Introduction: The AI Revolution in Unstructured Data
Artificial Intelligence (AI) is driving a major shift in how data is analyzed and utilized, particularly with unstructured data. Unlike structured data, which is neatly organized and easy to analyze, unstructured data—such as text, images, audio, and video—presents a challenge for traditional systems.
However, with advancements in machine learning (ML) and Natural Language Processing (NLP), AI is unlocking the vast potential of unstructured data, offering powerful tools to extract insights, improve decision-making, and streamline operations. This transformation is creating new opportunities across industries like healthcare, retail, and finance.
AI’s ability to process unstructured data at a scale has become crucial as the volume of data continues to grow. As businesses increasingly realize the value of unstructured data, AI-driven tools help analyze sources like social media posts, medical records, and customer reviews that were previously difficult to harness.
Unstructured AI is rapidly gaining traction, enabling organizations to mine valuable insights from this vast and complex data. With AI’s continued development, businesses can now drive efficiencies, enhance customer experiences, and make more informed decisions, making unstructured AI an essential tool for success in today’s data-driven world.
In this section, you will learn about:
What unstructured AI really means
Why it’s gaining traction right now
The key differences between structured and unstructured data
Why unstructured data accounts for 80% of all data—and why that’s a big deal
How unstructured AI is already transforming modern industries
Let’s dive in and see how this data revolution is reshaping the way businesses operate.
Definition & Characteristics of Unstructured Data

What is Unstructed Data?
Unstructured data refers to information that doesn’t adhere to a predefined model or format. Unlike structured data, which is organized in rows and columns (such as in spreadsheets or databases), unstructured data lacks a consistent structure. It includes a variety of formats like text, images, audio files, and video, making it difficult to store, query, and analyze using traditional methods.
Unstructured data is often highly variable and complex, posing a challenge for data management and extraction of meaningful insights. Examples of unstructured data are numerous and span various industries. Common examples include emails, social media posts, text documents, videos, photos, audio recordings, and medical images such as X-rays and MRIs.
For instance, in the healthcare industry, medical images represent a significant portion of unstructured data, requiring specialized AI tools to extract relevant information for diagnosis and treatment.
Why Traditional Databases Struggle with Unstructured Data
Traditional databases are designed to handle structured data that fits neatly into predefined tables or fields. These databases rely on schema to store and retrieve data, making them ideal for structured data.
However, unstructured data lacks this consistent format, making it difficult for conventional databases to handle it efficiently. As a result, organizations often need specialized tools, such as NoSQL databases or AI-driven analytics platforms, to manage and analyze unstructured data.
Challenges in Managing and Analyzing Unstructured Data
Managing and analyzing unstructured data presents several challenges.
- First, the sheer volume of unstructured data can be overwhelming, making it hard for organizations to keep up.
- Second, the variety of data types (e.g., text, images, video) means that businesses must use a variety of technologies to process different formats.
- Third, unstructured data is often messy, incomplete, or inconsistent, which adds another layer of complexity in terms of cleaning, organizing, and deriving actionable insights.
The Role of AI in Unstructured Data Processing
AI is redefining how we handle unstructured data. Unlike traditional methods that struggle with complexity, AI-powered tools can process language, images, audio, and more—at scale and with impressive accuracy. By using techniques like machine learning, deep learning, NLP, computer vision, generative AI, and large language models, AI transforms messy, raw data into structured insights that drive smarter decisions.
These technologies don’t just automate old processes—they introduce entirely new ways to understand and act on data that was once unusable. From analyzing customer feedback to interpreting medical scans, AI is bridging the gap between raw information and real-world impact.
In this section, you will learn about:
How AI turns unstructured data into structured insights
Why AI outperforms traditional methods in data processing
The core technologies powering unstructured AI—ML, DL, NLP, and more
Key use cases and examples of techniques like computer vision, LLMs, and generative AI
Keep reading to discover how these technologies work together—and why they’re game-changers in today’s data-driven world.
How AI Bridges the Gap Between Unstructured and Structured Data
AI plays a crucial role in transforming unstructured data into something that can be used in structured formats, enabling businesses to make better decisions.
Traditional data processing systems are designed for structured data and struggle to process the highly variable and complex nature of unstructured data. AI, particularly through techniques like machine learning (ML), natural language processing (NLP), and computer vision, can bridge this gap by interpreting, analyzing, and categorizing unstructured data, converting it into usable insights that fit within structured systems.
This ability to understand and make sense of unstructured data is a game-changer for industries seeking to leverage data for decision-making and operations.
AI vs. Traditional Methods: Why AI is a Game-Changer
Unlike traditional methods, which rely heavily on human intervention or predefined rules to analyze unstructured data, AI can automate much of the process with high accuracy. Traditional systems often require data to be manually categorized, tagged, and cleaned, which is time-consuming and prone to errors.
In contrast, AI can process massive volumes of unstructured data quickly and efficiently, identifying patterns, detecting trends, and providing insights that would be almost impossible for humans to uncover without advanced computational tools.
Machine Learning Deep Learning & NLP in Unstructured Data
Machine learning, deep learning, and natural language processing (NLP) are essential components of AI that enable the processing and analysis of unstructured data.
- Machine learning allows systems to learn from data without being explicitly programmed, making it ideal for analyzing large, complex datasets.
- Deep learning, a subset of machine learning, uses neural networks to mimic the human brain, enabling the system to learn from vast amounts of data and improve its accuracy over time.
- NLP, on the other hand, focuses on the interaction between computers and human language, making it an essential tool for processing unstructured text data like emails, social media posts, or documents.
These techniques combined enable AI to extract valuable insights from unstructured data, which traditional methods couldn’t handle effectively.
Key AI Techniques for Unstructured Data Processing
Several AI techniques are particularly useful in processing unstructured data:
- Natural Language Processing (NLP): NLP is key to understanding and interpreting human language. It allows AI systems to process and analyze text, extract meaning from documents, categorize information, and even translate languages. In industries like customer service, NLP is used to analyze customer feedback and automate responses, offering businesses actionable insights quickly.
- Computer Vision: Computer vision enables AI to interpret and understand visual data. By analyzing images and videos, AI can recognize objects, detect patterns, and even make decisions based on visual content. This is especially useful in sectors like healthcare, where AI analyzes medical images (e.g., X-rays, MRIs) to aid in diagnosis.
- Generative AI: Generative AI goes beyond just analyzing data; it can create new content based on learned patterns. It is often used in creative industries, like generating realistic images, videos, or even new texts based on user input. It’s also useful in data augmentation, where AI can generate synthetic data to train other AI models, improving their accuracy.
- Large Language Models (LLMs): LLMs, such as OpenAI’s GPT-3, are designed to understand and generate human-like text. These models can process vast amounts of unstructured textual data and generate contextually relevant and coherent outputs. LLMs have found applications in chatbots, automated content generation, and even customer support, providing businesses with more efficient ways to interact with customers and manage information.
Applications of AI for Unstructured Data Across Industries
Unstructured AI isn’t just a buzzword—it’s already reshaping industries.
In business and finance, AI helps companies analyze customer reviews, uncover insights, and streamline financial document processing. In healthcare, AI interprets medical images, aids in diagnostics, and accelerates drug discovery by making sense of complex clinical data.
In education and research, AI tools can transcribe and summarize lectures, and even assist researchers by analyzing vast amounts of academic content. Retail and e-commerce companies use unstructured AI to understand customer behavior, deliver personalized product recommendations, and forecast demand with higher accuracy.
Even legal and compliance teams are leveraging AI to analyze contracts, extract key terms, and reduce compliance risks—turning hours of manual work into minutes.
In this section, you will learn about:
Real-world use cases of AI in business, healthcare, education, retail, and law
How unstructured AI is automating high-volume tasks and unlocking new insights
Specific tools and techniques making AI adoption easier and more impactful
Why leading industries are investing in unstructured AI for long-term gains
Keep going to see how AI is not only solving today’s data problems—but giving industries a competitive edge.
4.1. Business & Finance
AI-driven insights from customer reviews & feedback
In business and finance, AI helps organizations analyze large volumes of unstructured data like customer reviews and feedback. By using Natural Language Processing (NLP) and sentiment analysis algorithms, AI can identify patterns, customer sentiment, and product performance. This empowers companies to make data-driven decisions, improve customer satisfaction, and adjust marketing strategies accordingly.
For example, AI models can automatically categorize customer feedback into positive, neutral, or negative sentiment, highlighting areas for improvement. Businesses can further leverage this information to predict customer behavior and market trends, ultimately improving customer retention and brand loyalty.
Financial document processing with AI
Financial institutions deal with numerous unstructured documents like invoices, contracts, tax returns, and audit reports. AI-powered document processing tools can automate the extraction of critical data points from these documents, significantly reducing manual effort and improving accuracy.
For instance, AI systems can automatically extract key terms from financial contracts and invoices, enabling financial analysts to quickly assess their value, risk, and compliance. This not only accelerates decision-making but also helps ensure regulatory compliance in a fast-paced industry.
4.2. Healthcare & Life Sciences
AI in medical imaging and diagnostics
In healthcare, AI is making a significant impact on medical imaging and diagnostics. Medical images, such as X-rays, MRIs, and CT scans, are unstructured data, and traditionally, their analysis has been time-consuming and dependent on the expertise of radiologists. AI algorithms, particularly deep learning models, can analyze medical images with high precision, identifying patterns and anomalies that may not be easily detected by the human eye.
AI-driven image analysis can assist in diagnosing conditions such as tumors, fractures, or heart diseases at early stages, enabling quicker and more accurate treatments. By enhancing diagnostic accuracy, AI reduces the chances of human error and provides better patient outcomes.
Drug discovery using unstructured AI
Drug discovery is another area in healthcare where AI can harness unstructured data. AI models can analyze vast amounts of unstructured data from research papers, clinical trials, and molecular structures to predict the efficacy of new drugs. By recognizing patterns across large datasets, AI accelerates the identification of promising compounds, reducing the time and cost associated with traditional drug development processes.
This AI application is transforming personalized medicine by enabling researchers to tailor treatments to individual patients based on genetic and molecular data, making treatments more effective and targeted.
4.3. Education & Research
AI-powered academic research analysis
In education and research, AI helps scholars and researchers analyze unstructured data from academic papers, journals, and conference proceedings. AI-based tools use NLP to extract key insights and summarize lengthy texts, saving time for researchers and enabling them to focus on critical analysis rather than data gathering.
AI systems can also suggest relevant papers or research trends based on an analysis of past publications, helping researchers stay up to date with the latest developments in their field. This makes academic research more efficient and accelerates knowledge sharing across disciplines.
Automating lecture transcription & summarization
AI is also playing a crucial role in automating the transcription and summarization of lectures and educational content. Using speech-to-text technologies, AI can transcribe lectures and create concise summaries, which are especially helpful for students with disabilities or those who prefer learning at their own pace.
These AI-driven tools not only improve accessibility but also allow for faster content digestion, enabling students and researchers to focus on key takeaways from educational material rather than sifting through hours of content.
4.4. Retail & E-commerce
AI-based product recommendation using customer interactions
In the retail and e-commerce industries, AI transforms unstructured data such as customer reviews, past purchase history, and browsing behavior into actionable insights for personalized product recommendations. Machine learning algorithms analyze customer interactions to understand preferences and offer tailored product suggestions.
By incorporating customer feedback, reviews, and purchase patterns, AI can suggest products customers are likely to buy, driving higher sales and improving the shopping experience. Personalized recommendations increase customer satisfaction by making it easier for them to find products that align with their needs and interests.
Unstructured AI in demand forecasting
AI is also applied in demand forecasting by analyzing unstructured data from various sources, such as social media posts, customer feedback, and market trends. AI models can predict product demand based on consumer behavior and market dynamics, allowing retailers to optimize their inventory and avoid overstocking or stockouts.
This helps businesses plan better, reduce costs, and increase operational efficiency. Additionally, AI-driven forecasting tools ensure that retail businesses can remain agile and adapt to changes in market conditions more effectively.
4.5. Legal & Compliance
AI for contract analysis and legal document processing
In the legal industry, AI is being used to streamline the process of contract analysis and document processing. Legal professionals often deal with large volumes of unstructured data in the form of contracts, agreements, and case files. AI-driven systems can quickly analyze these documents, identify key clauses, and flag potential risks or compliance issues.
This AI technology allows law firms to automate tedious tasks, such as reviewing standard contracts and legal documents, enabling them to focus on higher-value work like strategy development and legal advisory. AI also helps improve accuracy by minimizing human error in document review.
Reducing compliance risks with AI-driven data extraction
Compliance and regulatory requirements are crucial for businesses in heavily regulated industries such as finance, healthcare, and energy. AI tools help organizations extract relevant information from unstructured data sources such as emails, reports, and contracts to ensure compliance with legal and regulatory standards.
By using AI to scan large datasets for compliance-related terms, companies can proactively address potential risks, reduce the chances of fines or penalties, and streamline reporting processes.
How AI Processes Unstructured Data
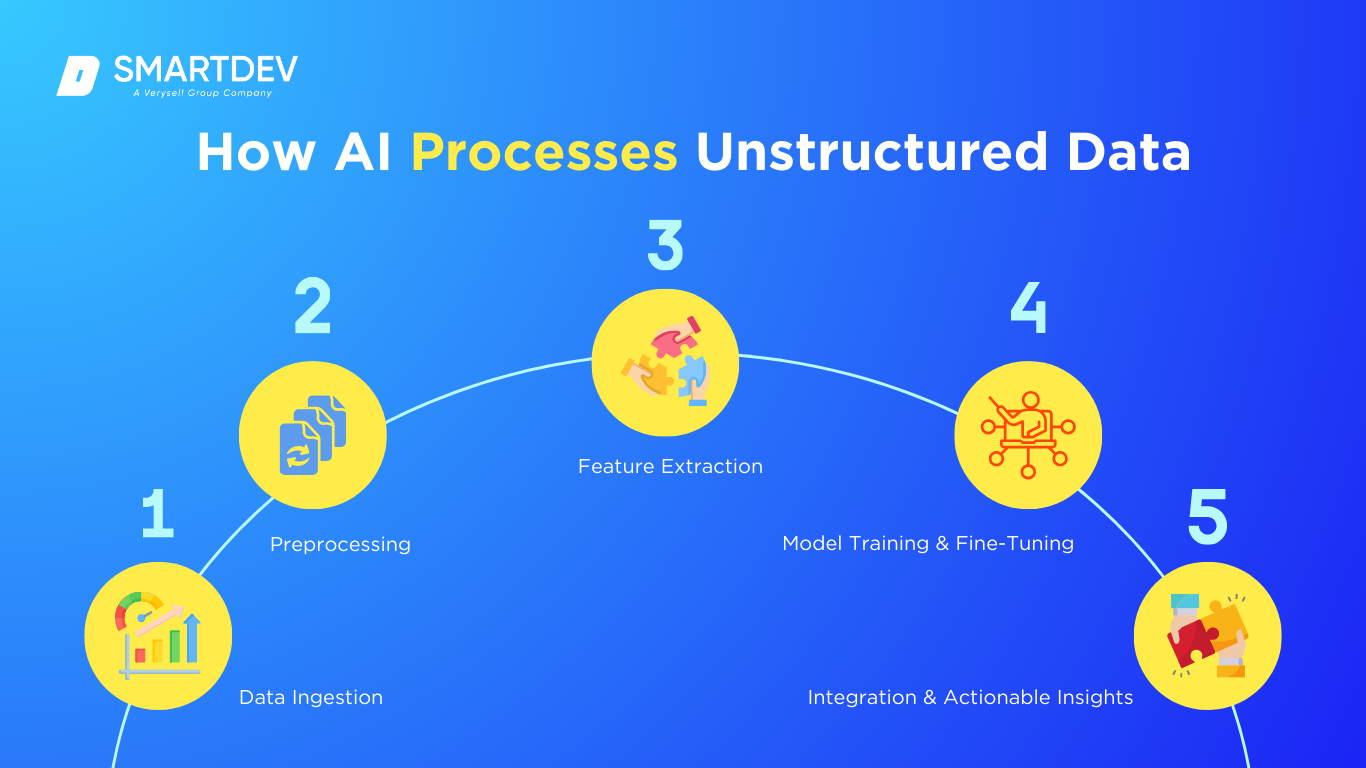 Unstructured data, such as text, images, audio, and video, is abundant across industries but can be challenging to analyze due to its lack of a predefined structure. Artificial Intelligence (AI) can process this unstructured data and derive meaningful insights that drive business decisions.
Unstructured data, such as text, images, audio, and video, is abundant across industries but can be challenging to analyze due to its lack of a predefined structure. Artificial Intelligence (AI) can process this unstructured data and derive meaningful insights that drive business decisions.
The following framework outlines the key steps AI uses to transform unstructured data into valuable insights.
Data Ingestion: Collecting unstructured data from various sources
The first step in processing unstructured data is data ingestion, where AI systems collect data from multiple sources. These sources could include:
- Textual data: Social media posts, emails, customer reviews, and documents.
- Visual data: Images, videos, and medical imaging.
- Audio data: Recordings of conversations, customer service interactions, and lectures.
- Sensor data: Information from IoT devices, such as temperature readings or motion sensors.
During this stage, AI systems gather raw data from internal databases, third-party APIs, or public data repositories. Effective data ingestion involves ensuring that data is collected in real-time or at regular intervals, depending on business needs.
Preprocessing: Cleaning deduplication and normalization
Once the data is ingested, AI systems need to clean and prepare it for further analysis. This is where preprocessing comes in. The key activities during this stage include:
- Data Cleaning: Removing or correcting inaccuracies, such as misspellings, noise, or irrelevant information. In textual data, this could mean removing stop words (e.g., “the”, “and”) or correcting grammatical errors.
- Deduplication: Identifying and removing duplicate entries. In large datasets, duplicates can distort analysis, leading to inaccurate insights.
- Normalization: Standardizing data to ensure consistency across different formats or scales. For instance, in numerical data, this could mean converting all units to a common scale (e.g., converting currency values into a single currency).
Preprocessing is crucial because clean, standardized data ensures that AI models function effectively, minimizing errors in subsequent steps.
Feature Extraction: Identifying meaningful patterns in data
Once the data is clean, the next step is feature extraction. This involves identifying and isolating the most relevant features from the unstructured data, which can be used to train AI models. In this phase:
- Textual Data: AI systems use techniques like Natural Language Processing (NLP) to extract meaningful phrases, keywords, sentiment, or named entities (e.g., names of companies, locations, dates).
- Image and Video Data: Convolutional Neural Networks (CNNs) are used to detect features such as edges, textures, and objects.
- Audio Data: Speech-to-text technology converts audio into written text, and additional features like tone, volume, and pitch are analyzed to extract sentiment or emotion.
This stage transforms raw data into structured data by identifying significant elements that can contribute to model training.
Model Training & Fine-Tuning: Using AI/ML to classify and understand data
With extracted features, the AI system moves into the next stage: model training. Here, machine learning (ML) or deep learning algorithms are applied to classify or predict outcomes based on the patterns in the data.
- Supervised Learning: If labeled data is available, AI models are trained to recognize patterns and classify data accordingly. For example, in financial document processing, the model could learn to classify invoices as “paid” or “unpaid” based on historical data.
- Unsupervised Learning: In the absence of labeled data, unsupervised learning algorithms help identify hidden patterns or clusters in the data, such as grouping similar customer feedback into themes or sentiment categories.
- Fine-Tuning: After the initial model training, AI models undergo fine-tuning to improve their accuracy. This process involves adjusting hyperparameters and running tests to refine the model’s predictions, ensuring it performs optimally for the task at hand.
This stage is critical because it allows the AI system to learn from the data, adjust its internal parameters, and make accurate predictions.
Integration & Actionable Insights: Transforming raw data into business value
Finally, once the model is trained and fine-tuned, the AI system can provide actionable insights. This step involves integrating the AI model into business workflows to generate tangible results. The insights derived from unstructured data can then be used to inform decision-making and deliver value to the business. For example:
- In Business & Finance: AI might analyze customer feedback to predict buying behavior, allowing businesses to adjust marketing strategies or launch targeted promotions.
- In Healthcare: AI could analyze medical imaging to assist in diagnosing diseases at earlier stages, improving patient outcomes and saving costs.
- In Retail: AI can recommend personalized products to customers based on their past interactions and behaviors, increasing sales and customer satisfaction.
At this stage, raw data is transformed into actionable insights that businesses can use for better decision-making, increased productivity, and competitive advantage.
AI Tools & Platforms for Unstructured Data Processing
Processing unstructured data with AI starts with choosing the right tools—and today, there’s no shortage of options.
Enterprise platforms like IBM Watson, Google Vertex AI, and OpenAI offer powerful, ready-to-deploy solutions for analyzing text, images, and speech at scale. For teams that prefer more control or flexibility, open-source tools like Hugging Face, spaCy, and Apache OpenNLP provide customizable frameworks to build tailored AI pipelines.
But picking the right platform isn’t one-size-fits-all. Your decision should align with your business needs—like the types of data you handle, how scalable your solution needs to be, and how easily it integrates with your current systems.
In this section, you will learn about:
The best AI tools and platforms for processing unstructured data
Open-source vs. enterprise-grade AI tools—what’s right for you
Key criteria to consider when evaluating AI platforms for your use case
Read on to discover which tools can power your unstructured AI journey—and how to choose the best fit for your goals.
Top AI Platforms for Unstructured Data (IBM Watson Google Vertex AI OpenAI etc.)
AI platforms provide powerful tools for processing and analyzing unstructured data. The leading platforms in the market offer advanced features like natural language processing (NLP), machine learning (ML), computer vision, and more. Here are some of the top AI platforms:
a) IBM Watson
IBM Watson is one of the most prominent AI platforms, known for its capabilities in unstructured data processing. Watson provides a suite of services such as Watson Discovery, which extracts valuable insights from unstructured data sources like documents, emails, and web pages. Watson’s NLP capabilities help organizations analyze customer feedback, sentiment, and market trends.
Key Features:
- NLP for text analysis and sentiment detection
- Watson Knowledge Studio for customizing AI models
- Watson Visual Recognition for image and video processing
- Integration with cloud platforms for scalability
IBM Watson’s extensive AI services make it ideal for enterprises seeking advanced solutions for data analytics, particularly in industries like healthcare, finance, and customer service.
b) Google Vertex AI
Google Vertex AI is a fully managed machine learning platform that provides comprehensive tools for processing unstructured data. Vertex AI integrates various Google Cloud services, enabling organizations to build, deploy, and scale AI models with ease. It provides pre-built models for NLP, image recognition, and translation, making it suitable for businesses across diverse industries.
Key Features:
- AutoML for automating model training
- Pre-built models for text and image processing
- Integration with Google Cloud storage and BigQuery
- Support for TensorFlow, PyTorch, and scikit-learn
Google Vertex AI is designed for businesses looking to leverage cutting-edge AI for a wide variety of use cases, from customer service automation to predictive analytics.
c) OpenAI
OpenAI, the organization behind GPT (Generative Pretrained Transformer) models, is renowned for its advancements in NLP and generative AI. OpenAI offers various tools like GPT-4 for natural language understanding and DALL·E for image generation, making it a great choice for businesses that need powerful AI to process and generate unstructured data.
Key Features:
- GPT-4 for text generation, summarization, and question-answering
- DALL·E for image generation from textual descriptions
- API for seamless integration with business applications
- Large-scale language model fine-tuning
OpenAI’s models are especially useful for content creation, customer service, and any applications that require advanced natural language processing.
d) Microsoft Azure AI
Microsoft Azure AI provides a range of tools for processing unstructured data, including cognitive services like text analytics, speech recognition, and computer vision. With these tools, businesses can process images, analyze social media content, and automate transcription tasks.
Key Features:
- Azure Cognitive Services for NLP, speech-to-text, and image analysis
- Customizable machine learning models
- Integration with Azure cloud services for scalability
- Pre-built models for common business use cases
Azure AI is ideal for businesses already using the Microsoft ecosystem, particularly those in industries such as healthcare, finance, and customer service.
Open-Source Tools for AI-Driven Data Processing
For businesses that prefer flexibility and customization, open-source tools provide powerful alternatives to proprietary AI platforms. These tools are free to use and can be adapted to suit specific business needs.
a) Apache OpenNLP
Apache OpenNLP is a machine learning-based toolkit for processing natural language text. It offers capabilities such as tokenization, part-of-speech tagging, named entity recognition (NER), and sentence parsing, making it ideal for extracting meaning from textual data.
Key Features:
- NLP tools for text processing
- Support for custom model training
- Ability to process large-scale text data
- Integrates well with other Apache big data tools
Apache OpenNLP is a great option for businesses looking to develop customized NLP models for text analysis in industries like finance, customer service, and legal sectors.
b) TensorFlow
TensorFlow, an open-source machine learning framework developed by Google, provides a comprehensive platform for building and training AI models. It is widely used in deep learning applications, particularly in areas like image and video processing, speech recognition, and NLP.
Key Features:
- Deep learning models for image, text, and speech recognition
- Extensive libraries and tools for custom AI model development
- High scalability for large datasets
- Support for multiple programming languages (Python, C++, JavaScript)
TensorFlow is suitable for businesses looking to develop complex AI models for unstructured data, especially when they require advanced techniques like deep learning.
c) spaCy
spaCy is a powerful and fast open-source library for NLP tasks. It is designed for processing large volumes of text and includes features like tokenization, named entity recognition (NER), text classification, and dependency parsing.
Key Features:
- High-performance NLP processing
- Pre-trained models for various languages
- Integration with machine learning frameworks like TensorFlow and PyTorch
- Easy-to-use API for text data processing
spaCy is ideal for businesses that need efficient and scalable solutions for text-based unstructured data, such as customer feedback or social media posts.
d) Hugging Face Transformers
Hugging Face provides a popular open-source library, Transformers, that focuses on advanced NLP tasks using pre-trained models like BERT, GPT, and RoBERTa. It’s designed to make it easy for developers to implement state-of-the-art NLP models for text classification, summarization, and more.
Key Features:
- Pre-trained transformer models for NLP
- Easy integration with TensorFlow and PyTorch
- Support for fine-tuning models on specific tasks
- Strong community support and extensive documentation
Hugging Face is well-suited for businesses needing high-performance text analysis models for a variety of NLP applications.
Not sure whether to go with open-source or proprietary AI tools? Explore the pros and cons of open-source vs. proprietary AI to make an informed choice for your next project.
How to Choose the Right AI Tool for Your Business Needs
When selecting an AI tool for processing unstructured data, it’s important to consider factors such as business goals, scalability, budget, and infrastructure. Here are the main points to guide your decision.
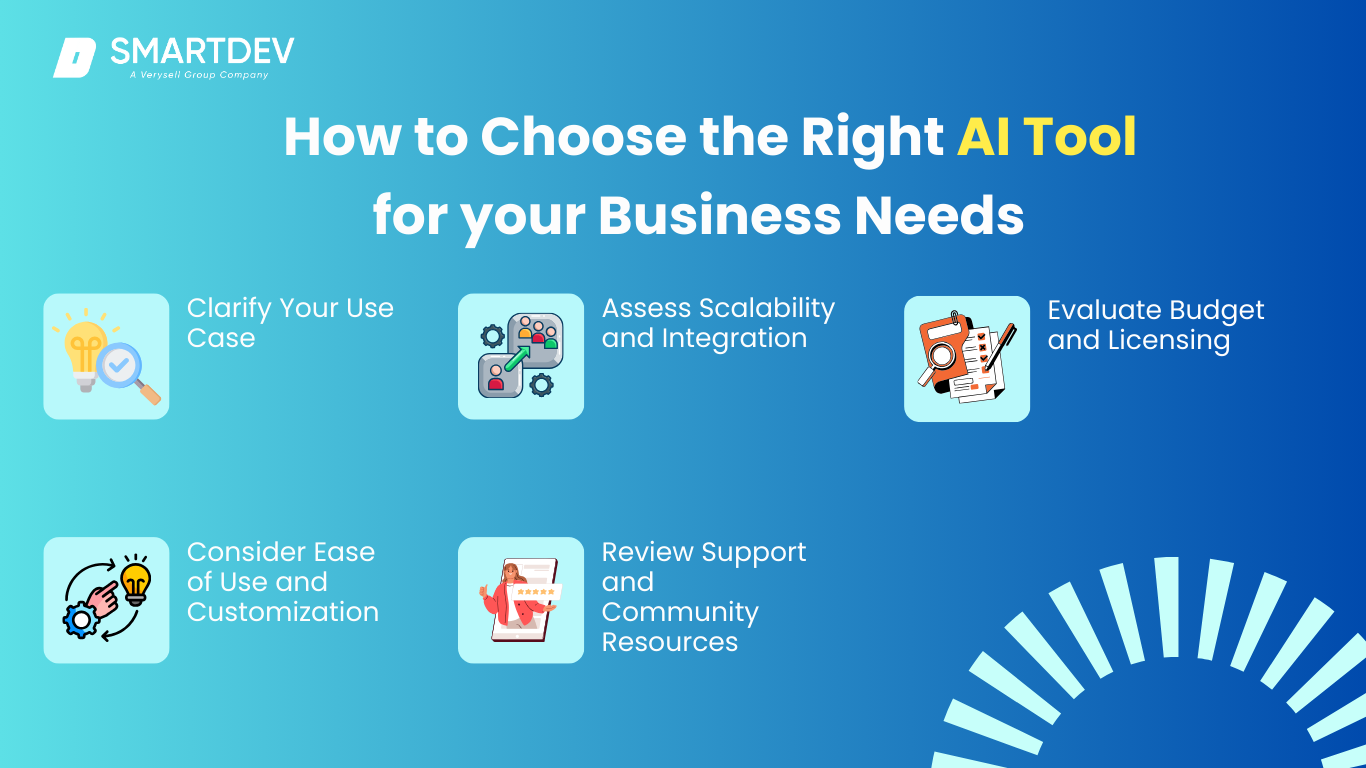 a) Clarify Your Use Case
a) Clarify Your Use Case
Identify the type of unstructured data you need to process, whether it’s text, images, or videos. Decide if your needs focus on natural language processing (NLP), computer vision, or both. Determine the insights or actions you want to extract from the data.
b) Assess Scalability and Integration
Check if the AI tool can handle the data volume and processing speed required by your business. Ensure it integrates smoothly with your current IT setup, cloud platforms, and data pipelines for effective implementation.
c) Evaluate Budget and Licensing
Open-source tools like TensorFlow or spaCy offer cost-effective solutions for small businesses. On the other hand, enterprise tools like IBM Watson or Google Vertex AI provide advanced features but come at a higher price. Weigh your budget against the tool’s capabilities.
d) Consider Ease of Use and Customization
Look for AI tools that offer pre-built models or templates suited to your needs. If you require customization, check whether the tool allows easy integration into your existing workflows and whether it supports model adjustments.
e) Review Support and Community Resources
For open-source tools, examine the community support, documentation, and ongoing development. For commercial platforms, assess the quality of customer support, training materials, and troubleshooting resources available to optimize performance.
By considering these factors, you’ll be able to choose an AI tool that aligns with your business objectives and effectively processes unstructured data.
Challenges & Limitations of Unstructured AI
While AI offers immense potential for processing unstructured data, it also comes with its own set of challenges and limitations. Understanding these hurdles is crucial for businesses to implement AI solutions effectively while mitigating risks. Below, we explore some of the primary challenges of unstructured AI.
 Data Privacy & Security Risks
Data Privacy & Security Risks
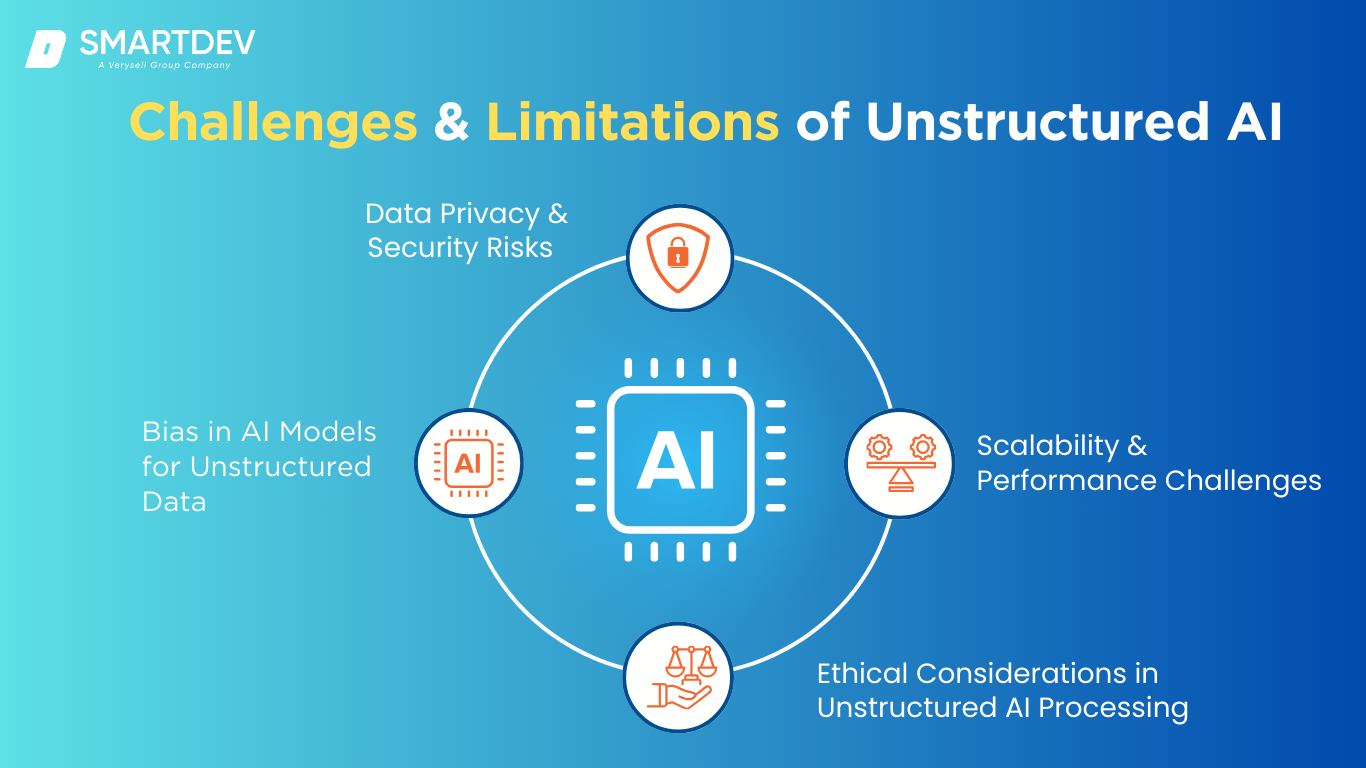 Data Privacy & Security Risks
Data Privacy & Security Risks Unstructured data often contains sensitive information, such as customer feedback, financial records, or medical data, which can present significant privacy and security risks. The use of AI to analyze such data can expose organizations to breaches, especially if proper data encryption and access controls are not implemented.
Ensuring compliance with data protection regulations like GDPR and HIPAA becomes more complex when handling large amounts of unstructured data.
Bias in AI Models for Unstructured Data
AI models can inadvertently inherit biases present in the data they are trained on. For example, if a dataset contains biased text or images, the AI model may learn and perpetuate those biases. This can lead to skewed analysis or unfair outcomes, particularly in areas like recruitment, loan approval, or healthcare diagnostics.
Identifying and mitigating bias in unstructured AI models is a significant challenge, requiring continuous monitoring and diverse, representative datasets.
Scalability & Performance Challenges
Processing large volumes of unstructured data can be resource-intensive, especially when working with complex models like deep learning algorithms. Scalability becomes a challenge as businesses expand and the amount of data grows.
AI systems must be capable of handling increasing data sizes and maintaining performance without compromising speed or accuracy. Optimizing AI tools for scalability often requires significant computational resources, making it costly for small and medium-sized enterprises (SMEs).
Ethical Considerations in Unstructured AI Processing
The ethical implications of using AI to process unstructured data are vast and can have significant societal impacts. There are concerns regarding transparency, accountability, and consent when AI systems analyze personal data.
For instance, in healthcare, AI-driven diagnostics could raise questions about the role of human oversight and the potential for errors.
Additionally, organizations must ensure that AI technologies are used responsibly and do not exploit or manipulate users’ personal data for profit or other unethical purposes.
Dive deeper into the ethics of AI development to understand how transparency and human oversight are shaping the future of AI.
Future Trends in AI for Unstructured Data
The landscape of AI in unstructured data processing is evolving rapidly, driven by advancements in technology and the growing demand for more efficient and sophisticated data analysis. As businesses continue to explore the potential of unstructured data, several emerging trends are likely to shape the future of AI in this space.
Here are some key trends to watch for in the coming years.
Generative AI’s Role in Structuring Unstructured Data
Generative AI, particularly models like GPT-4 and DALL·E, are making strides in not only generating content but also in structuring unstructured data. These models can help transform raw, unstructured data—such as text, images, and audio—into structured formats suitable for further analysis.
By automatically categorizing and organizing information, generative AI will enable businesses to streamline their workflows and extract meaningful insights more efficiently. This could significantly reduce the time and cost associated with data preprocessing, making AI even more accessible for companies dealing with large volumes of unstructured data.
AI + Quantum Computing: The Next Frontier?
The combination of AI and quantum computing holds the potential to revolutionize unstructured data processing. Quantum computing could vastly accelerate machine learning algorithms by enabling faster computation and processing of complex datasets.
Quantum computers can handle vast amounts of unstructured data simultaneously, which could vastly improve the scalability and performance of AI models.
As quantum computing becomes more practical and accessible, it could open new possibilities for AI in industries like healthcare, finance, and research, where massive datasets require rapid analysis and interpretation.
The Rise of Multimodal AI for Understanding Complex Data
Multimodal AI is an exciting trend where AI systems process and analyze multiple forms of unstructured data (text, images, audio, and video) simultaneously. This holistic approach allows AI to understand complex data sets more effectively by integrating information from different sources.
For instance, a multimodal AI system could analyze a medical record (text), medical images (MRI scans), and patient interviews (audio) to make more accurate diagnoses.
As AI technology becomes more sophisticated, multimodal models will become the norm, enabling businesses to gain deeper insights from more diverse types of unstructured data.
Predictions for AI in Unstructured Data (2025 & Beyond)
Looking ahead to 2025 and beyond, the role of AI in unstructured data processing is expected to expand significantly.
Advances in natural language processing (NLP) and computer vision will enable AI to process increasingly complex datasets, from real-time video analysis to deeper insights into human emotions and behaviors from text and audio.
Businesses will increasingly rely on AI to not only analyze unstructured data but also to automate decision-making processes, such as personalized marketing, risk assessments, and predictive maintenance.
Moreover, AI models will likely become more self-sufficient, requiring less human input to process data and generate actionable insights.
As AI continues to advance, organizations will need to be more mindful of the ethical implications, such as data privacy and bias, but the future of unstructured data processing holds vast potential for innovation and transformation across industries.
Getting Started: How to Implement AI for Unstructured Data in Your Business
Implementing AI for unstructured data processing can significantly improve your business operations, decision-making, and customer insights.
However, adopting AI solutions requires careful planning and a strategic approach. Below, we outline the key steps for effectively integrating AI to process unstructured data in your business.
Step 1: Assess Your Unstructured Data Needs
The first step in implementing AI is to understand the types and volumes of unstructured data you are working with. This could include text (e.g., emails, reviews, reports), images (e.g., product photos, medical scans), audio (e.g., customer calls, podcasts), and video (e.g., surveillance footage, advertisements). By identifying the specific needs of your business, you can determine the AI tools and technologies that best fit your requirements. Consider questions like:
- What types of unstructured data do you have?
- What insights or actions do you want to derive from the data?
- What business problems are you trying to solve with AI?
This assessment will guide your AI strategy and help you prioritize where AI can add the most value.
Step 2: Choose the Right AI Model or Platform
Once you’ve identified your data needs, the next step is selecting the appropriate AI model or platform. Depending on the type of unstructured data you’re working with, you’ll need different AI capabilities:
- For text data: Natural language processing (NLP) models (e.g., GPT, BERT) can be used for tasks like sentiment analysis, categorization, and text summarization.
- For image or video data: Computer vision models (e.g., convolutional neural networks, or CNNs) are designed for object detection, facial recognition, and image classification.
- For audio data: Speech-to-text models and sentiment analysis tools can process and extract meaning from recorded conversations or voice data.
Select a platform or model that aligns with your business objectives. Some popular AI platforms include IBM Watson, Google Vertex AI, and Microsoft Azure, while open-source options like TensorFlow, PyTorch, and spaCy offer more flexibility.
Step 3: Train Your AI Model for Optimal Performance
After selecting the right AI model or platform, the next step is training the model. This involves feeding the AI system with historical data, where the model learns to identify patterns and relationships. The quality and quantity of your data will play a major role in how well the model performs. Training an AI model typically involves:
- Data preprocessing: Clean and format your unstructured data to ensure its suitable for training.
- Model selection: Choose the right algorithm or architecture based on your use case.
- Model training: Run the model through multiple iterations, fine-tuning it to improve accuracy.
- Evaluation: Test the model’s performance using a separate validation dataset to ensure it generalizes well to new, unseen data.
Optimal training ensures that the AI model can accurately process unstructured data and generate reliable insights.
Step 4: Deploy Monitor and Optimize AI for Continuous Improvement
Once the AI model is trained, it’s time to deploy it in your business environment. Deployment typically involves integrating the AI system into your existing workflows and applications. However, deployment doesn’t end there—ongoing monitoring and optimization are crucial for success. This includes:
- Monitoring performance: Track how well the AI system performs in real-world applications, ensuring it meets business expectations.
- Optimization: Regularly update and fine-tune the model to improve accuracy, incorporate new data, and adapt to changing business needs.
- Scaling: As your data grows, scale the system to handle larger volumes of unstructured data without compromising performance.
Continuous improvement ensures that the AI system remains effective and provides lasting business value.
Case Studies: How Companies Are Successfully Using AI for Unstructured Data
In the healthcare industry, AI has proven invaluable in processing unstructured data, particularly in the form of medical images like CT scans, MRIs, and X-rays. One prominent healthcare provider implemented AI to assist radiologists in diagnosing conditions such as tumors, fractures, and other abnormalities.
The challenge was that manually analyzing large volumes of medical images was time-consuming and prone to human error. AI-based image recognition systems were introduced to speed up the diagnostic process and improve accuracy.
AI Implementation:
The healthcare provider used deep learning models, particularly convolutional neural networks (CNNs), which are highly effective in image recognition tasks. These models were trained on a vast dataset of annotated medical images, enabling them to learn to identify patterns associated with various medical conditions. The AI system was integrated into the hospital’s workflow, assisting radiologists by providing automated readings of images.
Results:
- Improved Accuracy: The AI system significantly increased the accuracy of diagnoses, especially in detecting early-stage cancers that might be overlooked by human radiologists. The AI system was able to detect tumors and other anomalies with higher precision, reducing the risk of misdiagnosis.
- Faster Diagnosis: The system dramatically speeds up the process, allowing radiologists to review and analyze more images in less time. This reduction in turnaround time led to quicker diagnosis and treatment, improving patient outcomes.
- Operational Efficiency: By automating the initial image analysis, the hospital was able to reduce the workload on radiologists, allowing them to focus more on complex cases and patient interactions.
This case study shows how AI can streamline the process of analyzing medical images, improve diagnostic accuracy, and ultimately contribute to better patient care.
Conclusion: The Future Belongs to AI-Driven Data Insights

As the digital world continues to expand, businesses are faced with an increasing volume of unstructured data. This vast wealth of information—ranging from text, images, audio, and video—holds immense potential for driving decision-making, innovation, and competitive advantage.
However, the challenge lies in transforming this unstructured data into actionable insights. This is where AI steps in, offering the ultimate key to unlocking the hidden value within unstructured data.
Why AI is the Ultimate Key to Unlocking Unstructured Data
AI, particularly through machine learning and natural language processing, is uniquely equipped to handle the complexities of unstructured data. By leveraging AI, organizations can process large volumes of unstructured data quickly and accurately, uncovering patterns, trends, and relationships that would be impossible for humans to identify manually.
AI tools, such as NLP models, computer vision algorithms, and deep learning networks, enable businesses to automate the extraction of insights from text, images, and other forms of unstructured data. As a result, AI not only enhances operational efficiency but also opens new avenues for innovation in areas like customer service, marketing, healthcare, and finance.
Moreover, AI is becoming increasingly sophisticated, enabling businesses to scale their data operations, reduce human error, and make faster, more informed decisions. With the ability to continuously learn and adapt, AI-powered systems ensure that unstructured data becomes an asset for companies, driving both short-term gains and long-term growth.
Next Steps: How to Stay Ahead in the AI-Driven Data Revolution
To stay ahead in the AI-driven data revolution, businesses must take proactive steps to harness the power of AI for unstructured data processing. Here’s how:
- Invest in AI Talent and Infrastructure: Building a strong foundation for AI starts with investing in the right technology and talent. Whether you’re working with in-house data scientists or partnering with AI consultants, having the right team in place is essential for implementing effective AI solutions.
- Start Small and Scale: Begin by experimenting with AI on a smaller scale, such as automating specific tasks like customer sentiment analysis or document categorization. As you gain confidence in your AI systems, scale them to handle larger, more complex data sets.
- Integrate AI into Business Workflows: Ensure that AI is seamlessly integrated into your existing business processes. The real value of AI lies in its ability to complement human decision-making and add value across various functions, from marketing and sales to finance and operations.
- Stay Informed and Adapt: AI is evolving rapidly. Stay informed about the latest developments in AI technologies and trends to ensure your business remains competitive. Leverage continuous learning to optimize your AI models and adapt to new opportunities.
Now is the time to begin your journey into AI-driven data insights. At SmartDev, we offer cutting-edge AI solutions tailored to your business needs, ensuring that you can unlock the full potential of your unstructured data.
From AI model development to deployment and optimization, our team of experts is ready to help you navigate the complexities of AI and take your data processing to the next level. Let us help you harness the power of AI and stay ahead in the rapidly evolving data-driven world.
Contact SmartDev today to start implementing AI solutions that drive business growth.
—
References:
- Gartner: Understanding Unstructured Data
- MIT Technology Review: Natural Language Processing
- IBM: Structured vs. Unstructured Data










