Training an AI model isn’t just a technical step—it’s the foundation of everything your AI can achieve. Whether you’re building smarter recommendations, automating decisions, or generating content, success starts with effective AI model training. In this guide, you’ll get a clear, actionable breakdown of how models learn, the tools you need, and how to overcome the biggest training challenges.
Ready to build models that actually deliver results?
Let’s dive in.
As you dive into the intricacies of AI model training, it’s clear that successful outcomes depend on more than just algorithms—they require a holistic approach to development and deployment. To see how organizations are transforming advanced models into real-world solutions, explore our ai-driven software development services designed to accelerate innovation and deliver measurable business value.

What is AI Model Training?
AI model training is the process where algorithms learn from large datasets to identify patterns and make decisions. It teaches machine learning models to process data, recognize features, and produce accurate outputs, forming the foundation for AI applications across industries.
The Role of AI Model Training in the Machine Learning Lifecycle
AI model training is a key phase in the machine learning lifecycle, which includes data collection, preprocessing, model selection, training, evaluation, and deployment. During training, the model adjusts its parameters to learn from data, influencing its performance and ability to generalize to new data.
Why AI Model Training Matters for Model Performance
The success of an AI model depends on its training. Proper training ensures accurate predictions and the ability to handle diverse scenarios. Inadequate training can result in errors, biases, and inefficiencies, undermining the model’s effectiveness in real-world applications.
The Evolution of AI Model Training
AI model training has evolved from rule-based systems to data-driven approaches, with deep learning marking a key advancement. Techniques like reinforcement learning, transfer learning, and unsupervised learning have further expanded AI capabilities, enabling models to learn from more complex and dynamic data.
1. Foundations of AI Model Training
1.1 How AI Models Learn: The Basics of Training
At the heart of AI model training is the ability of machines to learn from data and make decisions based on patterns observed during training. This process can be likened to how humans learn, but at a much faster scale and complexity.
The goal is for the model to refine its internal parameters through repetitive adjustments, gradually improving its ability to make predictions or classifications based on new data.
Data as the Foundation of AI Training
Data is the bedrock of any AI model’s learning process. Without a large and diverse dataset, an AI model cannot effectively learn to recognize patterns or make accurate predictions. The quality, variety, and quantity of data directly influence how well the model performs. In most AI applications, data is collected from various sources, cleaned, and then processed to be fed into the model.
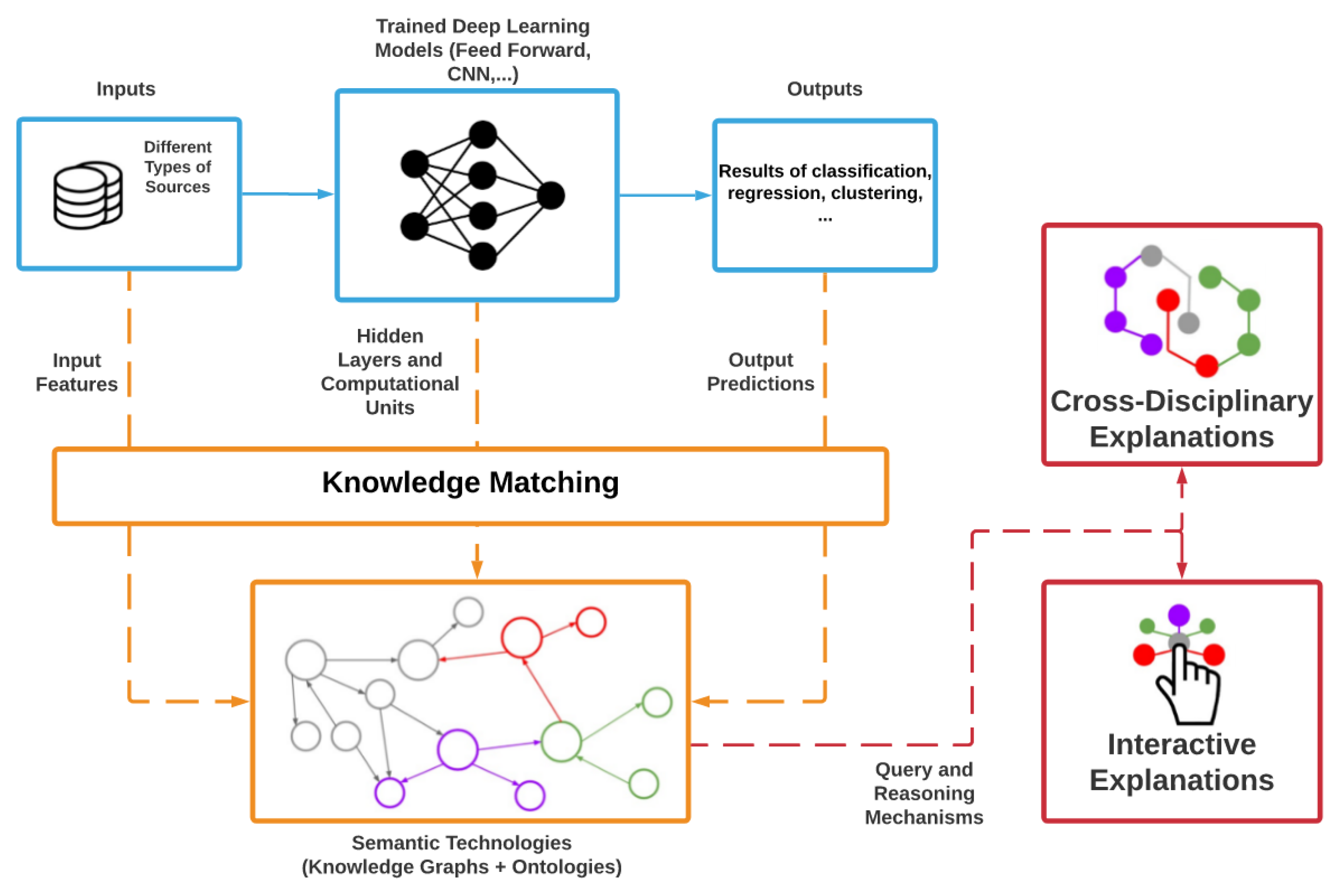
The process of machine learning
Understanding Algorithms, Parameters, and Features
Algorithms in AI model training are the mathematical models or sets of rules that guide how data is processed. Parameters are the internal variables that the model adjusts during training to minimize errors and improve its predictions. Features refer to the individual attributes or characteristics of the data that are used by the model to make decisions. Together, algorithms, parameters, and features form the building blocks that allow the AI model to learn and improve over time.
The Concept of Training, Validation, and Testing Sets
AI models typically operate on three distinct sets of data:
- Training Set: The dataset used to train the model, helping it learn patterns and adjust parameters.
- Validation Set: A separate set of data used to evaluate the model’s performance during training, ensuring it generalizes well to new data.
- Testing Set: After training and validation, the model is evaluated on a testing set, which simulates real-world data to assess its final performance.

These three sets help mitigate overfitting (where a model becomes too specialized to the training data) and underfitting (where a model fails to capture key patterns), ensuring a balanced and effective model.
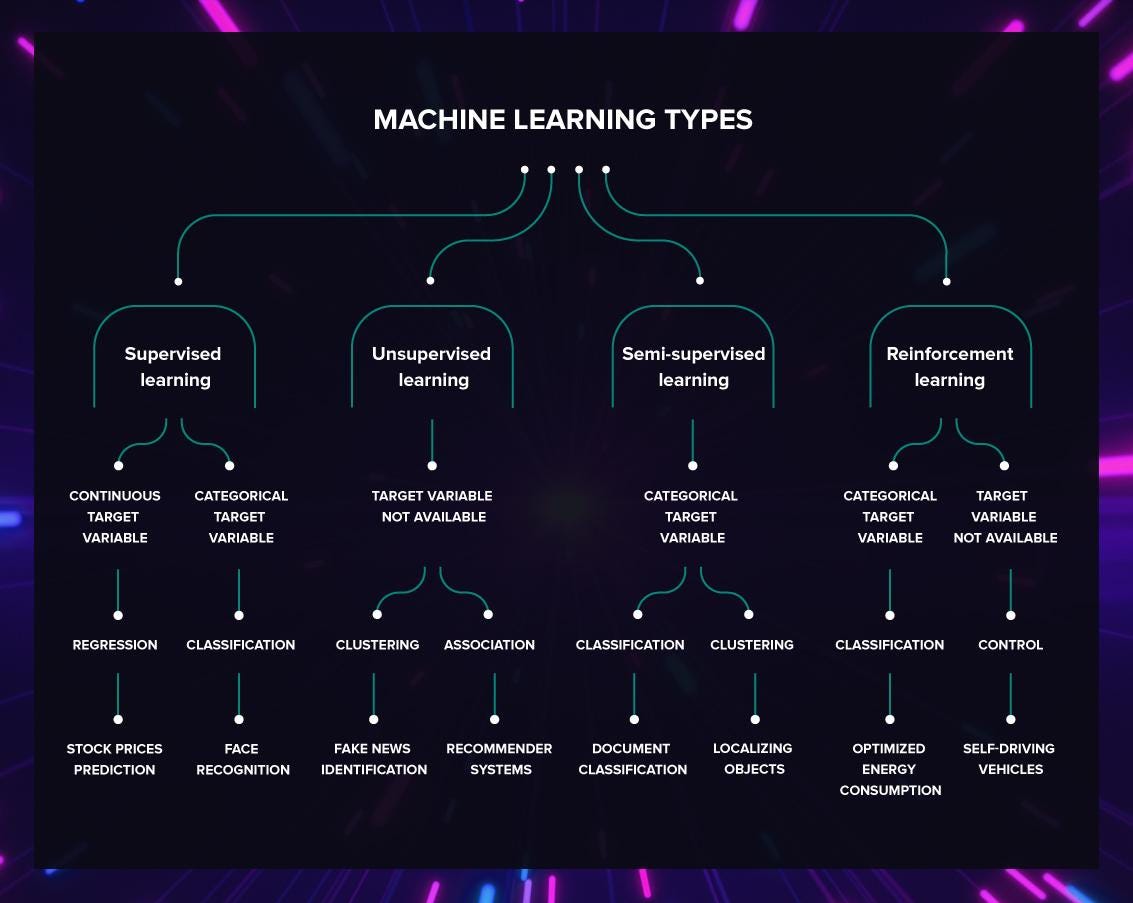
1.2 Types of AI Model Training
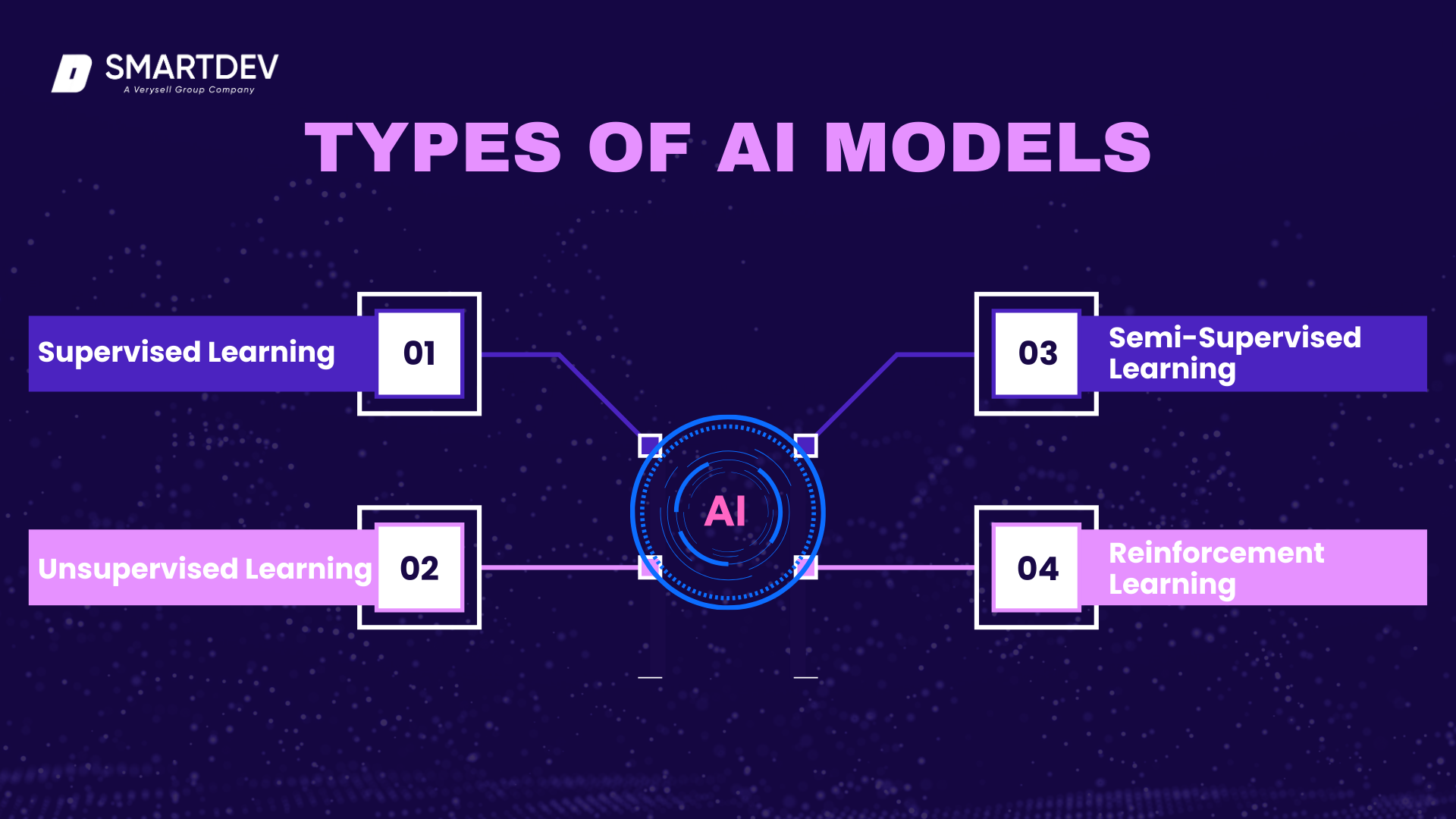
Supervised Learning
Supervised learning is one of the most common AI training methods, where the model is trained using labeled data. Each input is paired with the correct output, and the model learns to map inputs to outputs by adjusting its parameters based on error correction.
This approach is widely used in tasks such as classification and regression, where the goal is to predict specific outcomes, such as diagnosing diseases from medical images or predicting house prices based on historical data.
Unsupervised Learning
Unlike supervised learning, unsupervised learning involves training a model with data that has no labeled outputs. The goal here is to identify patterns, structures, or groupings within the data, such as clustering similar data points together or discovering hidden relationships between variables.
Unsupervised learning is often applied in areas like market segmentation, anomaly detection, and data compression.
Semi-Supervised Learning
Semi-supervised learning combines elements of both supervised and unsupervised learning. It uses a small amount of labeled data and a large amount of unlabeled data to train the model. This approach is beneficial when acquiring labeled data is expensive or time-consuming, as it allows the model to make use of a broader range of data for training.
Semi-supervised learning is increasingly being used in applications like image recognition and natural language processing.
Reinforcement Learning
Reinforcement learning (RL) is a unique type of model training where an agent learns by interacting with an environment. The agent takes actions, receives feedback (rewards or penalties), and learns through trial and error to optimize its decision-making over time.
This method is particularly useful in applications such as robotics, gaming, and autonomous driving, where the AI needs to navigate complex environments and make dynamic decisions.
1.3 Key Components in AI Model Training
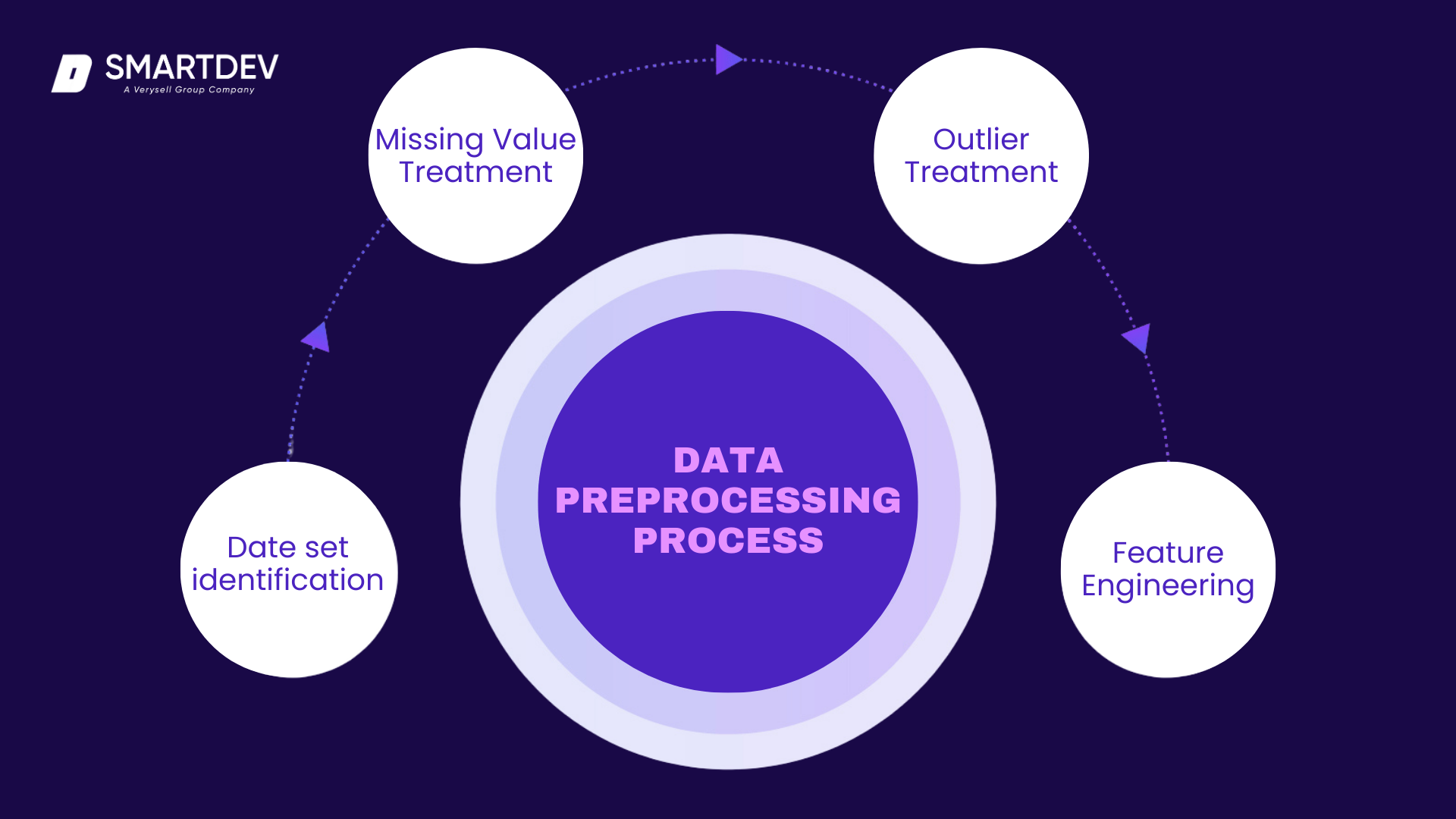
Training Data: Importance, Collection, and Preprocessing
The quality and quantity of the training data are critical to the success of AI model training. Proper data collection ensures that the dataset is diverse and representative of real-world scenarios. Preprocessing steps, such as cleaning (removing duplicates or irrelevant data) and feature engineering (creating new variables from raw data), are also essential for improving the model’s ability to learn effectively.
Algorithms: Choosing the Right Model for Your Use Case
Selecting the appropriate algorithm is crucial for successful model training. The choice of algorithm depends on the type of data, the task at hand, and the desired outcome.
For instance, deep learning algorithms are often used for image and speech recognition tasks, while decision trees and support vector machines are better suited for classification tasks with structured data. Understanding the strengths and limitations of different algorithms is key to optimizing model performance.
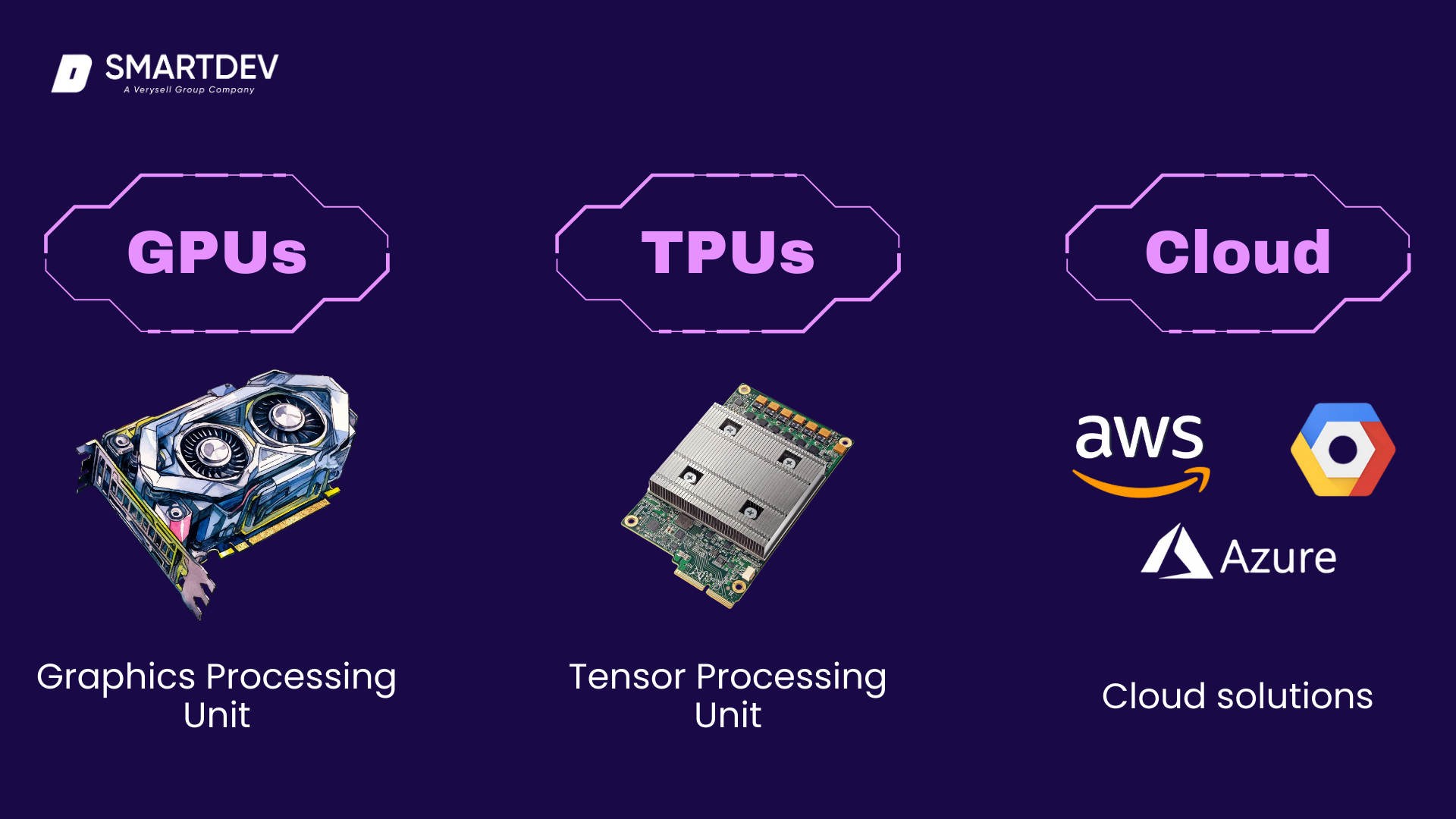
Hardware Requirements: GPUs, TPUs, and Cloud Solutions
Training AI models, especially deep learning models, requires significant computational power. Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) are designed to accelerate the computational tasks involved in training AI models, enabling faster processing of large datasets and more efficient model training.
Cloud solutions, like Amazon Web Services (AWS), Google Cloud, and Microsoft Azure, offer scalable resources for training models at scale, providing cost-effective options for businesses looking to leverage the power of AI without investing in expensive hardware.
2. The AI Model Training Workflow

2.1 Step-by-Step Guide to Training an AI Model
Training an AI model involves a structured workflow, where each step is essential for achieving optimal performance. Below is a detailed breakdown of the critical stages involved in the training process.
- Step 1: Define the Problem and Objectives
Before beginning the training process, it is crucial to clearly define the problem that the AI model will solve and set specific, measurable objectives. Understanding the problem ensures that the model’s capabilities align with the intended outcome, whether it’s classifying images, predicting trends, or optimizing a process.
Setting clear goals also helps determine the metrics by which the model’s success will be measured, such as accuracy, precision, or recall.
- Step 2: Prepare the Data (Cleaning, Labeling, and Preprocessing)
Data preparation is one of the most time-consuming but essential steps in the model training process. Raw data often needs significant cleaning and preprocessing to ensure it’s in a usable form. This includes removing duplicates, handling missing values, and normalizing or scaling the data to ensure consistency across features.
Additionally, data labeling is necessary for supervised learning, where each data point must be paired with the correct output. Preprocessing also includes splitting the data into training, validation, and testing sets to prevent overfitting and underfitting.
- Step 3: Select an Algorithm or Framework
Once the data is prepared, selecting the right algorithm or framework for the task is key to the model’s success. Different algorithms are suited to different types of problems.
For instance, deep learning frameworks like TensorFlow or PyTorch are commonly used for tasks like image recognition, while traditional algorithms such as decision trees or support vector machines (SVMs) may be more appropriate for classification tasks with structured data. The chosen algorithm should align with the nature of the problem and the characteristics of the data.
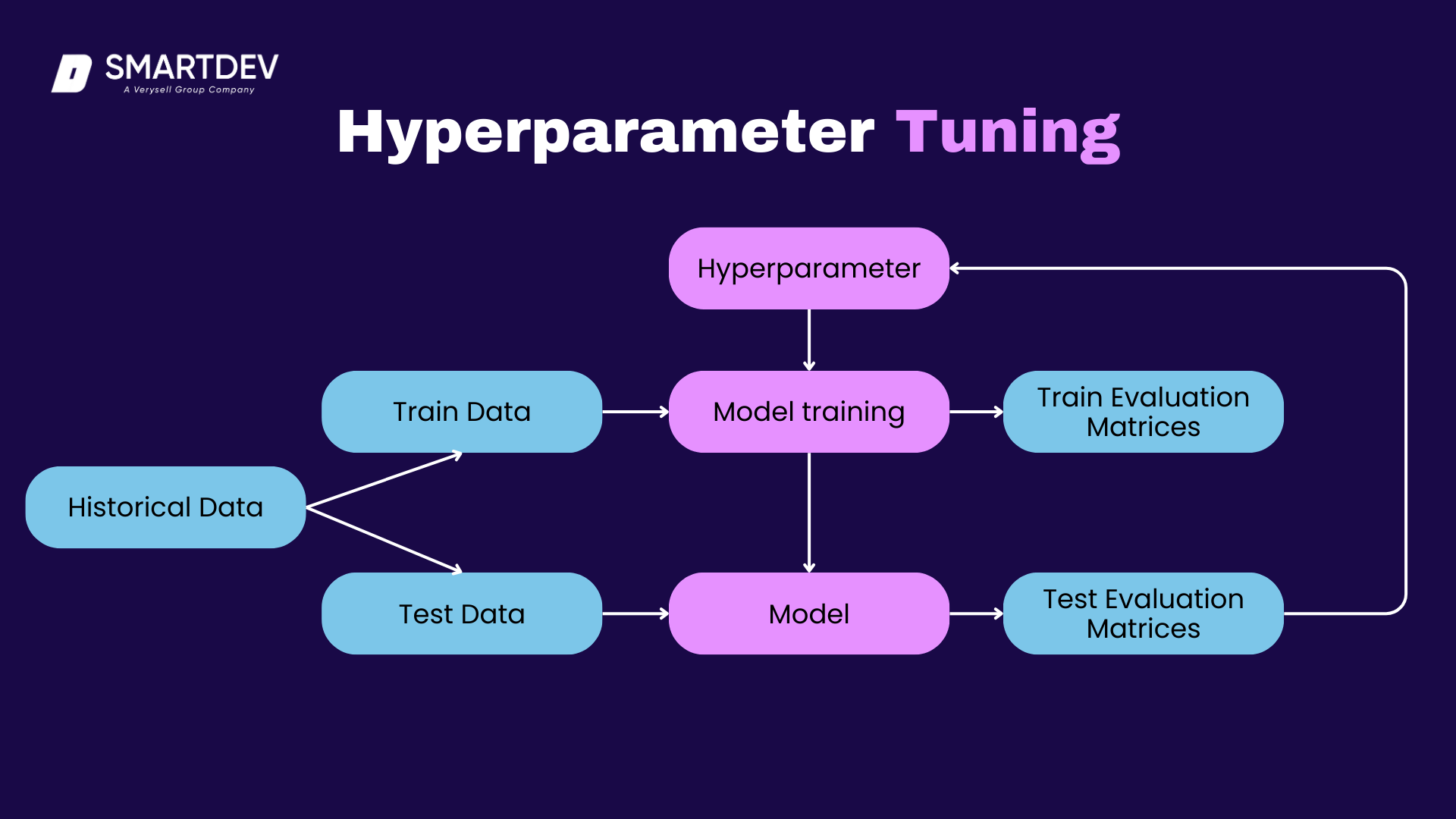
- Step 4: Train the Model (Hyperparameter Tuning and Iteration)
With the algorithm in place, the next step is to train the model. During this phase, the model learns from the training data by adjusting its internal parameters through optimization techniques such as gradient descent. Hyperparameter tuning is a critical aspect of model training, as these parameters (such as learning rate or batch size) control the model’s behavior and performance. Iteration, where the model is trained over multiple epochs, allows the model to refine its predictions. Techniques such as cross-validation can help find the optimal balance between model complexity and generalization.
Step 5: Evaluate Model Performance
Once the model has been trained, it’s essential to evaluate its performance using the validation and testing datasets. Various metrics are used to assess performance, such as accuracy, precision, recall, and F1-score. Evaluating model performance helps identify whether the model is overfitting, underfitting, or achieving its objectives. If the results are unsatisfactory, the process may require going back to adjust the data preparation, algorithm choice, or model parameters.
2.2 Data Preparation for Model Training
Importance of High-Quality Data
High-quality data is the foundation of any successful AI model. Models trained on clean, representative, and diverse data will be better equipped to make accurate predictions on new data.
Low-quality data—such as incomplete, biased, or noisy data—can lead to poor model performance and unreliable predictions. As such, data quality should be carefully considered during every stage of the data preparation process.

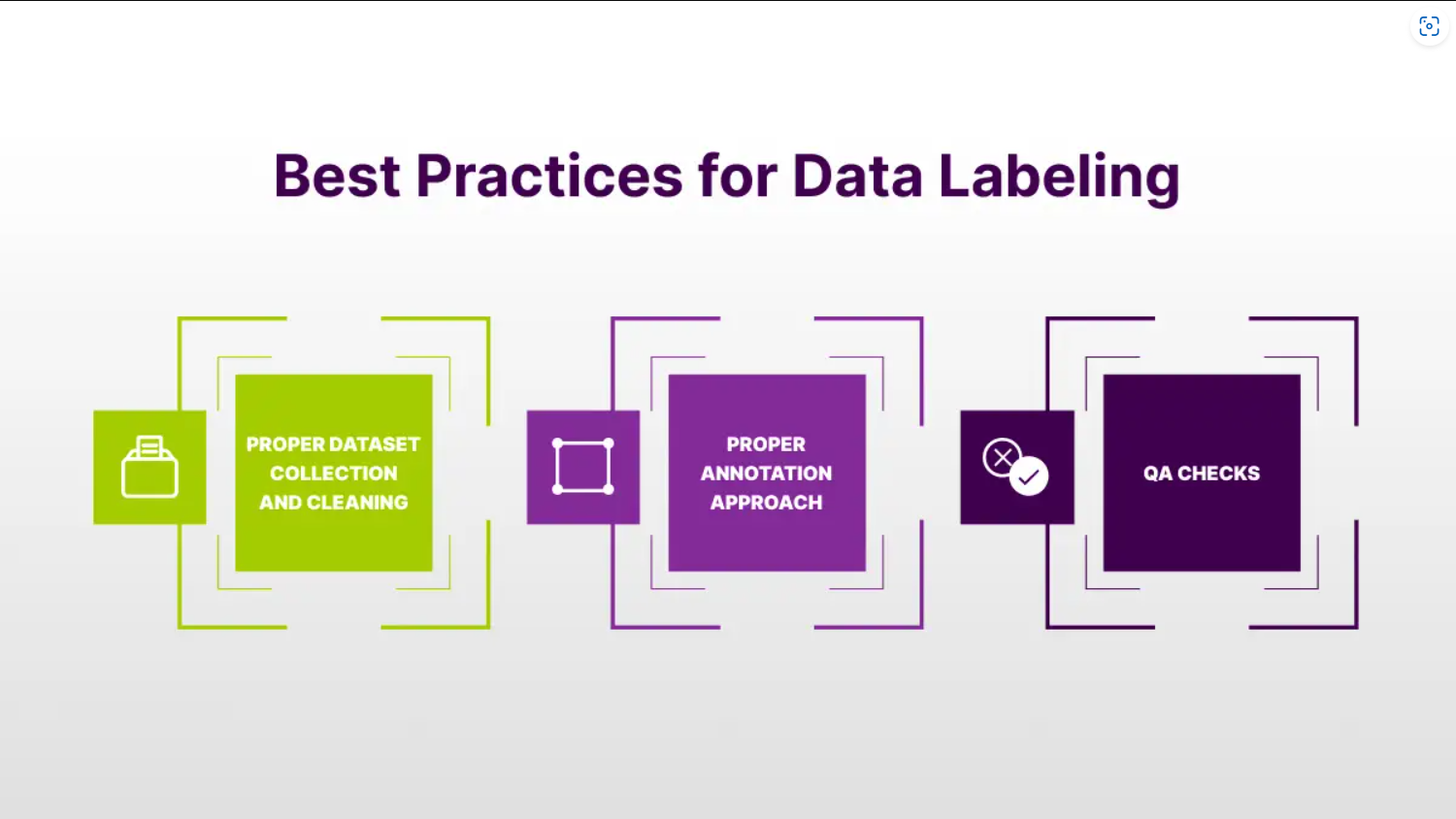
Data Labeling Techniques and Tools
Labeling data is crucial for supervised learning, where each data point must be matched with a corresponding label. Several techniques and tools are available for data labeling, ranging from manual labeling by human annotators to semi-automated tools that use AI-assisted methods to speed up the process.
Labeling can be done for various tasks, such as classifying images, tagging text, or identifying key objects in video sequences. Automated tools, such as Amazon Mechanical Turk or specialized data-labeling platforms, can help scale this process efficiently.
Data Labeling best practices
Balancing and Augmenting Training Datasets
In many cases, training datasets may be imbalanced, with one class or category dominating the data. This can lead to biased models that perform poorly on underrepresented classes. Balancing techniques, such as oversampling the minority class or undersampling the majority class, can help address this issue.
Data augmentation, a technique that artificially expands the dataset by applying transformations (like rotations, flipping, or noise injection), is also commonly used to improve model robustness and prevent overfitting. By increasing the diversity of the training data, these techniques ensure that the model learns to generalize well to unseen data.
3. Advanced Techniques in AI Model Training
3.1 Hyperparameter Tuning for Optimal Results
What are Hyperparameters?
Hyperparameters are the parameters that control the training process of an AI model, but unlike the model’s internal parameters (such as weights and biases), hyperparameters are set before the training process begins and are not updated during training.
These include settings like the learning rate, batch size, number of layers, and activation functions in a neural network. Hyperparameters play a crucial role in determining how well the model learns and generalizes to new data.
Manual vs. Automated Hyperparameter Optimization (Grid Search, Bayesian Optimization)
There are two primary methods for tuning hyperparameters: manual and automated.
- Manual Hyperparameter Optimization: This involves adjusting hyperparameters based on experience or intuition and observing the model’s performance. While this approach can be effective for small-scale problems, it is time-consuming and not scalable.

Overall Framework of Manual Hyperparameter
- Automated Hyperparameter Optimization: Automated methods, such as Grid Search and Bayesian Optimization, aim to find the optimal set of hyperparameters more efficiently.
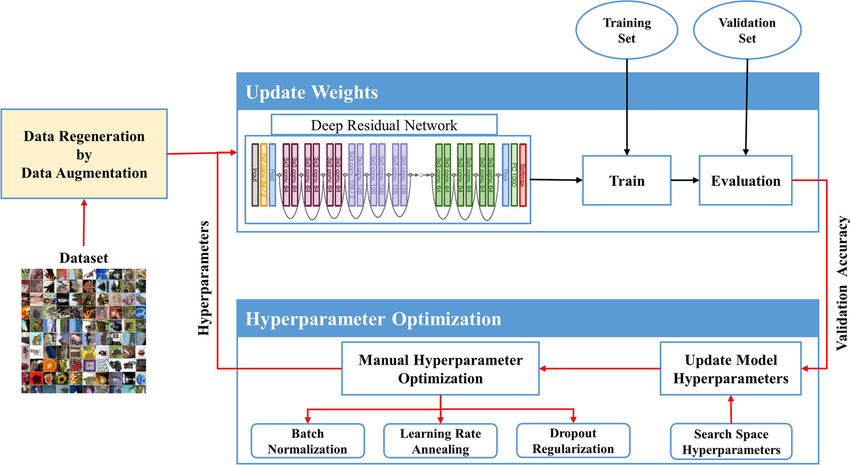
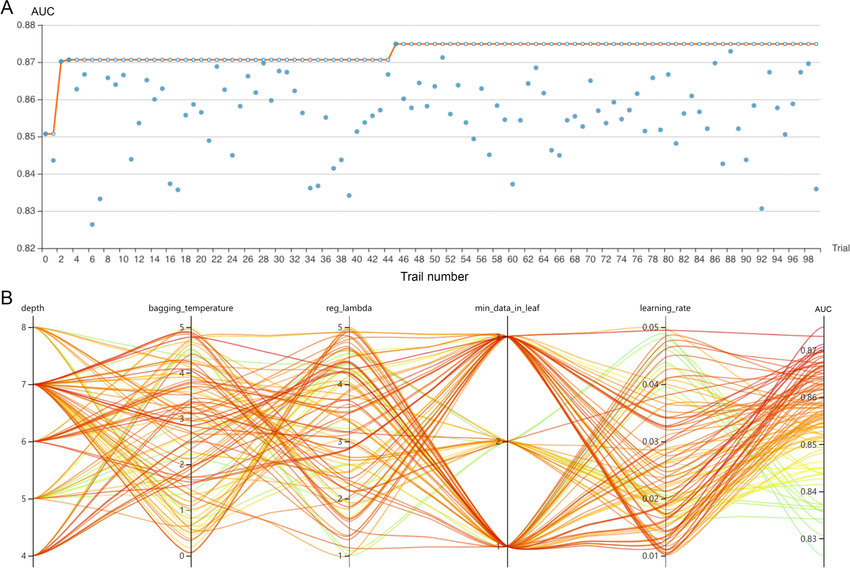
Overall Framework of Automated Hyperparameter
- Grid Search involves testing a range of hyperparameter values systematically to identify the best-performing combination. Although exhaustive, it can be computationally expensive for large search spaces.
- Bayesian Optimization leverages probabilistic models to predict which hyperparameters are likely to yield the best results, allowing it to focus on more promising configurations and reducing the computational cost.
Common Parameters to Optimize (Learning Rate, Batch Size, etc.)
Some of the most common hyperparameters that need optimization include:
- Learning Rate: Controls how much the model’s parameters are adjusted with respect to the loss gradient during training. A learning rate that is too high may cause the model to converge too quickly or overshoot, while a rate that is too low may result in slow learning or getting stuck in local minima.
- Batch Size: The number of training examples utilized in one iteration. A larger batch size can lead to more stable gradients, but smaller batch sizes may result in faster convergence.
- Number of Epochs: The number of times the model will iterate over the entire training dataset. More epochs may lead to better performance, but too many can cause overfitting.
- Regularization Parameters: These are used to avoid overfitting by adding penalties to the model’s loss function, such as L2 or L1 regularization.
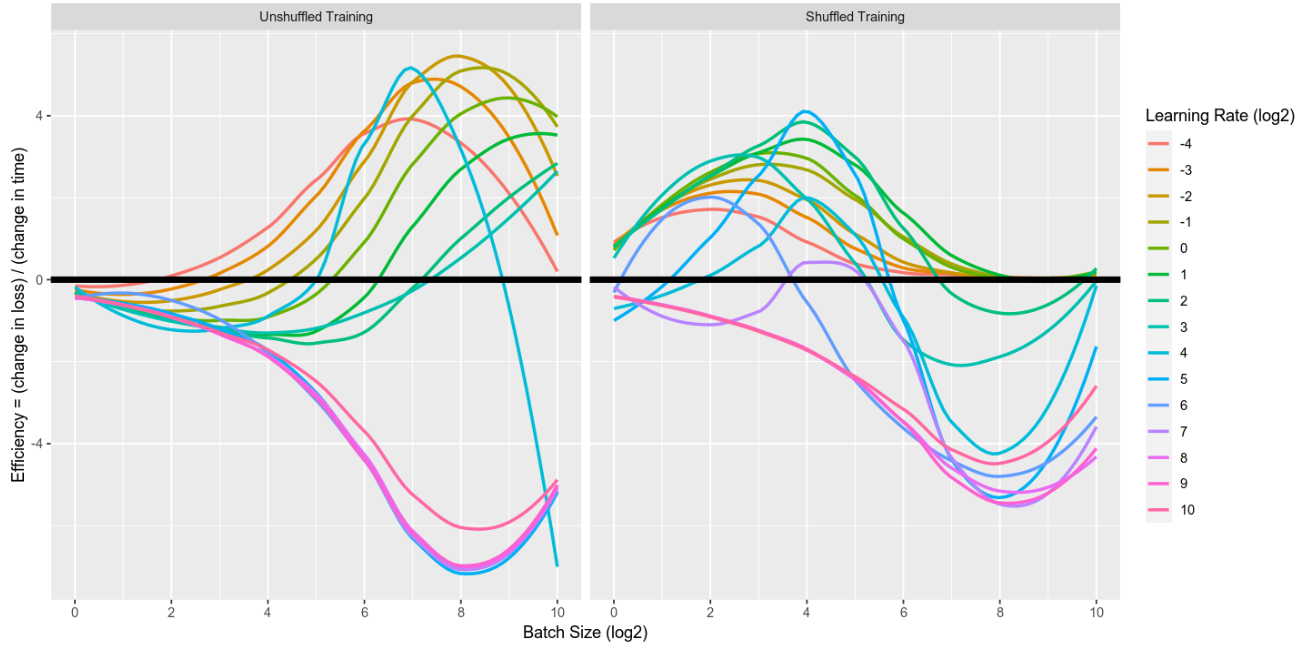
Learning Rate & Batch Size as parameters
3.2 Transfer Learning: Training AI with Pre-Trained Models
What is Transfer Learning?
Transfer learning is a technique where a pre-trained model, built on a large and general dataset, is fine-tuned for a specific task. This approach significantly reduces the time and resources required for training a new model from scratch, as the pre-trained model already possesses learned features that can be adapted to new tasks with relatively little additional training.
Transfer Learning in machine learning
Advantages of Using Pre-Trained Models
The primary advantages of transfer learning include:
- Faster Training: Since the model is pre-trained, it requires less data and fewer computational resources to achieve good results.
- Better Performance with Limited Data: Transfer learning is particularly useful when training data is scarce. The pre-trained model’s existing knowledge helps it generalize better to smaller datasets.
- Cost Efficiency: Reducing the need for extensive training saves time, computational costs, and energy consumption.
Popular Pre-Trained Models (BERT, GPT, ResNet)
Some widely-used pre-trained models include:
- BERT (Bidirectional Encoder Representations from Transformers): Primarily used for natural language processing (NLP) tasks such as text classification, question answering, and sentiment analysis. BERT has been pre-trained on vast amounts of text and can be fine-tuned for specific language tasks.
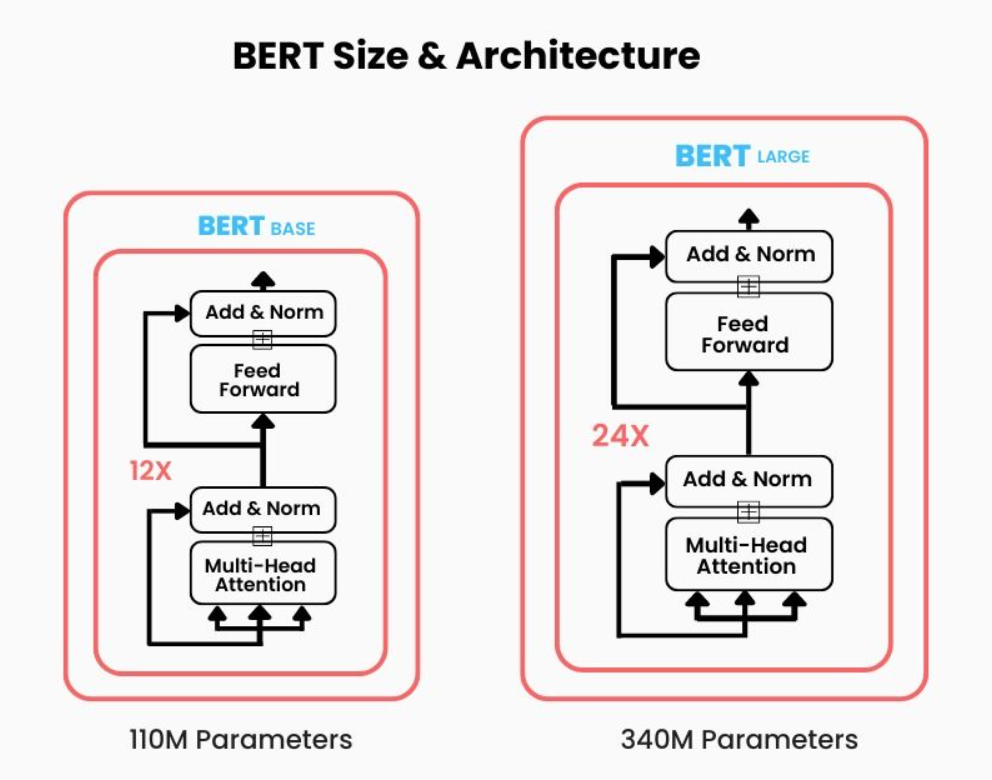
Size & architecture of BERT model
- GPT (Generative Pre-trained Transformer): A language model known for generating human-like text. It is particularly effective in applications such as chatbots, content creation, and language translation.
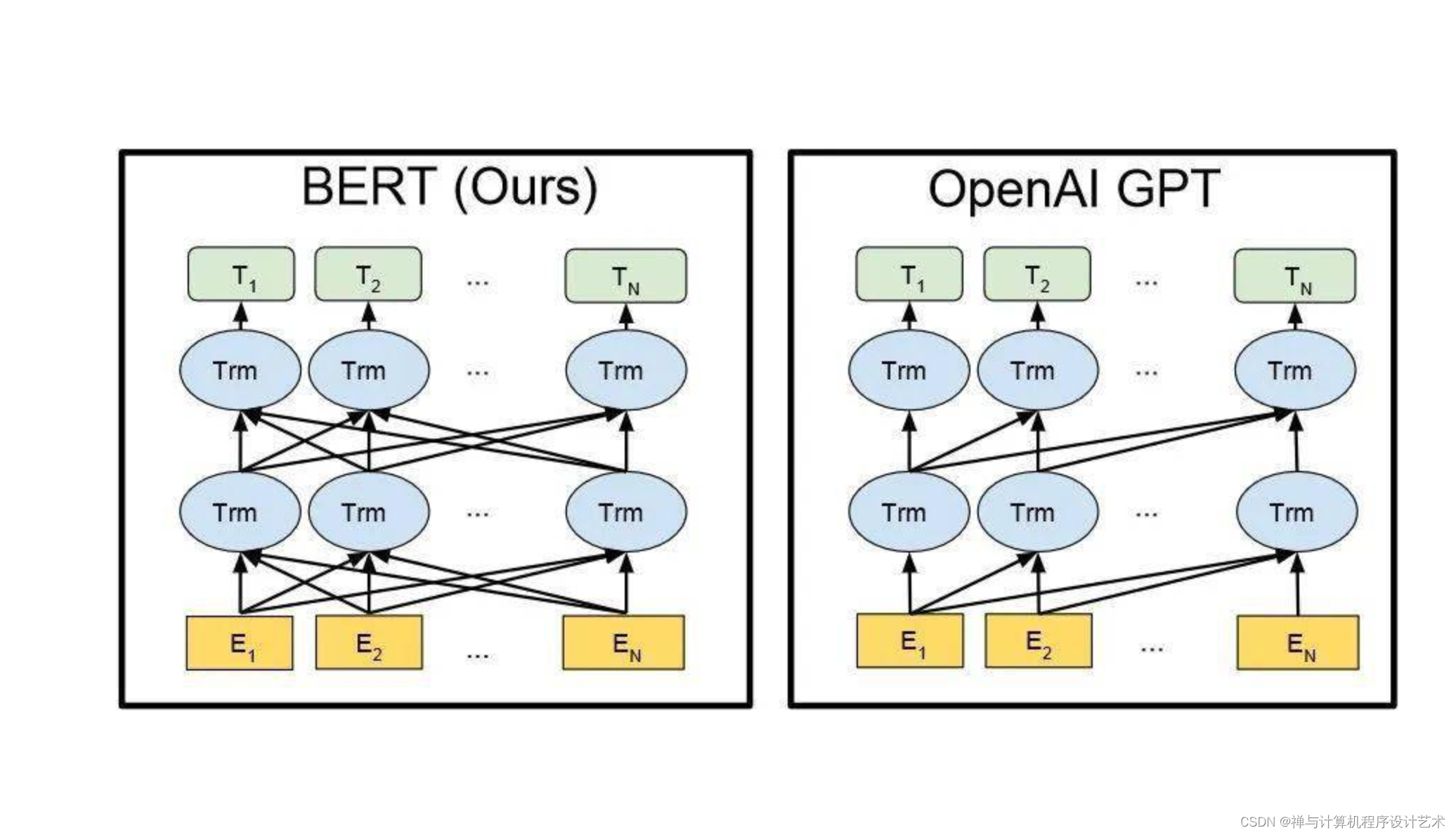
GPT vs BERT model
- ResNet (Residual Networks): A deep convolutional neural network (CNN) designed for image classification tasks. ResNet’s architecture enables the model to train very deep networks without encountering issues such as vanishing gradients.
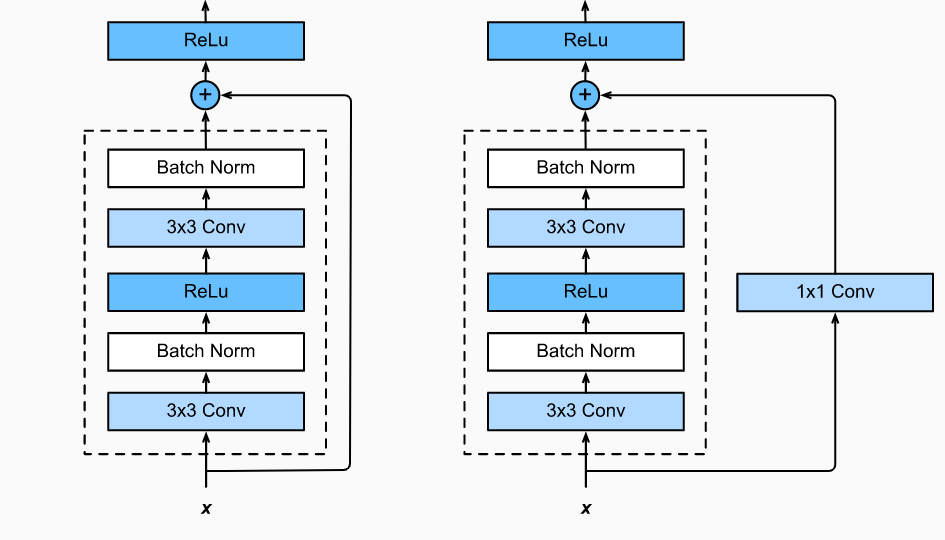
ResNet
3.3 Federated Learning and Edge AI Training
How Federated Learning Works
Federated learning is a decentralized training approach that allows multiple devices (such as smartphones, IoT devices, or edge servers) to collaboratively train a model without sharing their data. Instead of sending raw data to a central server, each device trains the model locally and only shares model updates, which are then aggregated to update the global model. This method ensures that sensitive data remains private while still enabling collaborative learning.
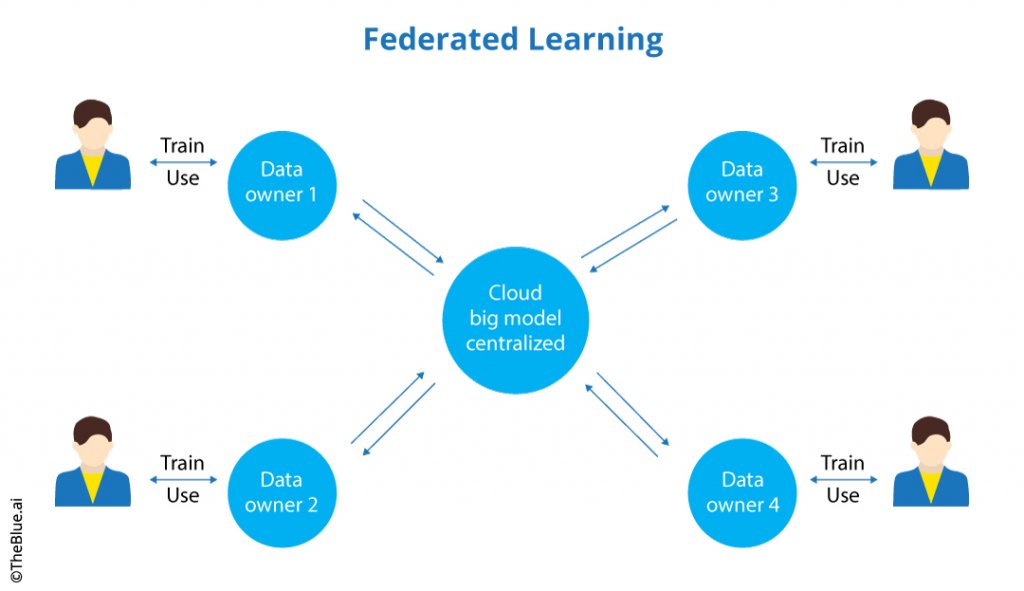
Federated Learning
Training Models at the Edge for Privacy and Latency Benefits
Edge AI refers to running AI models directly on edge devices (such as smartphones, drones, or industrial machines) rather than sending data to a cloud server. This approach reduces latency, as decisions can be made locally, and offers privacy benefits by keeping sensitive data on the device.
Edge AI training allows for real-time decision-making and more efficient use of network resources, making it ideal for applications in areas like autonomous vehicles, smart cities, and healthcare.
Applications of Federated and Edge AI
- Federated Learning: Used in healthcare (where patient data privacy is crucial), finance (enabling personalized fraud detection models while keeping transaction data private), and mobile devices (improving the user experience with personalized recommendations without compromising privacy).
- Edge AI: Applied in autonomous systems (e.g., self-driving cars that make real-time decisions based on local sensor data), industrial automation (enabling predictive maintenance without relying on cloud infrastructure), and smart home devices (such as voice assistants and security cameras).

Autonomous System
3.4 Overcoming Challenges in AI Model Training
Overfitting and Underfitting: Causes and Solutions
Overfitting and underfitting are common issues that arise during AI model training:
- Overfitting: Occurs when the model learns the training data too well, including noise and outliers, which negatively impacts its ability to generalize to unseen data. Solutions include using more training data, applying regularization techniques, or simplifying the model.
- Underfitting: Happens when the model fails to capture the underlying patterns in the data, leading to poor performance. To combat underfitting, one can increase the model’s complexity, improve data preprocessing, or adjust hyperparameters.
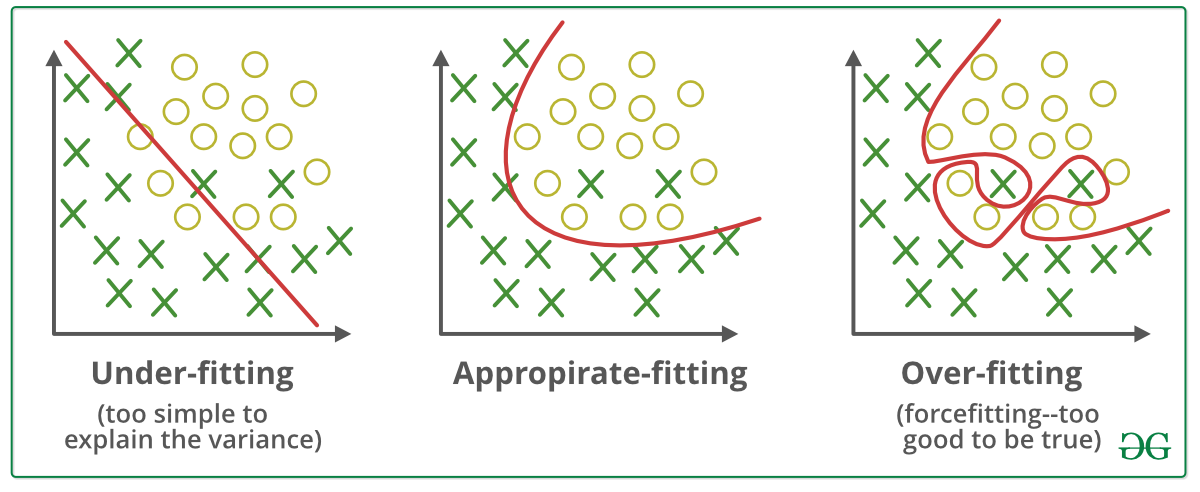
Overfitting vs Underfitting
Debugging Training Failures
Training failures are inevitable at times. Debugging these failures requires a systematic approach, such as:
- Checking Data Quality: Ensuring that the data is clean, correctly labeled, and representative of the problem.
- Monitoring Loss Functions: Watching how the loss function evolves during training to identify issues like poor optimization or excessive learning rate.
- Analyzing Model Architecture: Evaluating whether the chosen algorithm or architecture is suitable for the task or if a more complex model is necessary.
Scaling Training for Large Datasets
Training on large datasets can be challenging due to the computational demands. To address this, techniques such as distributed training (splitting the dataset across multiple machines) and using high-performance hardware like GPUs or TPUs can help scale the training process.
Additionally, cloud-based solutions provide on-demand computing power, enabling models to train on massive datasets without the need for significant on-site infrastructure.
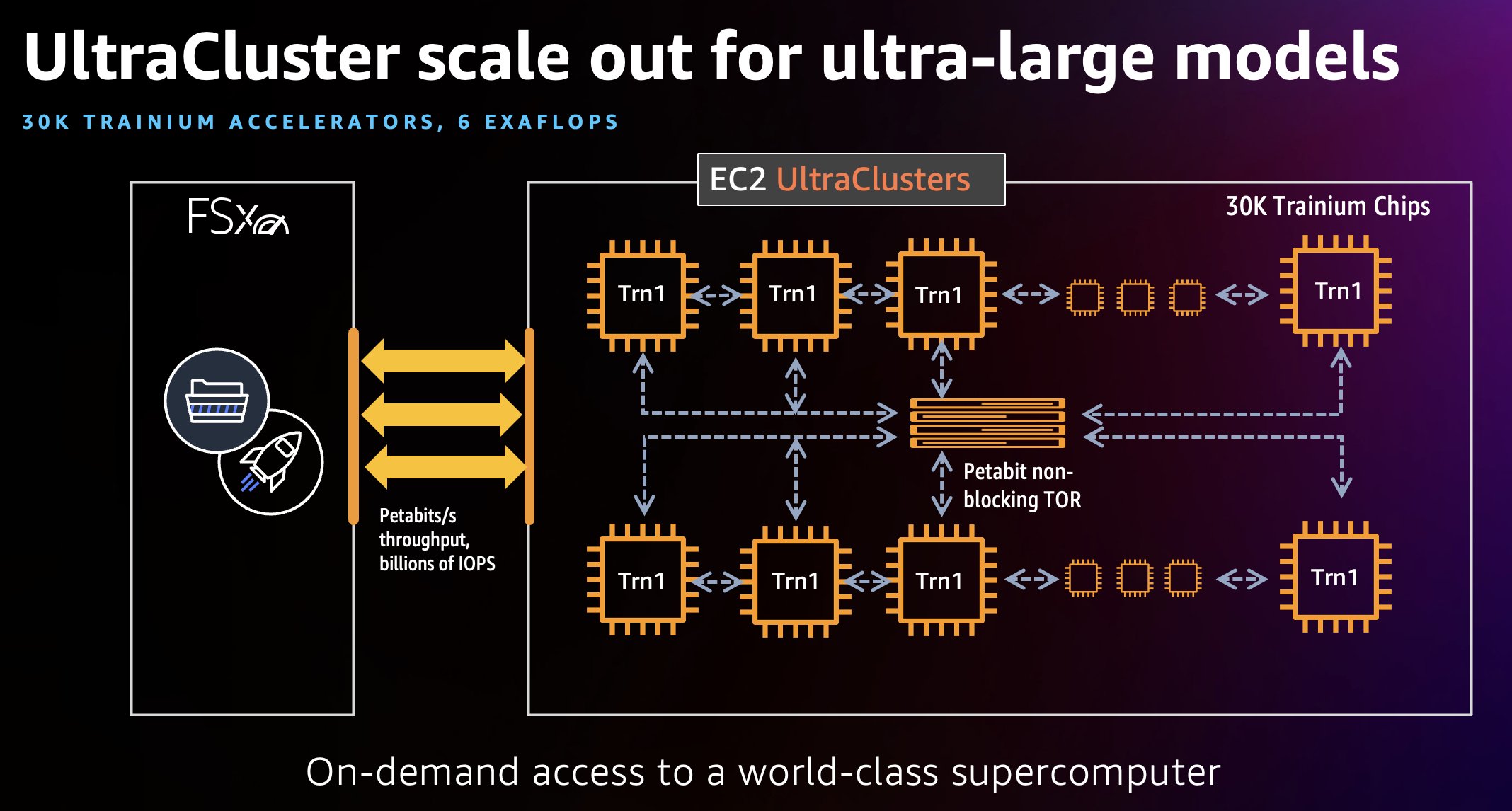
Scale out for Ultra-large model
4. Use Cases and Real-World Applications
4.1 AI Model Training in Different Industries
AI model training has transformative potential across various industries, allowing businesses to automate complex tasks, improve decision-making, and create innovative products and services. Below are some of the key industries benefiting from AI model training.
Healthcare: Training AI for Diagnosis and Drug Discovery
In healthcare, AI model training is revolutionizing the way medical professionals diagnose diseases and discover new treatments. By training AI models on vast datasets of medical images, electronic health records, and genetic data, AI systems can assist doctors in diagnosing diseases with a high degree of accuracy. For instance, AI models trained on medical images, such as X-rays or MRIs, can help identify conditions like cancer, fractures, or cardiovascular diseases.
Additionally, AI is playing a pivotal role in drug discovery. Training models on chemical compounds, biological data, and clinical trials allows researchers to predict how certain drugs might interact with the body, accelerating the discovery of new treatments and therapies. This application significantly reduces the time and cost associated with traditional drug development.

Retail: AI-Powered Recommendation Systems
Retailers are leveraging AI model training to enhance the customer experience through personalized recommendations. By training algorithms on customer behavior, purchasing history, and product preferences, AI models can predict products that a customer is likely to buy.
These recommendation systems power features like personalized product suggestions on e-commerce platforms and targeted marketing campaigns. Additionally, AI can optimize inventory management by predicting demand for products and suggesting optimal stock levels.
The success of AI-powered recommendation systems lies in the model’s ability to continuously learn and adapt to evolving customer preferences, ensuring relevant and timely recommendations.
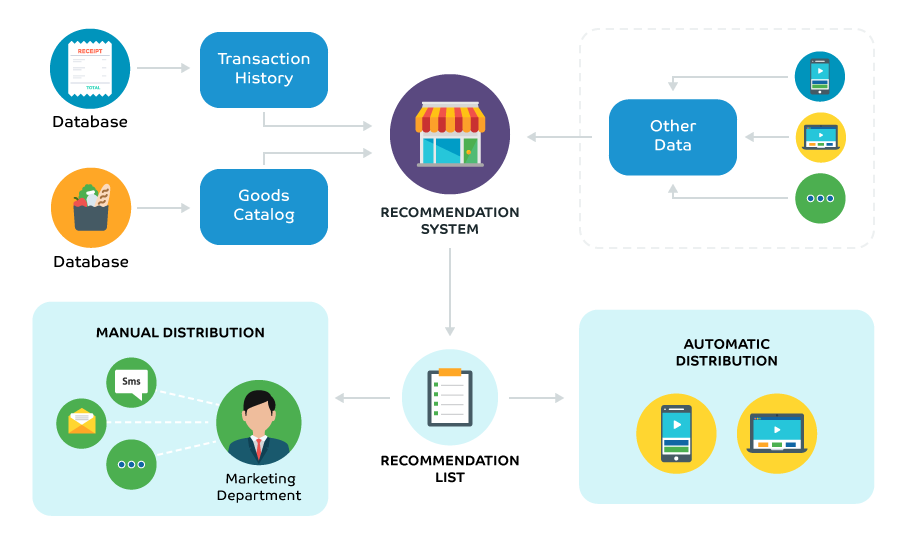
Principle of Recommendation system
Finance: Fraud Detection and Credit Scoring
In the finance industry, AI model training is instrumental in detecting fraudulent transactions and assessing credit risk. AI models can be trained on large datasets of historical transactions to identify unusual patterns that might indicate fraudulent activity. By learning from past fraud cases, the model can recognize red flags and flag potentially risky transactions in real time, providing valuable protection against fraud.
Similarly, AI is widely used in credit scoring models, where it is trained on customer data, including payment history, income levels, and loan applications. The AI model assesses the risk of lending to a particular individual or business by predicting their likelihood of defaulting on a loan. This allows for more accurate and efficient credit assessments.

AI in fraud detection
Autonomous Vehicles: Training AI for Driving Decisions
AI model training is a key technology behind the development of autonomous vehicles. Training AI systems to make safe and reliable driving decisions requires vast amounts of data collected from cameras, sensors, and LIDAR systems installed in vehicles. These data sets are used to teach the AI model to recognize objects, understand traffic patterns, and make decisions, such as when to accelerate, brake, or steer.
As the model learns from real-world driving scenarios, it continually improves its ability to navigate complex environments, including city streets, highways, and unpredictable conditions. Autonomous vehicles rely on AI for tasks such as object detection, route planning, and real-time decision-making, significantly improving road safety and reducing human error.

4.2 AI Model Training for Generative Models
Generative models are a class of AI systems designed to create new data that mimics real-world examples. AI model training plays a central role in developing generative models capable of producing content across various domains, such as language, art, and music. One of the most notable types of generative models is the Generative Adversarial Network (GAN).
Training Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) consist of two neural networks: a generator and a discriminator. The generator creates new data (such as images or text), while the discriminator evaluates its authenticity. The two networks compete with each other, with the generator trying to fool the discriminator into thinking its output is real, and the discriminator working to distinguish between real and generated data. Through this adversarial process, the generator improves over time, learning to create high-quality, realistic data.
GANs have been successfully applied in various fields, including image generation (creating photorealistic images from textual descriptions or random noise), video generation, and even data augmentation for training other AI models. The training of GANs involves complex processes and requires significant computational resources, but their ability to create new, unique data has made them a powerful tool in AI research and commercial applications.
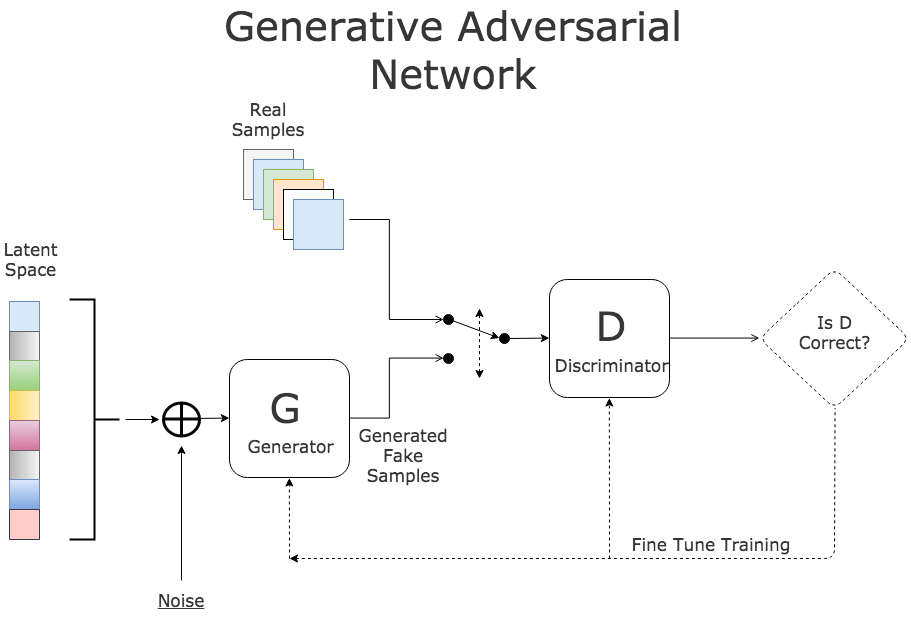
Generative Adversarial Network
AI for Content Generation: Language, Art, and Music
AI-driven content generation is revolutionizing creative industries, offering new possibilities for generating text, art, and music. In language generation, models like GPT (Generative Pre-trained Transformer) have made significant strides in producing coherent, human-like text. These models can be trained to write articles, generate marketing copy, or even produce entire novels.
In the art world, AI is being used to create paintings, digital artwork, and design concepts. By training models on vast datasets of artwork from different styles and time periods, AI can generate new pieces of art that mimic the style of famous artists or create entirely new forms of expression.
Similarly, AI is being trained to compose music, offering musicians new tools for creativity. By learning from existing compositions, AI can generate original musical pieces in various genres, blending melodies, harmonies, and rhythms to create innovative sounds. These advances in AI-driven content generation are opening up new avenues for creativity, with applications in entertainment, advertising, and design.
4.3 Case Studies: Success Stories in AI Model Training
Synapse, a new marketplace for journalists and PRs, faced the challenge of outdated technology that couldn’t effectively handle the massive flow of data and pitches, leading to inefficiencies and missed opportunities.
Moreover, Synapse needed to incorporate advanced AI capabilities into its existing PHP-based platform to enable personalized recommendations and content suggestions that align with journalists’ profiles, expertise, and writing preferences. This required a sophisticated update of the user interface and API enhancements, demanding careful planning to ensure robustness and user-friendliness.
AI-Powered Pitch Tracking
SmartDev tackled Synapse’s challenges with a focused development of AI-driven functionalities. This targeted initiative allowed the team to define and adjust the project’s requirements clearly. Prioritizing user experience, SmartDev dedicated substantial efforts to redesigning the platform’s interface, ensuring it was intuitive and visually engaging to support enhanced user interaction.
To address the integration challenges with the existing PHP framework and multiple third-party systems, SmartDev crafted a flexible and scalable codebase. This foundation enabled the seamless integration of advanced AI capabilities and existing functionalities, enhancing the platform’s ability to efficiently handle and analyze large volumes of data.
AI-Enabled Media Requests Monitoring
5. Ethical Considerations and Challenges
As AI models become more integral to various sectors, it is essential to address the ethical implications associated with AI model training. These challenges range from bias in models to concerns over data privacy, security, and the environmental impact of training large-scale models. Ensuring that AI systems are developed responsibly requires thoughtful consideration of these issues.
5.1 Bias in AI Model Training
How Training Data Bias Impacts AI Models
Bias in AI models is a significant concern, primarily arising from biased training data. AI systems learn patterns from the data they are trained on, and if that data reflects societal biases or historical inequalities, the AI model may perpetuate or even amplify those biases. For example, biased data can result in AI models that exhibit gender, racial, or socioeconomic biases, leading to unfair or discriminatory outcomes in applications like hiring, criminal justice, and lending.
Strategies to Reduce Bias During Training

- Diverse and Representative Datasets: Ensuring that training data is diverse and representative of all relevant demographics helps mitigate bias. The inclusion of a broad spectrum of data from various groups can prevent the model from favoring one group over others.
- Bias Detection and Auditing: Regularly auditing AI models for bias is essential. Tools and techniques such as fairness constraints and adversarial testing can be used to assess the model’s performance across different demographic groups.
- Bias Mitigation Techniques: During model training, bias mitigation strategies such as re-weighting training data, adjusting model architectures, or using fairness algorithms can help reduce the impact of biased data on the model’s output.
- Human Oversight: Involving human experts in the training and evaluation process can provide an additional layer of oversight to ensure that AI models are fair and do not unintentionally perpetuate harmful biases.
5.2 Data Privacy and Security in AI Training
Ensuring Data Anonymity in Training Sets
Data privacy is a fundamental ethical concern in AI model training, especially when working with sensitive information such as personal, medical, or financial data. To safeguard privacy, it is essential to anonymize or pseudonymize data before it is used for training. Anonymization removes or obscures identifying details, ensuring that individuals cannot be traced through the data. However, it is important to maintain the data’s usefulness while ensuring anonymity.
One method of ensuring data privacy is through the use of differential privacy, which involves adding noise to the data to prevent identification while still allowing the model to learn useful patterns. This technique is commonly employed in privacy-conscious sectors such as healthcare and finance, where protecting individual identities is paramount.
Regulations and Compliance (GDPR, CCPA)

In light of growing concerns about data privacy, several regulations have been put in place to ensure that data used for AI model training complies with stringent standards. Notable regulations include:
- GDPR (General Data Protection Regulation): This European Union regulation governs the collection, processing, and storage of personal data. It mandates that data be collected with informed consent and requires organizations to provide individuals with the right to access, correct, or delete their data.
- CCPA (California Consumer Privacy Act): Similar to GDPR, the CCPA provides privacy protections for California residents, granting them rights to know what personal data is being collected and to request its deletion.
Compliance with these regulations is essential for organizations to avoid legal consequences and ensure ethical data handling practices. AI developers must be mindful of these rules when collecting, storing, and using personal data for model training.
6. Testing and Deployment
After AI models are trained, the next crucial step is testing and deployment. Effective testing ensures that the model will perform well in real-world scenarios, while a smooth deployment process guarantees that the model can scale and adapt to evolving needs. The following sections discuss the importance of testing AI models, common issues encountered, and key considerations during deployment.
6.1 The Importance of Testing AI Models Before Deployment
Why Testing Complements Training
While training an AI model provides the foundation for its performance, testing is equally essential for ensuring that the model behaves as expected under various conditions. Testing allows developers to validate that the model generalizes well to unseen data and performs reliably in real-world environments. This step is crucial because models may exhibit different behavior when exposed to new, unstructured data outside the controlled environment of the training set.
During testing, various evaluation metrics such as accuracy, precision, recall, and F1-score are assessed to ensure that the model meets the predefined objectives. Additionally, testing helps identify areas where the model may require fine-tuning or retraining.
Common Issues Detected During Testing
Testing an AI model often reveals issues that were not apparent during training, including:
- Overfitting and Underfitting: A model may perform exceptionally well on the training data but fail to generalize to unseen data (overfitting), or it may not capture the underlying patterns of the data (underfitting). Testing helps identify such issues, prompting adjustments to the model or the training process.
Overfitting vs Underfitting
- Bias and Fairness Issues: Even after training, AI models can exhibit bias or discriminatory behavior based on the data used in training. Testing across different demographic groups helps identify and mitigate potential biases.
- Performance Bottlenecks: Models may face performance issues when scaled or when faced with large volumes of real-time data. Testing can identify bottlenecks in model inference speed or memory usage, which can affect real-time decision-making.
- Edge Cases: AI models can fail when they encounter outlier or edge cases that were not adequately represented in the training data. Testing with diverse data helps ensure that the model can handle such edge cases robustly.
6.2 Deploying Trained AI Models
Considerations for Model Deployment (Scalability, Latency, and Maintenance)
When deploying trained AI models, several factors must be carefully considered to ensure that they perform optimally in a production environment:
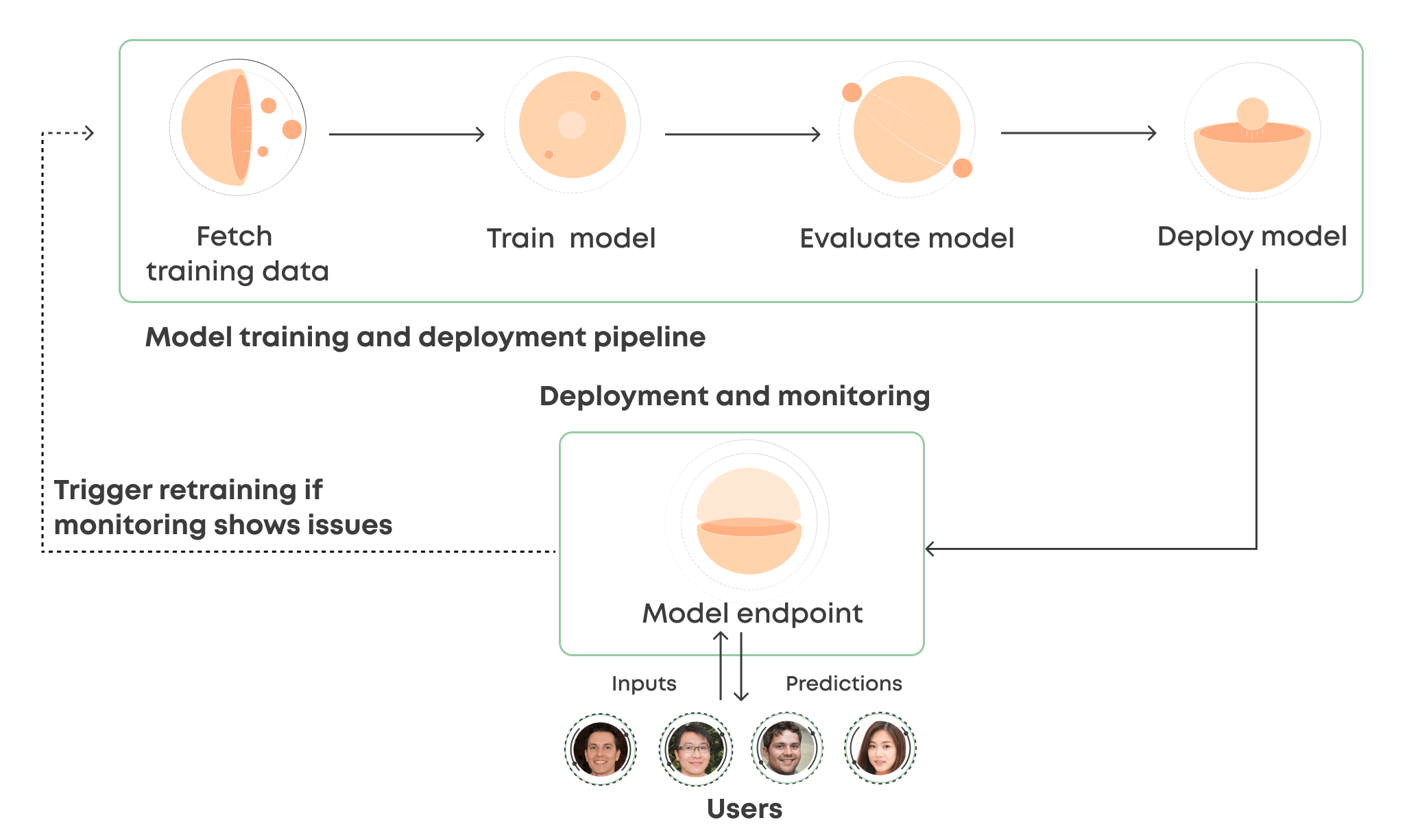
Monitoring in model deployments
- Scalability: AI models must be able to scale based on demand. Whether it’s handling increasing data volumes, serving a growing number of users, or processing complex data in real-time, the model must be able to scale efficiently. Cloud-based solutions and distributed architectures can help manage scalability.
- Latency: The speed at which a model processes data is critical, especially in applications like autonomous vehicles or financial transactions where real-time decision-making is essential. Minimizing latency while maintaining accuracy requires optimizing the model and ensuring that infrastructure is capable of handling rapid processing.
- Maintenance: AI models require ongoing maintenance to ensure they continue to perform well as conditions change. This may involve periodic retraining with updated data, adjusting hyperparameters, or even replacing the model if performance degrades. Having a robust model maintenance plan is crucial to keep the AI system effective over time.
Continuous Training and Model Updates
AI models are not static, and their performance can degrade over time as new data becomes available or as the environment changes. Continuous training and regular updates are essential to keep the model aligned with the evolving conditions of the production environment.
- Continuous Training: As new data is collected, the model should be retrained regularly to incorporate recent trends and behaviors. This helps maintain model accuracy and relevance. In some cases, AI models can be set up to continuously learn from new data, a process known as online learning, ensuring that the model adapts in real time.
- Model Updates: Even with continuous training, models may need periodic updates to enhance performance or add new capabilities. This may include adding new features, adjusting for biases, or incorporating new algorithms. Deploying model updates should be done with caution to avoid disrupting service, often through A/B testing or canary releases where the new model is tested with a subset of users before full deployment.
7. Top Tools and Frameworks for AI Model Training
AI model training requires specialized tools and frameworks that can optimize machine learning workflows, from data preprocessing to deployment. The tools you choose depend on factors like the complexity of your project, the size of your team, and the scale at which you intend to deploy your model. Below is an overview of some of the top tools and frameworks across various categories.
7.1 Core AI Training Frameworks
These frameworks are the backbone of AI model training, providing the essential building blocks for designing and optimizing machine learning models. They vary in complexity, but all offer powerful features for both beginners and advanced users.
- TensorFlow: Known for its flexibility and scalability, TensorFlow is one of the most widely used frameworks for machine learning and deep learning. It’s ideal for building and deploying models for production-level tasks. With its support for both CPUs and GPUs, TensorFlow can handle everything from simple algorithms to complex deep learning architectures. It is especially favored for large-scale deployments and production environments.
- PyTorch: Popular among researchers, PyTorch offers dynamic computation graphs, which makes it easier to experiment and iterate. It provides intuitive debugging and a more “pythonic” interface, making it easier for developers to get started. PyTorch is known for its flexibility, making it the go-to choice for research applications and prototyping. Its robust ecosystem includes libraries like TorchVision for computer vision tasks and TorchText for NLP.
- Scikit-Learn: A lightweight library for classical machine learning algorithms, Scikit-Learn is perfect for beginners and small-scale projects. It offers simple, clean, and efficient tools for data mining and data analysis. It is built on Python, and while it does not support deep learning, it excels in tasks such as regression, classification, and clustering using algorithms like Decision Trees, Support Vector Machines (SVM), and K-means.
- Hugging Face Transformers: Specialized in Natural Language Processing (NLP), Hugging Face Transformers simplifies the fine-tuning of pre-trained models like GPT and BERT. It provides a straightforward interface for NLP tasks such as text generation, sentiment analysis, and machine translation. Hugging Face has become an industry standard for NLP tasks, offering access to state-of-the-art models and tools that can be easily adapted to different use cases.
7.2 Automated AI Training Platforms
These platforms streamline the AI training and deployment process by providing automated tools, cloud scalability, and pre-built pipelines, making them ideal for users who need to scale quickly or lack deep technical expertise.
- Google Vertex AI: A comprehensive platform that combines AutoML capabilities with custom model training, Google Vertex AI allows both beginner and advanced users to build and deploy machine learning models. It integrates with Google Cloud services and provides a streamlined workflow for managing data, training models, and monitoring performance. Vertex AI supports a range of use cases from simple predictions to complex AI-driven applications.
- AWS SageMaker: Amazon Web Services (AWS) SageMaker offers a fully managed environment for building, training, and deploying machine learning models at scale. It includes tools for data preparation, model training, and hosting, as well as built-in monitoring for evaluating model performance post-deployment. SageMaker is ideal for enterprise-scale solutions, offering a broad array of tools to automate tasks like hyperparameter tuning and model optimization.
- Microsoft Azure AI: Highly integrated with Microsoft’s cloud platform, Azure AI is a great choice for enterprises seeking to build AI solutions that work seamlessly with their existing infrastructure. It offers a wide range of pre-built tools for machine learning, cognitive services, and data analytics. Azure AI supports various use cases, from NLP to computer vision, and integrates well with business workflows, making it ideal for organizations that need both flexibility and scalability.
7.3 Open-Source Tools vs. Commercial Solutions
When selecting tools for AI model training, there is a trade-off between the flexibility and cost-efficiency of open-source tools and the advanced features and enterprise-level support provided by commercial solutions.
Open-Source Tools:
- TensorFlow, PyTorch, and Scikit-Learn: These popular open-source frameworks are free to use and have extensive community support. They are widely adopted across industries and academia for various AI tasks. They allow users to customize their models and algorithms, making them ideal for developers looking for flexibility and cost-efficiency.
- Jupyter Notebooks: An essential tool for interactive model development and visualization, Jupyter Notebooks allows developers to write code in a notebook interface that combines code, text, and visualizations in one document. It is a must-have for prototyping, experimentation, and data exploration.
Jupyter Notebooks
Commercial Solutions:
- IBM Watson: IBM Watson offers a suite of AI-powered solutions that include NLP, computer vision, and automated machine learning. It provides advanced features and enterprise-grade support, making it suitable for large organizations looking to deploy AI models at scale. However, its proprietary tools come at a premium cost.

- SAS Viya: SAS Viya offers a scalable, cloud-based platform for machine learning and data analytics. It integrates with a wide range of data sources and provides tools for building, training, and deploying AI models in a highly secure environment. It is ideal for businesses with complex data needs and large-scale requirements.
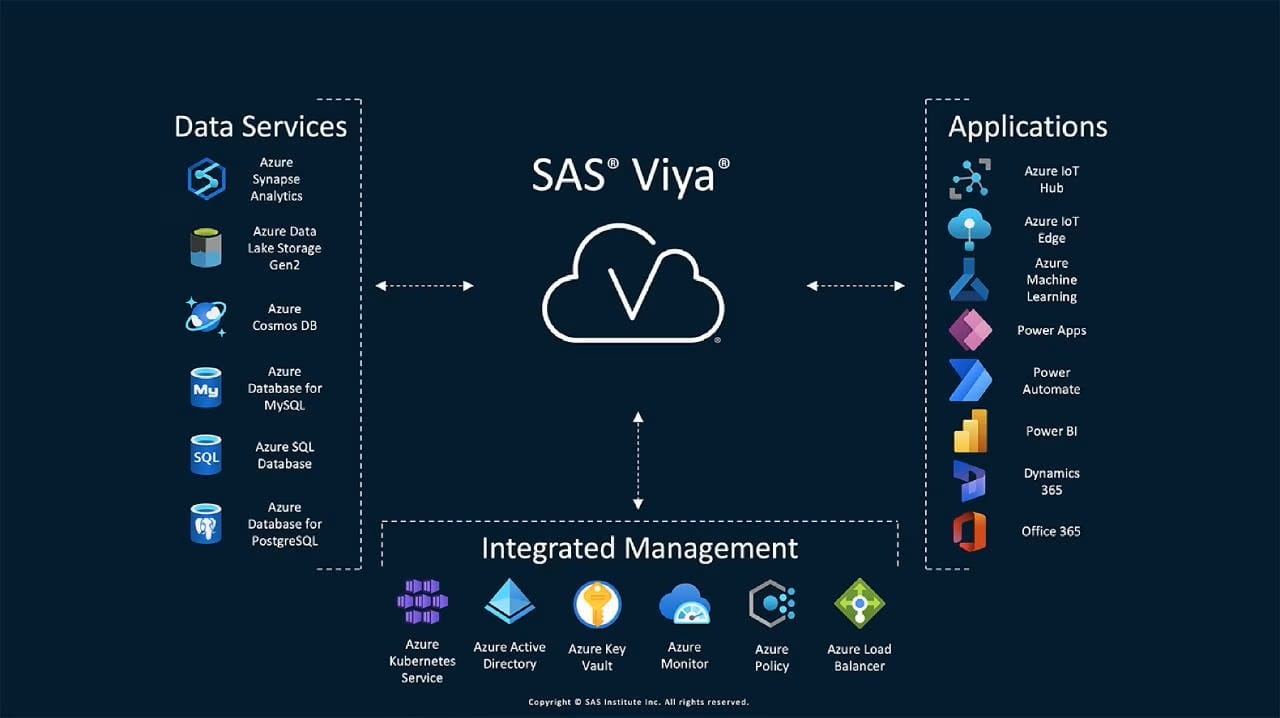
SAS Viya AI model
Tip: Open-source tools are ideal for individuals and smaller teams looking for cost-effective solutions with a strong community ecosystem. Commercial solutions, on the other hand, are suited for large enterprises with significant budgets that require advanced, proprietary features and dedicated customer support.
7.4 Tool Selection by Use Case
Choosing the right tool for your specific use case ensures efficiency and reduces unnecessary trial and error. Here are some recommendations based on common AI tasks:
For Natural Language Processing (NLP):
- Hugging Face Transformers: A go-to choice for fine-tuning pre-trained models like GPT and BERT for NLP tasks. Hugging Face excels in a wide range of NLP applications, from text generation to sentiment analysis.
- Google Vertex AI: Ideal for users seeking a full-stack solution for NLP that includes AutoML for text-based data.
For Computer Vision:
- YOLO (You Only Look Once): Known for its speed and accuracy, YOLO is perfect for real-time object detection tasks. It is highly efficient in processing images and video streams.
- TensorFlow: TensorFlow provides a comprehensive library for computer vision, including pre-trained models and support for both deep learning and classical computer vision techniques.
For Beginners and Small Teams:
- Scikit-Learn: Excellent for those starting with machine learning and looking for simple tools to implement traditional algorithms such as classification and clustering.
- Google Colab: A free cloud-based tool that allows you to run Jupyter notebooks with GPUs, making it a great option for small teams or individual developers to train models without the need for local infrastructure.
For Large Enterprises:
- AWS SageMaker: Ideal for enterprises with large-scale data and model deployment needs, offering end-to-end machine learning services.
- Microsoft Azure AI: Well-suited for organizations with complex business needs looking for highly integrated AI tools that align with their existing infrastructure.
- IBM Watson: Perfect for businesses requiring robust, customizable AI solutions that are backed by comprehensive support and enterprise-grade capabilities.
8. Framework and Platform Comparison: Key Features
Here’s a more detailed and refined comparison table, breaking down critical factors such as ease of use, scalability, community support, cost, and additional features for key AI tools and frameworks:
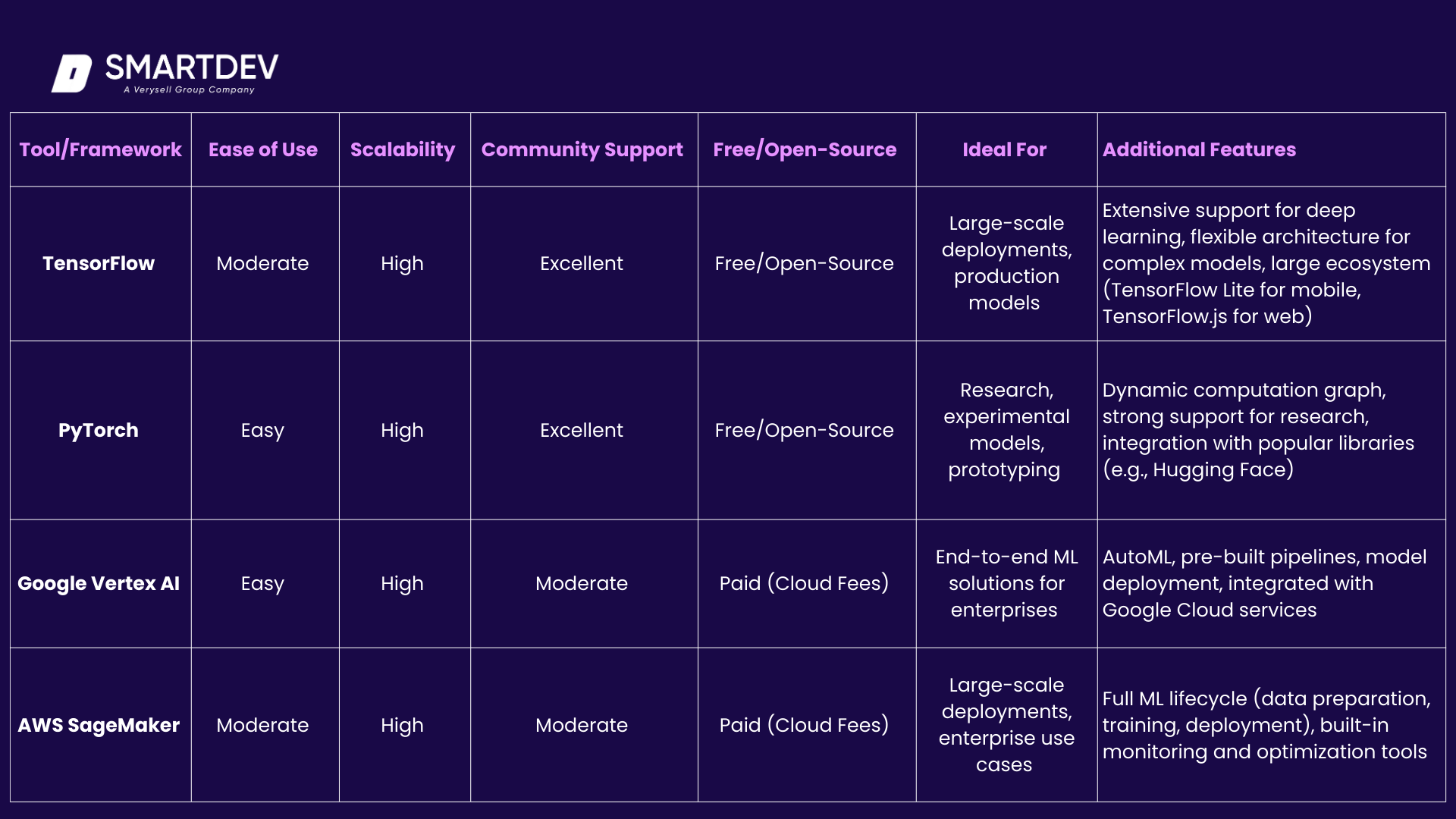
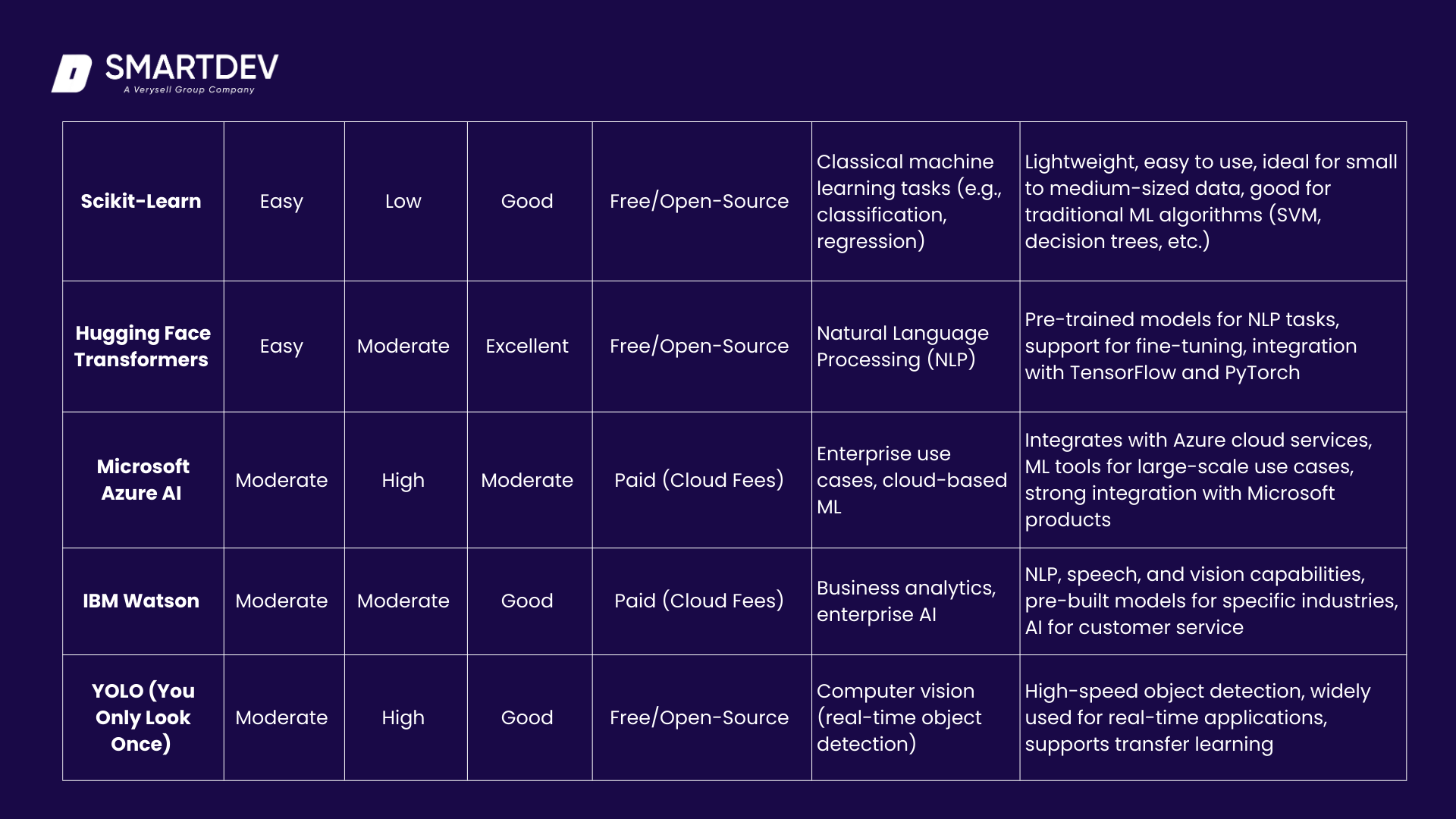
8.1 Key Differences and Additional Considerations:
Ease of Use:
- PyTorch is considered the easiest for beginners, especially for researchers and prototypers, due to its dynamic computation graph and user-friendly interface.
- Scikit-Learn is also very beginner-friendly, as it’s lightweight and has simple APIs for classical machine learning models.
- TensorFlow is more moderate in terms of ease of use due to its flexibility and complexity, especially for deep learning models, but it is very powerful once the learning curve is overcome.
Scalability:
- TensorFlow and PyTorch excel in scalability, making them suitable for large-scale production systems and complex models.
- Google Vertex AI and AWS SageMaker offer high scalability, designed specifically for cloud-based, enterprise-level deployment with strong support for scaling model training and inference.
Community Support:
- TensorFlow and PyTorch lead with excellent community support, offering comprehensive documentation, forums, and open-source contributions.
- Hugging Face Transformers also enjoys strong community backing, especially in the NLP space.
- Scikit-Learn, while excellent for smaller projects, has a smaller community compared to the larger deep learning frameworks.
Cost:
- TensorFlow, PyTorch, and Scikit-Learn are all free and open-source, making them ideal for developers with budget constraints or smaller projects.
- Google Vertex AI, AWS SageMaker, Microsoft Azure AI, and IBM Watson are all cloud-based platforms with associated costs, though they provide high-level features and scalability for enterprise solutions.
Additional Features:
- TensorFlow and PyTorch are flexible and powerful for a wide range of machine learning applications, including custom architectures and production-ready models.
- Google Vertex AI and AWS SageMaker offer comprehensive end-to-end workflows with advanced capabilities like AutoML, automatic model tuning, and deployment monitoring.
- Scikit-Learn is more suited for traditional machine learning algorithms and works best with smaller datasets and problems that don’t require deep learning.
Final Thoughts: Mastering AI Model Training
Low-Code and No-Code AI Training Platforms
One of the most exciting trends in AI model training is the rise of low-code and no-code platforms, which enable users with limited coding knowledge to build and deploy AI models. These platforms streamline the AI development process by providing user-friendly interfaces and pre-built components, allowing non-technical users to participate in AI model training.
As these platforms continue to evolve, they are expected to democratize access to AI technology, enabling businesses and individuals to develop machine learning solutions without requiring deep technical expertise.
AI-Driven Automation in Training Workflows
AI-driven automation is set to revolutionize training workflows by reducing manual intervention and optimizing the entire process. Tools such as AutoML (Automated Machine Learning) allow for automated hyperparameter tuning, data preprocessing, model selection, and evaluation. This helps streamline the process, reduce human error, and accelerate the development of AI models. As AI itself is used to enhance and automate training workflows, the speed and efficiency of model development will continue to improve, making AI more accessible and scalable.
Key Takeaways
AI model training is a multi-step process that begins with understanding the problem and preparing data and ends with deploying a model that can effectively make predictions or decisions in real-world environments. Key aspects of training include choosing the right tools and frameworks, fine-tuning hyperparameters, and ensuring that models are tested and evaluated thoroughly. The ethical considerations surrounding AI model training, such as bias, data privacy, and environmental impact, must also be addressed to ensure responsible AI development.
In addition, the future of AI model training is heavily influenced by advancements in automation, cloud-based platforms, and low-code/no-code tools, which will continue to expand access to AI technologies.
Now that you have an understanding of the core components of AI model training, the tools available, and the trends shaping its future, it’s time to start experimenting with training your own AI models. Whether you’re a beginner or an expert, there are a wealth of resources and platforms available to help you develop your skills and create impactful AI solutions.
By mastering AI model training, you can contribute to the rapid advancements in the field, create innovative applications, and address real-world problems across industries. With the continuous evolution of tools and techniques, the potential for growth in AI is limitless, and there has never been a better time to dive in.
[/vc_column_text][/vc_column][/vc_row]
—
References:
-
- How does AI model training works
- What Is AI Model Training & Why Is It Important?
- AI-Based Modeling: Techniques, Applications and Research Issues
- Has your paper been used to train an AI model? Almost certainly
- New Training Method Helps AI Generalize like People Do
- Things Get Strange When AI Starts Training Itself
- Training Green AI Models Using Elite Samples
- Data Readiness for AI: A 360-Degree Survey











