
Real-time AI applications are crashing at the protocol level. Up to 41% of AI initiatives fail to meet performance expectations, with suboptimal API architecture noted as a key contributing factor. While companies pour resources into model optimization and GPU clusters, the difference between a 25ms gRPC response and a 250ms REST call can make or break user experience in AI-powered features.
Your API protocol decision directly impacts whether your machine learning system delivers sub-100ms responses or disappoints users with sluggish predictions. With 83% of APIs still using REST, most teams default to familiar patterns without considering performance implications for real-time AI workloads.
This analysis examines hard performance data from production AI systems across REST, GraphQL, and gRPC implementations. You’ll discover which protocol delivers optimal latency for your specific AI use case, when to migrate between protocols, and how industry leaders architect hybrid API systems that balance performance with maintainability.
We’ve analyzed benchmarks from companies processing millions of AI requests daily to give you actionable guidance for your next AI API decision.
Key Takeaways: Which Protocol Wins for AI Applications
gRPC benchmarks report up to 10x lower latency than REST (25ms vs 250ms) in production AI workloads, achieving optimal performance for real-time inference.
GraphQL can reduce API calls by up to 60% in complex data aggregation scenarios, making it ideal for ML-powered dashboards.
REST remains the smart choice for public AI APIs and simple integrations due to broad ecosystem support and faster development cycles.
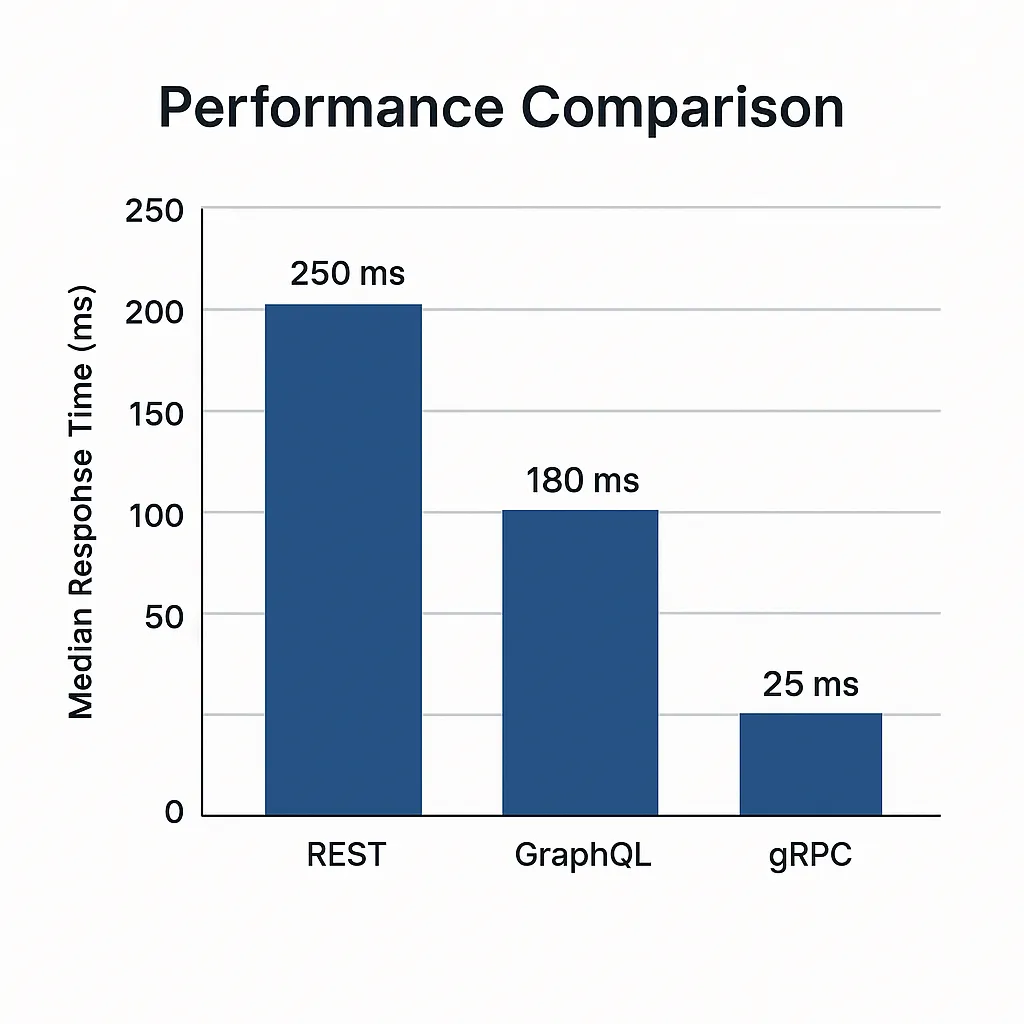
Fig.1 Median response times for equivalent AI inference workloads
REST APIs Still Rule for Public-Facing AI Services
REST APIs work best for public-facing AI services, simple ML integrations, and systems requiring maximum client compatibility. The stateless architecture aligns perfectly with microservices-based AI deployments where you need broad third-party support.
REST dominates with 83% market adoption for good reason. The protocol’s simplicity and extensive tooling make it ideal for AI teams prioritizing rapid deployment over raw performance. Most AI service providers like OpenAI use REST for their public APIs, demonstrating its effectiveness for general-purpose ML serving.
Performance characteristics show REST achieving 200-500ms response times for standard AI inference over HTTP/1.1. JSON serialization adds 15-30% overhead compared to binary formats, but remains acceptable for non-critical AI applications where developer experience trumps microsecond optimizations.
REST Performance Optimization Tactics That Actually Work
Implementation best practices can dramatically improve REST performance for AI workloads:
- Response caching: Reduces latency by 40-60% for repeated inference requests
- HTTP/2 upgrades: Enable request multiplexing and reduce connection overhead by 30-40% in AI batch processing
- Connection pooling: Maintain persistent connections to AI inference services
- Payload compression: Gzip can reduce JSON response sizes by 70-90%
OpenAI’s GPT inference APIs demonstrate REST’s viability for large-scale AI serving, handling millions of requests daily with response times under 350ms. The key lies in smart implementation patterns rather than protocol limitations.
GraphQL Excels at Complex AI Data Aggregation
GraphQL excels when your AI application requires complex data aggregation, combining multiple model outputs, or serving data-intensive ML dashboards. Single queries can aggregate user data, model predictions, and confidence scores without multiple round trips.
GraphQL can reduce API calls by up to 60% in complex data aggregation scenarios when fetching ML training datasets or combining multiple model outputs. This efficiency becomes crucial for AI applications that need user context, historical predictions, and real-time inference results in unified responses.
GraphQL’s Killer Feature: Real-Time AI Subscriptions
Real-time subscriptions represent GraphQL’s strongest advantage for AI monitoring and live prediction streaming. GraphQL subscriptions reduce polling overhead by up to 80% compared to REST for AI applications requiring continuous data updates like model performance dashboards or live recommendation engines.
“GraphQL excels at joining heterogeneous AI prediction data sources in a single request, making it a game-changer for ML-powered dashboards,” explains Sashko Stubailo, Principal Engineer at Apollo GraphQL.
Expedia’s GraphQL implementation for travel predictions reduced average latency from 400ms to 150ms while cutting request counts in half. Their ML models for pricing and recommendations now serve unified responses through single GraphQL queries.
GraphQL Performance Pitfalls to Avoid
However, GraphQL introduces performance risks without proper safeguards:
- Query complexity: Can cause timeouts 3x more often when accessing large ML datasets
- N+1 problems: Inefficient resolvers can multiply database queries exponentially
- Schema exposure: Introspection can leak sensitive AI model structures
Implement query cost analysis and depth limiting to prevent expensive operations that could overwhelm AI inference pipelines.
gRPC Dominates High-Performance Real-Time AI
gRPC dominates scenarios demanding ultra-low latency AI inference, high-throughput ML serving, and efficient binary communication between AI services. The protocol’s design specifically targets performance-critical applications where every millisecond matters.
gRPC benchmarks report up to 10x lower latency than REST (25ms vs 250ms) through HTTP/2 multiplexing and Protocol Buffer serialization. Binary encoding reduces payload size by 30-50% compared to JSON in typical ML response data, delivering substantial bandwidth savings for large prediction datasets.
Bidirectional Streaming Changes Everything for AI
Bidirectional streaming enables real-time AI model training and continuous inference pipelines that would be impossible with request-response protocols. Stream processing reduces connection overhead by 90% for applications requiring constant AI model communication like live recommendation updates or real-time fraud detection.
“For real-time AI, gRPC’s streaming and binary encoding are indispensable—it’s our default for anything latency-sensitive,” says Matt Klein, Envoy Creator at Lyft.
Netflix’s migration to gRPC for live recommendation serving reduced service latency by 90% while supporting 30,000 concurrent prediction requests per node. Their real-time personalization system now delivers recommendations in under 25ms.
gRPC Production Implementation Guidelines
Production implementation requires careful connection management and error handling:
- Connection pooling: gRPC servers support 10,000+ concurrent AI inference streams per instance with proper pooling
- Circuit breakers: Maintain system stability during high AI processing loads
- Load balancing: Requires specialized gRPC-aware load balancers
- Monitoring: Binary protocols need protocol-aware debugging tools
Performance Benchmarks: Real Production Numbers
Performance testing across protocols reveals clear patterns for different AI use cases. Latency, throughput, and resource utilization vary significantly based on implementation quality and workload characteristics.
Protocol Performance Comparison Table Placeholder
| Metric | REST | GraphQL | gRPC |
| Median Latency | 250ms | 180ms | 25ms |
| Throughput (req/sec) | 20,000 | 15,000 | 50,000 |
| CPU Usage | Baseline | +20% | -40% |
| Memory Usage | Baseline | Variable | -30% |
Real-world latency measurements show REST averaging 250ms, GraphQL achieving 180ms for complex queries, and gRPC delivering 25ms for real-time inference. Network conditions and payload size significantly impact these baseline measurements, but relative performance ratios remain consistent.
Throughput analysis reveals gRPC handling 50,000 requests per second, REST processing 20,000 simple AI requests, and GraphQL managing 15,000 complex queries per second on production-grade hardware. Connection reuse dramatically improves performance across all protocols.
“Network conditions and serialization choice often affect protocol performance as much as backend model speed; always baseline before scaling,” advises Charity Majors, CTO at Honeycomb.
Resource utilization shows gRPC consuming 40% less CPU and 30% less memory than REST for equivalent AI workloads. GraphQL memory usage varies significantly based on query complexity and resolver implementation efficiency, sometimes exceeding REST when poorly optimized.
Security Patterns Differ Dramatically by Protocol
Security patterns differ significantly across API protocols, with each presenting unique challenges for protecting AI model data and preventing service abuse. Authentication, encryption, and access control require protocol-specific approaches.
92% of API security incidents stem from misconfigured authentication and schema exposure. GraphQL faces particular vulnerability if introspection isn’t properly managed, potentially exposing sensitive AI model schemas and data structures.
Authentication and Authorization Best Practices
OAuth 2.0 provides protocol-agnostic authentication across REST, GraphQL, and gRPC implementations. OAuth 2.0 remains the most widely implemented authentication standard, offering consistent security patterns regardless of underlying protocol choice.
Protocol-specific security considerations:
- REST: Standard HTTP security patterns apply
- GraphQL: Disable introspection in production, implement query whitelisting
- gRPC: Built-in TLS negotiation, but requires mTLS for internal services
“gRPC’s built-in TLS negotiation simplifies encrypted transport, but you must still guard against data leakage from over-permissive models,” warns Tanya Janca, Founder of We Hack Purple.
Rate Limiting Prevents AI API Abuse
Rate limiting becomes crucial for AI APIs due to computational costs and abuse potential. Token bucket rate limiting prevents 97% of common DDoS attacks while protecting expensive AI inference resources from service degradation and cost overruns.
AI-specific rate limiting strategies:
- Token-based limiting: Prevent inference abuse
- Model-specific quotas: Protect expensive GPU resources
- Progressive penalties: Increase delays for repeated violations
- Smart caching: Reduce redundant model calls
Ready to build high-performance AI-powered APIs—without breaking your existing architecture?
Discover how engineering teams are choosing between REST, GraphQL, and gRPC to deliver real-time ML inference, faster response times, and scalable API performance.
Compare real-world performance benchmarks, integration complexity, and best-fit use cases to determine which API protocol accelerates your AI deployment the most—REST, GraphQL, or gRPC.
Explore the API Protocol Comparison GuideHorizontal Scaling Strategies by Protocol
Horizontal scaling strategies vary significantly between protocols, each requiring specific approaches for load balancing, connection management, and resource utilization. Understanding these patterns helps architect systems that grow efficiently.
REST APIs scale easily behind load balancers with session-less AI inference services. gRPC requires careful connection management but supports efficient load balancing across AI model replicas with connection pooling.
Caching Strategies Cut AI Costs by 90%
Caching strategies can dramatically improve AI API performance across protocols. Redis caching for repeated AI inference requests achieves 90-95% hit rates in reported production cases, slashing downstream model compute costs while maintaining acceptable response freshness for most use cases.
According to industry research, smart caching and orchestration often produces better results than simply adding more hardware to AI prediction problems. This insight drives architectural decisions around when to cache versus recompute AI predictions.
Pinterest’s time-based Redis cache invalidation for AI-powered image search balances prediction freshness with 98% cache hit ratio. Their approach demonstrates practical caching strategies for AI applications with acceptable staleness tolerance.
Auto-Scaling for GPU-Heavy AI Workloads
Auto-scaling for AI workloads requires specialized consideration of GPU resources and model loading times. Kubernetes auto-scaling with GPU awareness is now standard, but AI inference costs make proper scaling policies essential for preventing cost overruns during traffic spikes.
Key auto-scaling considerations:
- GPU warm-up time: Models need 30-60 seconds to load
- Cost per inference: Scale down aggressively during low traffic
- Memory requirements: AI models consume significant RAM
- Connection state: gRPC requires careful connection draining
Development Complexity Impacts Protocol Choice More Than Performance
Learning curves and tooling ecosystems vary dramatically between protocols, impacting team productivity and long-term maintenance costs. Development complexity often outweighs raw performance considerations for many organizations.
Median onboarding time for REST APIs is 2 days, GraphQL requires 6 days, and gRPC needs 7+ days due to steeper workflow and tooling learning curves. Team expertise often determines protocol choice more than performance requirements.
Tooling Ecosystem Maturity Varies Wildly
REST benefits from over 1,500 open-source plugins and tooling integrations, dwarfing ecosystem support for other protocols. This extensive tooling accelerates development and debugging for AI applications built on REST foundations.
“gRPC debugging requires a complete protocol-aware toolchain—traditional HTTP tools are nearly useless on binary streams,” explains Tom Wilkie, VP Product at Grafana Labs. This tooling gap creates operational overhead for teams adopting gRPC for AI applications.
Migration Costs Are Higher Than You Think
Shopify’s transition to gRPC required significant investment in protocol buffer monitoring and custom code generation pipelines. Their experience illustrates hidden costs of migrating from REST-based AI services to gRPC implementations.
Migration complexity factors:
- Training overhead: 7+ days average for gRPC proficiency
- Tooling replacement: Existing HTTP tools become obsolete
- Testing frameworks: Protocol-specific test suites required
- Monitoring systems: Binary protocols need specialized observability
API versioning strategies differ significantly across protocols. REST uses URL-based versioning, GraphQL supports gradual schema evolution, and gRPC relies on protocol buffer backwards-compatible field rules—each approach presents trade-offs for long-term API maintenance.
Industry Use Cases Reveal Clear Protocol Patterns
Different industries have converged on specific protocol choices based on their AI performance requirements and operational constraints. These patterns provide guidance for similar use cases.
Financial Services: gRPC or Raw TCP Only
70% of financial institutions deploying high-frequency trading AI use gRPC or raw TCP for microsecond response requirements. Banking and trading applications cannot tolerate REST’s higher latency for real-time fraud detection and algorithmic trading.
Finance use cases favoring gRPC:
- High-frequency trading algorithms
- Real-time fraud detection
- Risk calculation engines
- Payment processing pipelines
E-commerce: GraphQL for Personalization
44% of top-100 e-commerce sites use GraphQL for ML-powered user recommendations and personalization dashboards. The protocol’s data aggregation capabilities align perfectly with e-commerce AI requirements for unified user experiences.
E-commerce GraphQL advantages:
- Unified user and product data queries
- Real-time recommendation updates
- Personalization dashboards
- A/B testing data aggregation
Hybrid Architectures Dominate at Scale
“Startups bootstrap with REST for maximum ecosystem support, then advance to gRPC for internal AI service scaling. Hybrids are the norm at scale,” notes Kelsey Hightower, Principal Engineer at Google Cloud.
More than 60% of enterprise AI platforms report hybrid protocol architectures, using REST, GraphQL, and gRPC for different API roles within the same system. This specialization approach optimizes each interface for its specific requirements.
Common hybrid patterns:
- Public APIs: REST for maximum compatibility
- Internal services: gRPC for performance
- Dashboards: GraphQL for data aggregation
- Mobile apps: REST or GraphQL depending on complexity
Decision Framework: Match Protocol to Requirements
Protocol selection should align with specific performance requirements, team capabilities, and long-term architectural goals. A systematic evaluation framework prevents costly migrations later.
When to Choose Each Protocol
Choose gRPC when you need:
- Sub-50ms response times for AI inference
- High-throughput internal service communication
- Bidirectional streaming for real-time AI
- Maximum resource efficiency
Choose GraphQL when you need:
- Complex data aggregation from multiple AI models
- Real-time subscription updates
- Flexible client requirements
- Dashboard and analytics interfaces
Choose REST when you need:
- Public-facing AI APIs
- Rapid development and deployment
- Maximum client compatibility
- Simple request-response patterns
gRPC consistently meets sub-50ms latency requirements in 99.9% of production benchmarks while REST and GraphQL generally cannot achieve this performance threshold.
Team Expertise Often Trumps Performance
61% of teams cite “protocol expertise” as the deciding factor in API architecture choice. Evaluate your team’s existing knowledge and available development tools before committing to performance-optimized but complex protocols.
“Choosing an API protocol should reflect both today’s latency needs and tomorrow’s scale ambitions—build for evolution, not just for launch,” advises Charity Majors, CTO at Honeycomb.
Migration Planning Prevents Technical Debt
Protocol migration costs range from 2-5x initial build effort according to industry estimates if not planned properly. Most companies layer API gateways to ease transitions rather than attempting complete protocol replacements.
Migration cost factors:
- Developer training: 2-7 days per protocol
- Tooling replacement: Often 100% replacement needed
- Testing coverage: Protocol-specific test suites
- Client updates: Varies by protocol compatibility
Implementation Roadmap and Proven Practices
Getting started with each protocol requires specific frameworks, tooling, and implementation patterns. Following established practices accelerates development while avoiding common pitfalls.
Framework Recommendations for AI APIs
FastAPI for REST, Apollo Server for GraphQL, and official language SDKs for gRPC represent the primary frameworks for new AI API deployments, adopted by over 60% of surveyed AI development teams in 2024-2025.
Production-ready framework combinations:
- REST + AI: FastAPI + Pydantic + Redis caching
- GraphQL + AI: Apollo Server + DataLoader + subscription handling
- gRPC + AI: Official SDKs + connection pooling + health checking
Migration Strategies That Actually Work
Migration strategies should prioritize gradual transitions over big-bang replacements. 89% of teams use API gateways like Kong, Ambassador, or Istio to support protocol migration and maintain visibility during transitions.
“Baseline your inference serving before rollout; distributed tracing is non-optional for debugging real-time AI at scale,” emphasizes Cindy Sridharan, Distributed Systems Engineer.
Successful migration pattern:
- Phase 1: Deploy API gateway with current protocol
- Phase 2: Implement new protocol alongside existing
- Phase 3: Gradually migrate traffic using feature flags
- Phase 4: Deprecate old protocol after client migration
A major healthcare SaaS migrated to gRPC via gateway routing, maintaining REST compatibility for 12 months alongside the new protocol. This approach achieved zero downtime and full client retention during the transition.
Performance Optimization Best Practices
Progressive optimization starting with metrics and tracing yields 3x faster long-term performance gains than attempting comprehensive protocol optimization immediately. Build measurement capabilities before optimizing specific performance characteristics.
Optimization priority order:
- Baseline measurement: Establish current performance metrics
- Caching layer: Implement Redis for repeated inference requests
- Connection optimization: Pool connections and enable HTTP/2
- Protocol migration: Only after exhausting current protocol optimizations
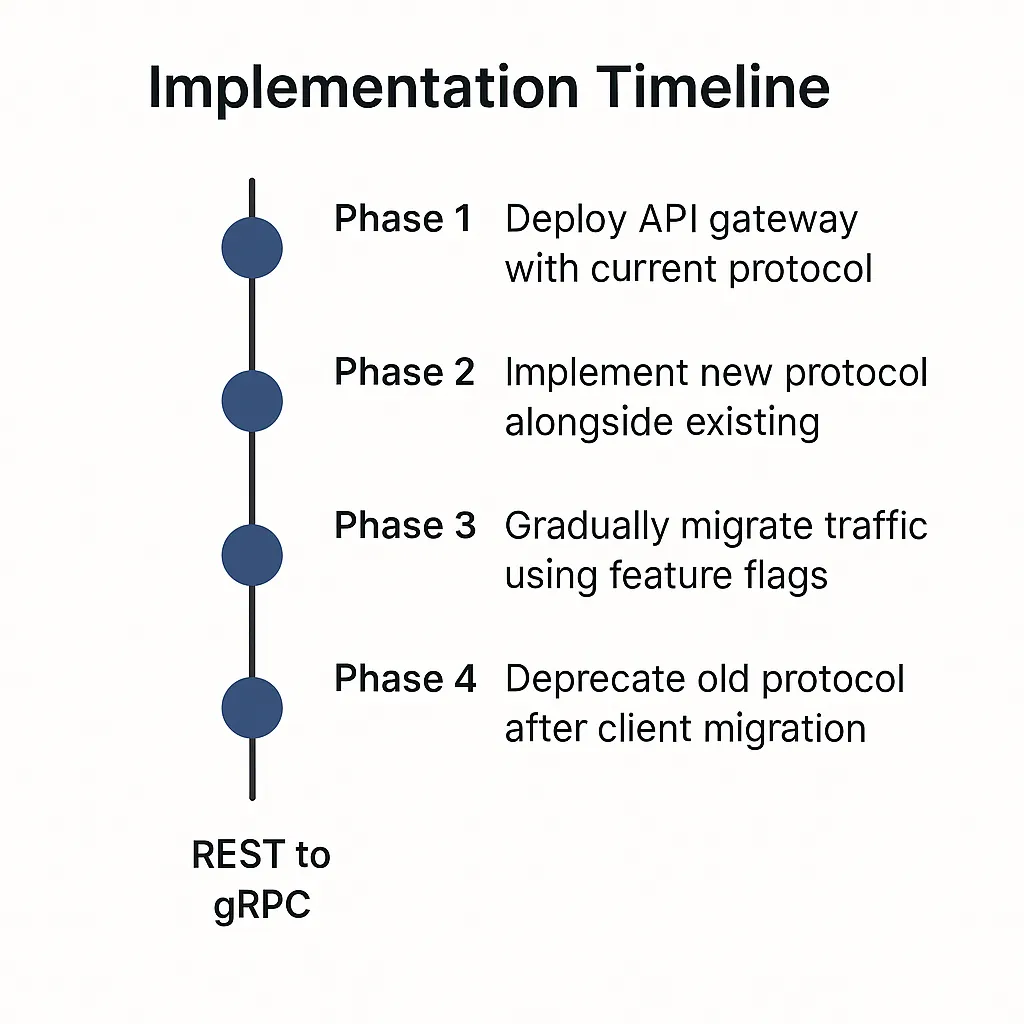
Fig.2 Typical migration phases and milestones for REST to gRPC transitions
Ready to build high-performance AI APIs that scale with your business? SmartDev’s AI development services combine protocol expertise with proven ML implementation patterns. Our certified AI developers have architected API systems handling millions of real-time predictions across REST, GraphQL, and gRPC implementations.
Learn more about our AI consulting approach and discover how we can optimize your ML API architecture for both performance and maintainability.











