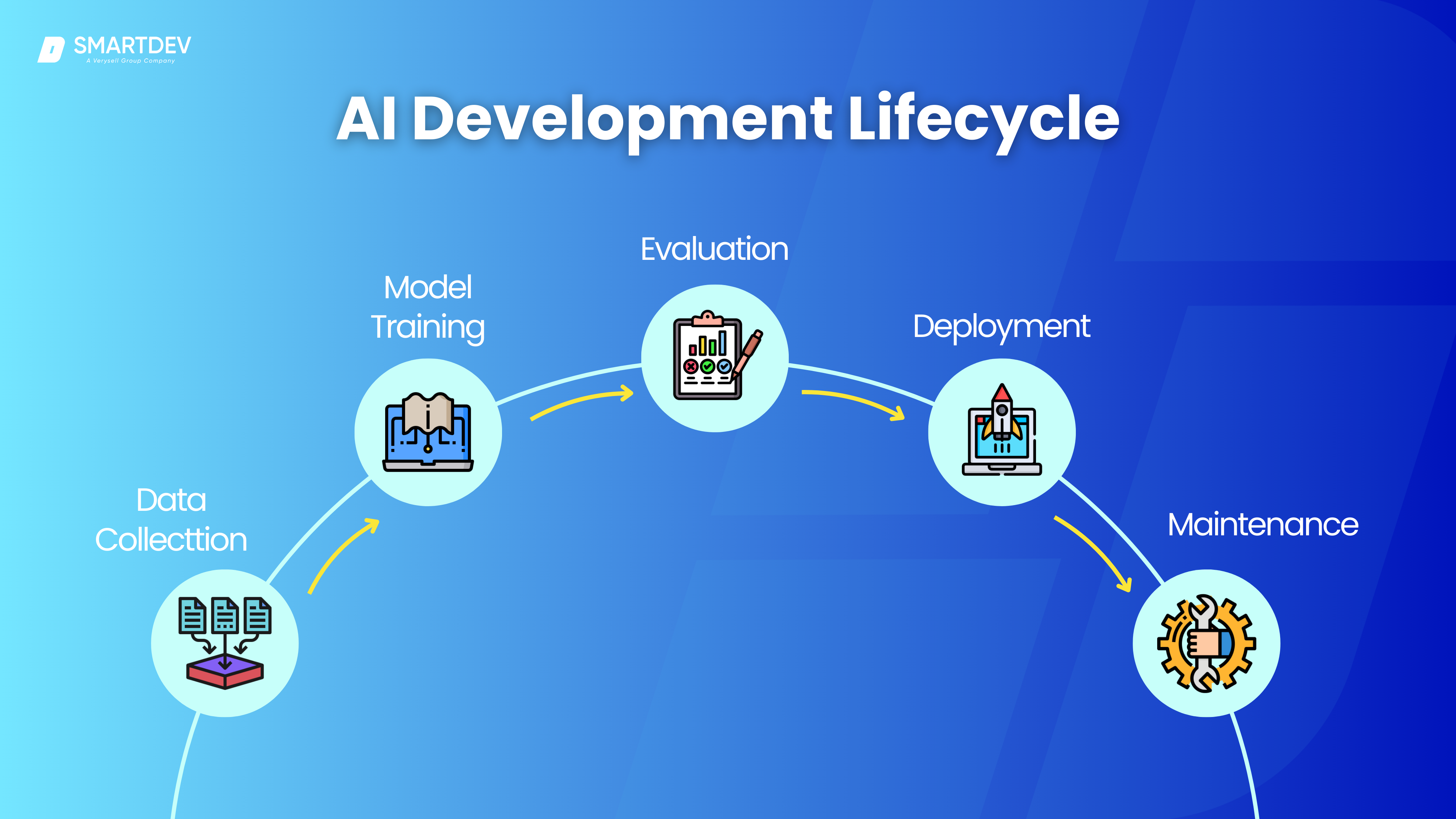
a. The AI Model Development Process Explained
Each stage of the AI lifecycle is interconnected and iterative. Let’s take a closer look at each phase:
- Data Collection is the foundation of the AI model. Without good data, no model can perform well, no matter how advanced the algorithms are. This step often involves sourcing datasets from various sources or creating new datasets through surveys, sensors, or other collection methods.
- Model Training is where the magic happens. In this stage, the model is trained using algorithms that allow it to learn the relationships in the data. Depending on the type of model you are building (e.g., supervised, unsupervised, reinforcement learning), the training process will differ, but the core idea remains the same: the model learns from the data to make predictions or decisions.
- Evaluation is a critical step where you assess how well your model performs. Metrics like accuracy, precision, recall, and F1-score are used to gauge the effectiveness of the model, while techniques such as cross-validation ensure the model is robust and not overfitting to the training data.
- Deployment puts the trained model into action. This stage is where the model is made accessible to users, either through cloud services, edge devices, or APIs. During deployment, scalability and integration with existing systems are key considerations.
- Maintenance is ongoing. AI models need to be retrained with new data over time to ensure they remain relevant and accurate. Continuous monitoring helps detect issues like performance drift, where the model’s accuracy declines over time due to changes in data distribution.
b. Overview of AI Model Architecture
AI model architecture is the blueprint for how a model processes and learns from data. The architecture defines how the different layers of a model interact and what kind of algorithms it uses to process inputs and generate outputs. For example:
- In neural networks, layers of neurons are used to process data, with each layer learning more abstract features of the data.
- In decision trees, a model breaks down decision-making into a series of decisions based on feature values, leading to a final prediction.
The architecture is designed based on the problem at hand. For instance, convolutional neural networks (CNNs) are typically used for image recognition tasks, while recurrent neural networks (RNNs) are better suited for sequential data, such as time series or natural language processing.
AI model architecture is not one-size-fits-all — it must be tailored to the specific type of task the model is being built for. Understanding how to design and optimize the architecture is a crucial skill for anyone looking to develop AI models.
3. Choosing the Right AI Model Type for Your Use Case
| Model Type | Use Case | Example | Key Applications |
| Supervised Learning | Labeled data with a clear output. Best for prediction tasks. | – Linear Regression – Logistic Regression – Decision Trees – Support Vector Machines | – Fraud detection – Customer segmentation – Predictive analytics – Spam filtering |
| Unsupervised Learning | Unlabeled data. Best for discovering hidden patterns or groupings. | – K-means – DBSCAN – Hierarchical Clustering – Principal Component Analysis (PCA) | Customer segmentation – Anomaly detection – Market basket analysis – Data clustering |
| Reinforcement Learning | Sequential decision-making in dynamic environments. Best for tasks requiring learning through trial and error. | – Q-learning – Deep Q Networks (DQNs) – Policy Gradient Methods | – Robotics – Self-driving cars – Game playing (e.g., AlphaGo) – Recommendation systems |
| Deep Learning | Tasks involving large and complex data (e.g., images, speech, text). Requires large datasets and high computational power. | – Convolutional Neural Networks (CNNs) – Recurrent Neural Networks (RNNs) – Transformers (e.g., GPT-3, BERT) | – Image recognition – Speech recognition – Natural language processing (NLP) – Autonomous vehicles |
| Generative AI | Creating new data that mimics real-world data. Best for generating new content. | – Generative Adversarial Networks (GANs) – Variational Autoencoders (VAEs) – Large Language Models (LLMs) | – Image generation (e.g., deepfakes) – Art creation – Text generation (e.g., GPT-3) – Data augmentation |
The key to choosing the right AI model lies in understanding the specific requirements of your task. This table offers a high-level comparison to help guide your decision:
- Supervised learning is ideal when you have labeled data and clear target variables.
- Unsupervised learning excels in discovering unknown patterns and structures in data without labels.
- Reinforcement learning is perfect for tasks that involve interacting with an environment and learning from feedback.
- Deep learning models are the go-to choice for high-dimensional, complex data such as images, speech, or text.
- Generative AI is transformative when your goal is to create new, synthetic data that mimics real-world data.
By understanding these model types, their uses, and applications, you can make an informed choice about which approach to pursue based on your project’s needs.
4. Step-by-Step Guide to Building an AI Model from Scratch
Building an AI model from scratch involves a structured approach, where each phase plays a critical role in ensuring the model meets the desired objectives. Below is a detailed guide outlining the key steps in the AI model development process.
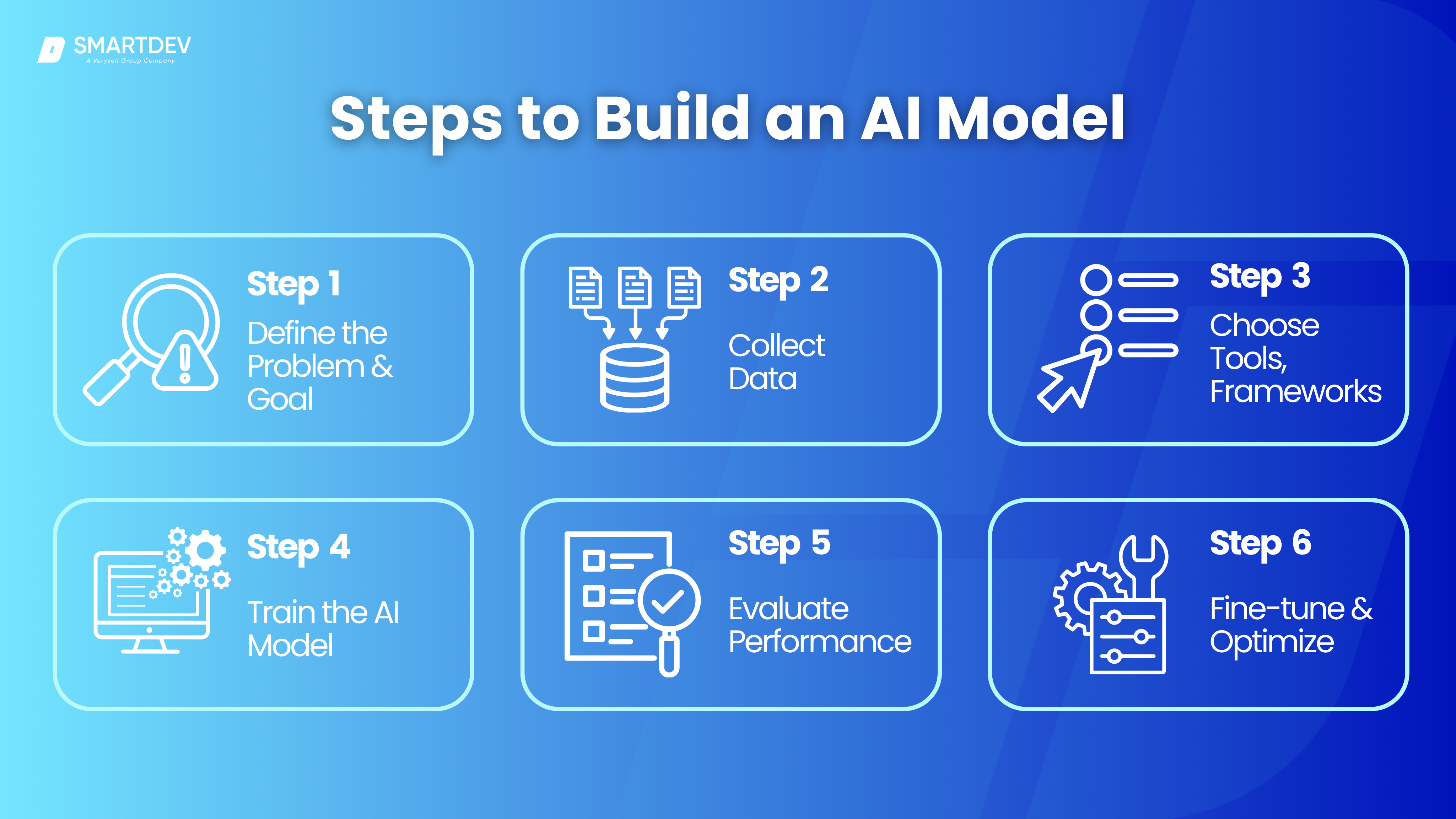
Step 1: Define the Problem and Business Goal
The first and perhaps most important step in creating an AI model is to define the problem clearly. This involves understanding the problem you are trying to solve and aligning the AI model’s goals with your business objectives. Defining the problem will help determine the type of data needed, the type of model you will use, and how success will be measured.
At this stage, it’s essential to engage with stakeholders to get a clear understanding of what the business needs. This understanding will help you set clear objectives, such as predicting a certain outcome or automating a specific process. Knowing what success looks like will guide the entire model-building process, from data collection to deployment.
Step 2: Collect and Prepare Data
Data is at the heart of any AI model. Without the right data, even the most sophisticated algorithms will fail. The next step is to gather the necessary data. This might involve collecting data from internal systems, using publicly available datasets, or even purchasing data from third-party providers.
Once you’ve collected the data, it needs to be cleaned and preprocessed. This involves dealing with missing values, removing duplicates, and handling any outliers. Data preprocessing ensures that the model will not be misled by noisy or irrelevant data.
If you’re working on a supervised learning task, the data must be labeled appropriately, so the model can learn from it. After the data has been cleaned and labeled, it should be divided into three sets: training, validation, and test data. This ensures that the model can be trained on one portion of the data, tuned on another, and evaluated on a third to assess its generalization performance.
Step 3: Choose the Right Tools, Frameworks, and Libraries
Choosing the right tools and frameworks is critical for efficient model development. The programming language you select will determine the ecosystem of libraries and tools you have access to. Python is the most widely used language for AI development due to its rich ecosystem of libraries, such as TensorFlow, PyTorch, and Scikit-learn, which provide the necessary tools for machine learning and deep learning tasks.
In addition to programming languages, selecting the right framework for your AI task is important. TensorFlow and PyTorch are the go-to frameworks for deep learning, while Scikit-learn is commonly used for traditional machine learning tasks. If you plan to scale your model or use advanced computing resources, cloud platforms like AWS, Google Cloud, or Azure provide the infrastructure needed for training large models.
Another consideration is whether to use AutoML solutions, which are designed to automate the process of building and deploying models, or to develop a custom model for more control and flexibility. AutoML platforms like Google AutoML or H2O.ai can be helpful for users with limited experience, as they streamline the model development process.
Step 4: Train the AI Model
Training the AI model is where the core learning happens. During this phase, the model is fed the training data and learns to make predictions or decisions based on that data. The choice of algorithm depends on the problem you’re solving and the type of data you have.
For example, if you’re working on a classification problem, you might use algorithms like logistic regression or decision trees. If the task involves predicting a continuous variable, regression algorithms like linear regression would be appropriate.
Feature engineering is also a crucial part of this phase. This involves selecting and transforming the input features (the data that will be used to make predictions) to improve the model’s performance. Sometimes, new features need to be created to better capture the patterns in the data.
Hyperparameter tuning is another important part of training the model. Hyperparameters are parameters set before the learning process begins (such as the learning rate in neural networks or the number of trees in a random forest). Finding the optimal set of hyperparameters can significantly impact the model’s performance.
Step 5: Evaluate the AI Model Performance
After training the model, the next step is to evaluate its performance. This is done by testing the model on data it hasn’t seen before (the test set). Evaluation metrics depend on the type of problem. For classification problems, metrics like accuracy, precision, recall, and F1-score are commonly used. For regression tasks, you might use metrics like Mean Absolute Error (MAE) or R-squared.
It’s essential to check for both overfitting and underfitting. Overfitting occurs when the model is too complex and learns the noise in the training data, which results in poor performance on new, unseen data. On the other hand, underfitting happens when the model is too simple and fails to capture important patterns in the data.
Cross-validation is often used during evaluation to ensure that the model performs well on different subsets of the data. This helps assess the model’s generalization ability and ensures that it isn’t overly tailored to a specific portion of the dataset.
Pro Tip: If you’re interested in diving deeper into AI performance evaluation and optimizing your models, check out our comprehensive guide on AI Model Performance. This will give you actionable insights to fine-tune and improve your model’s effectiveness.
Step 6: Optimize and Fine-Tune the AI Model
Optimization is an ongoing process that aims to enhance the model’s performance by fine-tuning its parameters and improving its ability to generalize. Hyperparameter tuning, which was introduced earlier, is a key aspect of this phase. It’s done by testing different hyperparameter values and selecting the ones that provide the best results.
Additionally, regularization techniques such as L1 and L2 regularization can be applied to prevent overfitting. These methods add a penalty to the model for being overly complex, which forces the model to focus on the most important features and ignore noise.
In some cases, transfer learning is used to improve the model’s performance. Transfer learning involves using a pre-trained model on a related task and fine-tuning it to solve your specific problem. This approach is particularly useful in deep learning, where training models from scratch can be computationally expensive and time-consuming.
5. Deploying the AI Model in Real-World Applications
There are several ways to deploy AI models, depending on the specific requirements of the use case, the computational resources, and the environment in which the model will operate.
a. Deploying AI Models on Cloud
Cloud platforms like AWS, Google Cloud, and Microsoft Azure offer scalable infrastructure and pre-built services that simplify the deployment of AI models. These platforms enable easy deployment and management of models, providing tools for model versioning, continuous integration, and scaling as needed.
For instance, AWS SageMaker allows users to quickly train, tune, and deploy machine learning models on a fully managed infrastructure. It also offers built-in algorithms for tasks such as fraud detection, image classification, and natural language processing, making it easier for businesses to leverage AI at scale. Similarly, Google Vertex AI provides a unified platform for deploying machine learning models on the cloud, offering tools for both development and deployment in a seamless environment.

Source: Guru
b. Deploying AI Models on Edge Devices
For certain use cases, particularly in Internet of Things (IoT) or real-time applications, deploying AI models on edge devices is essential. Edge deployment ensures that AI models can run locally on devices such as smartphones, IoT devices, or autonomous vehicles, providing faster response times with minimal latency.
For example, Apple’s CoreML framework allows AI models to be deployed directly on mobile devices, enabling real-time image processing or voice recognition without needing to send data to the cloud. NVIDIA Jetson is another edge platform used in applications like robotics, where AI models can process data from sensors in real-time, allowing robots to make decisions on the spot without relying on cloud connectivity.

Source: Create with Swift
c. APIs and Microservices for AI Deployment
Another effective way to deploy AI models is by exposing them through APIs or microservices. By wrapping the AI model into an API, it can be easily integrated into existing applications, allowing developers to leverage the model’s capabilities without needing to know the intricacies of the underlying algorithms.
For instance, IBM Watson offers several AI-powered APIs, including those for language translation, speech-to-text, and sentiment analysis. Businesses can integrate these APIs into their applications to add advanced AI features with minimal effort. Similarly, deploying AI models as microservices allows for easier scalability and integration into larger systems, whether in e-commerce for recommendation engines or in finance for credit scoring.

Source: TechRadar
d. CI/CD for AI Models (MLOps Best Practices)
As with any software system, continuous integration (CI) and continuous deployment (CD) are vital for ensuring that AI models are updated and maintained regularly. MLOps is a set of best practices that combine machine learning with DevOps to streamline the deployment pipeline for AI models, ensuring efficient and reliable updates.
In practice, MLOps ensures that models are continuously retrained with fresh data, performance is monitored post-deployment, and models can be updated or rolled back if necessary. Kubeflow, for instance, is an open-source platform for deploying and managing ML models in Kubernetes environments, making it easier to automate the CI/CD pipeline for AI systems.
6. Monitoring and Maintaining AI Models
Once deployed, AI models require continuous monitoring and maintenance to ensure they perform well over time. Regular checks are essential for adapting to changing data and maintaining model effectiveness in real-world conditions.
a. Model Performance Monitoring (Drift Detection)
AI models can experience data drift (when incoming data changes) or model drift (when performance declines). Regular monitoring of key metrics like accuracy and precision helps detect these drifts early. Tools like Evidently.ai and Arize AI provide automated performance tracking and drift detection.
b. Regular Retraining and Updating AI Models
Models must be periodically retrained with new data to stay relevant. Retraining ensures the model adapts to changes in the data environment. Active learning techniques can also be used, where the model requests human feedback on uncertain predictions to improve over time.
c. AI Model Explainability and Interpretability
As models grow more complex, explaining how they make decisions becomes increasingly important. Approaches like LIME and SHAP help improve transparency, particularly in sectors like healthcare and finance, where trust and compliance are critical.
d. Security and Ethical Considerations in AI Models
Security is crucial for AI models, as they must be protected against adversarial attacks. Additionally, ethical concerns, such as model bias, need to be addressed regularly. Regular audits can help detect and mitigate biases, ensuring the model remains fair and reliable.
7. Challenges and Pitfalls in AI Model Development
Building AI models comes with its own set of challenges. These challenges can arise at any stage of the model development process — from data collection to deployment. Understanding these common pitfalls and knowing how to address them can help streamline the process and ensure a successful AI project.
Common Mistakes to Avoid When Building AI Models
- Insufficient or Poor-Quality Data: One of the most frequent mistakes in AI development is working with poor-quality data. Inadequate data leads to biased or inaccurate models. It’s crucial to invest time and effort into data collection and cleaning to ensure your models have reliable input.
- Overfitting and Underfitting: Overfitting occurs when a model is too complex and learns the noise in the training data, resulting in poor generalization. On the other hand, underfitting happens when the model is too simple to capture the patterns in the data. Striking the right balance is essential for creating a robust model.
- Ignoring Model Interpretability: Many developers focus solely on accuracy and performance without considering how to make the model’s decisions interpretable. This can be problematic, especially in high-stakes industries like healthcare and finance. It’s important to include interpretability and explainability from the outset.
- Neglecting Model Evaluation: Some developers skip or overlook the evaluation phase, which is crucial for assessing a model’s effectiveness. Regular evaluation against test data and cross-validation techniques ensures that your model is performing as expected.
Data Privacy and Ethical Concerns
Data privacy is one of the most pressing issues in AI today. With AI models processing sensitive data, it’s essential to ensure that models comply with privacy regulations like the GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act). Failure to comply can result in legal consequences and damage to a company’s reputation.
AI models also face growing scrutiny regarding ethical concerns, especially when it comes to bias. For example, facial recognition systems have been criticized for racial and gender biases, leading to calls for greater transparency in how these systems are trained. It’s crucial to ensure that AI models are tested for fairness and do not perpetuate or amplify existing biases in the data.
Scalability and Computational Challenges
AI models can be computationally intensive, particularly deep learning models. Training these models requires significant resources, such as high-performance GPUs or TPUs. Without sufficient infrastructure, models may not scale effectively.
In addition to computational resources, scalability also involves ensuring that the model can handle increasing amounts of data over time. This requires designing systems that are not only capable of running on large datasets but also flexible enough to adapt to evolving data.
AI Bias
AI bias can arise at various stages of model development. Bias in data — whether it’s due to historical inequalities or unrepresentative samples — can lead to biased predictions. For example, a hiring algorithm trained on biased data could inadvertently discriminate against certain groups.
To mitigate bias, it’s crucial to ensure diversity in the data and employ techniques like algorithmic fairness and bias detection. Regular audits of models and training data can help identify and reduce bias over time.
8. Case Studies: Real-World AI Model Implementations
Artificial Intelligence (AI) continues to revolutionize multiple sectors, offering innovative solutions and enhancing operational efficiencies. Below are notable recent implementations of AI models across various industries:
AI in Healthcare: Clinical Trial Recruitment and Patient Care
AI agents are transforming healthcare by streamlining administrative processes and improving patient outcomes. Companies are developing AI agents named Grace, Max, and Tom to assist in enrolling clinical trial participants, ensuring proper post-hospitalization care, and briefing doctors on patient histories. These agents aim to alleviate physician burnout by handling routine tasks, allowing healthcare professionals to focus on direct patient care.
AI in Automotive: Enhancing Vehicle Design and Manufacturing
Ford Motor Company is accelerating its use of AI to design and engineer vehicles more efficiently. By integrating AI tools from companies like OpenAI and Nvidia, Ford can rapidly generate 3D models and predict stress factors, significantly reducing design time from hours to seconds. This integration enhances innovation and streamlines the vehicle development process.
Similarly, General Motors (GM) has partnered with Nvidia to advance its autonomous vehicle and manufacturing projects. GM utilizes Nvidia’s Omniverse 3D graphics platform for simulations to boost efficiency in assembly lines and integrates Nvidia’s AI systems for advanced driver assistance and autonomous driving in next-generation vehicles.

Source: TechCrunch
AI in Retail: Enhancing Customer Experience and Operational Efficiency
Australian companies are increasingly adopting AI to improve customer service and operational efficiency. Businesses like Telstra and Bunnings employ AI tools such as AskTelstra and “Ask Lionel” to streamline customer interactions and provide real-time product information. National Australia Bank utilizes generative AI for various tasks, freeing up bankers’ time to focus on customer engagement.

Source: The New Daily
AI in Autonomous Vehicles: Advancements in Self-Driving Technology
Chinese electric vehicle manufacturers are rapidly integrating DeepSeek’s AI model into their vehicles. Companies like BYD, Geely, Great Wall, and Dongfeng are adopting DeepSeek’s R1 reasoning model to enhance their EVs’ AI capabilities. This integration aims to meet the growing consumer demand for advanced technology and self-driving features in Chinese electric vehicles.

Source: Euronews
9. Future Trends in AI Model Development
The AI landscape is evolving rapidly, with several key trends shaping its trajectory:
a. Agentic AI
AI systems are progressing towards greater autonomy, with “agentic AI” enabling models to make independent decisions and perform tasks without human intervention. Major firms like Deloitte and EY are developing agentic AI platforms to enhance productivity and transform business operations.
b. AI Reasoning and Frontier Models
There’s a growing emphasis on enhancing AI’s reasoning capabilities. Enterprises are focusing on AI models that can understand context and make informed decisions, moving beyond basic pattern recognition to more sophisticated cognitive functions.
c. Synthetic Data Generation
To address data scarcity and privacy concerns, synthetic data generation is gaining traction. Companies like Nvidia are investing in technologies to create artificial datasets that preserve privacy while providing valuable training data for AI models.
d. AI in Robotics
Integrating AI with robotics is leading to advancements in physical AI, where robots can understand and interact with the physical world. Nvidia’s introduction of the Isaac GROOT N1 model exemplifies this trend, aiming to enhance robotic capabilities.
e. Multimodal AI
AI systems are becoming more adept at processing and integrating multiple data types, such as text, images, and speech. This multimodal approach enhances AI’s contextual understanding and application across various domains.
10. Conclusion & Next Steps
AI model development, despite its incredible potential, faces several challenges that must be addressed for widespread adoption. One of the primary concerns is data privacy and security. As AI systems process large volumes of sensitive data, ensuring the protection of user privacy and securing models from potential breaches is essential. Additionally, ethical considerations like bias and fairness need to be carefully managed to prevent unintended harmful consequences, such as discrimination in automated decision-making processes.
Another significant hurdle is model interpretability. In industries like healthcare and finance, stakeholders require transparency in AI’s decision-making processes to foster trust and comply with regulations. Furthermore, the high computational resource demands for training complex AI models raise environmental concerns, and developers must focus on improving model efficiency. As AI continues to evolve, navigating regulatory compliance will also be essential to ensure that AI applications are both ethical and legally sound.
As AI continues to shape the future of industries, it is crucial to stay ahead of these challenges. Organizations need to adopt best practices, continually refine models, and collaborate with regulatory bodies to build responsible AI systems. If you’re looking to integrate AI into your business, consider working with experts who can guide you through the complexities of development and deployment. Let’s innovate responsibly—reach out to start your AI journey today.
—
References
- Companies Bring AI Agents to Healthcare | Wall Street Journal
- Ford Looks to Innovate Faster With AI Agents and Nvidia GPUs | Wall Street Journal
- GM taps Nvidia to boost its embattled self-driving projects | The Verge
- Corporate chiefs back AI to boost business | The Australian
- Nvidia Bets Big on Synthetic Data | Wired
- Big Four bet on AI agents that can do all the work and ‘liberate’ staff | Business Insider










