In today’s world, Artificial Intelligence (AI) has evolved from a niche research field to a mainstream technology that shapes industries and everyday life. From predicting customer preferences to powering self-driving cars, AI models are transforming how businesses operate and how we interact with technology. But behind every successful AI application is an AI model — a complex, powerful tool that learns from data to solve problems and make decisions without explicit programming.
As AI continues to mature, understanding how to build these models is more crucial than ever. Whether you’re a data scientist, a business leader, or an AI enthusiast, the ability to create and deploy AI models opens up endless possibilities for innovation and problem-solving.
But how exactly does one go about building an AI model from scratch?
What does the process involve, and what are the key steps to ensure success?
In this blog post, we will take you through the foundational steps of AI model development, providing insights into the underlying processes, key technologies, and best practices you need to build powerful AI systems that deliver real-world value.

TL;DR
- Start with a measurable business decision or outcome, not a model type. AI is a means, not the objective.
- Choose your delivery path — custom model, fine-tuning, API, or managed platform — based on differentiation need, data sensitivity, budget, and in-house capability, not on what is technically impressive.
- Data readiness, governance, and privacy permissions must be established before model development begins. A model is only as deployable as its data, permissions, and governance controls.
- Evaluation is a release gate, not a formality. Define performance, fairness, and operational thresholds before training, not after.
- Deployment includes integration, monitoring hooks, versioning, rollback controls, and a human-review path — not only hosting.
- Model operations must track both technical performance and the business outcome the model was built to improve.
- Most avoidable AI failures originate in unclear objectives, weak data, or missing operating ownership — not in model architecture.
1. Start With the Business Problem, Not the Model
The starting point for any AI initiative is a specific business decision, process, or customer outcome — not a model type or technology choice. Teams that select a model before defining the problem consistently underdeliver, because the model optimizes for the wrong objective.
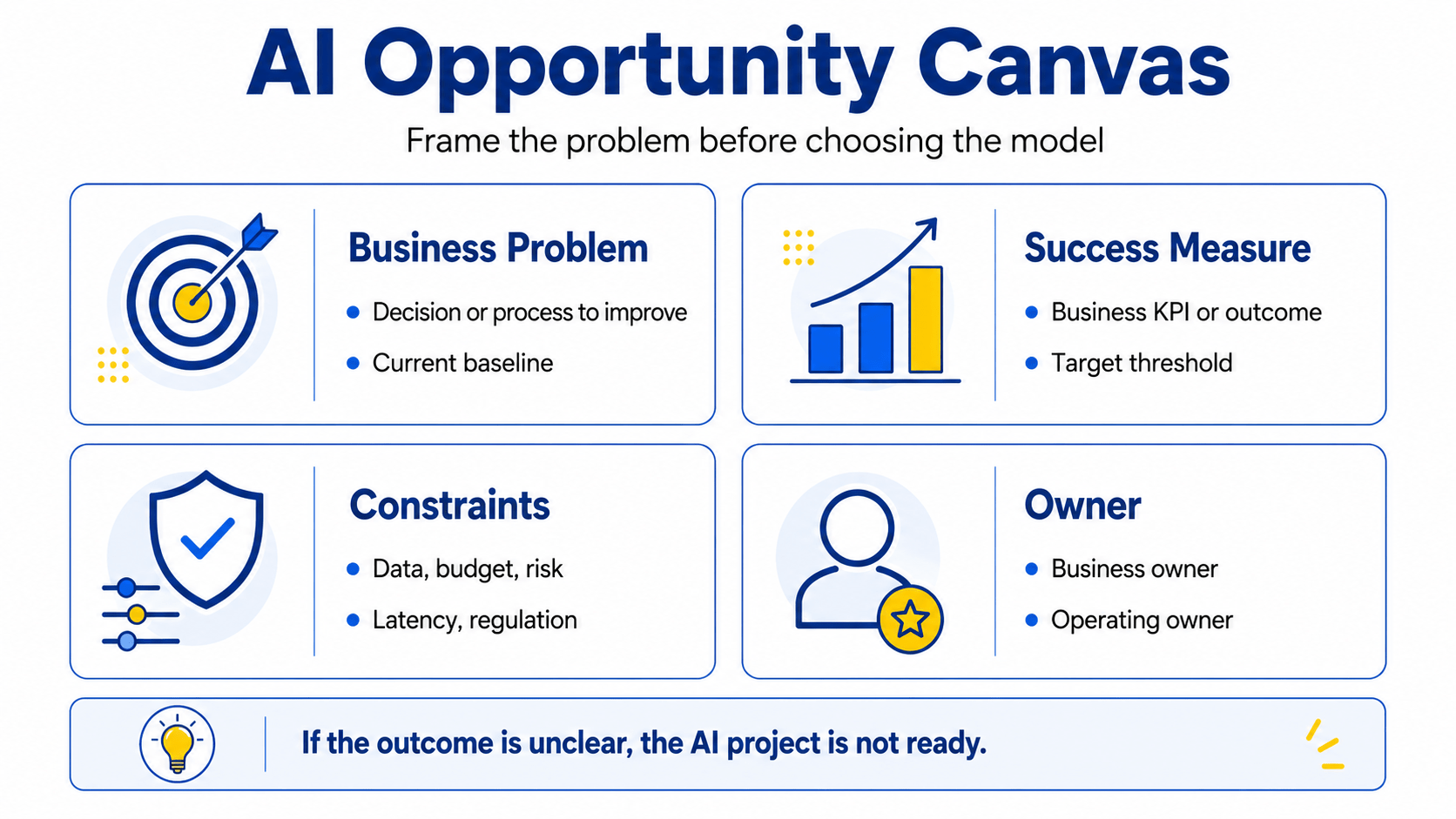
Define the decision, process, or outcome to improve
A well-formed AI problem statement names the decision being automated or improved, the current process that handles it, who is responsible for the outcome, and what a measurable improvement looks like. For example: “Our credit risk team reviews 300 applications per day manually. Approval accuracy is 78%. We want a model that reaches 85% accuracy with a false-positive rate below 5%, reviewed by a credit officer before any rejection.”
That framing defines the task, the baseline, the success criterion, and the human control point — all before a single line of code is written.
Set measurable success criteria and constraints
Success criteria should be expressed in business terms first, then translated into model metrics. Revenue recovered, processing time reduced, error rate cut by X% — these are the outcomes that justify the project. Technical metrics like F1-score or AUC-ROC support those outcomes but do not replace them.
Constraints matter equally: data access limitations, regulatory requirements, latency expectations, budget, and available engineering capability all shape which approaches are feasible. Surfacing constraints early prevents investment in a direction the organization cannot actually execute.
Assess AI feasibility: data, risk, cost, and operating ownership
Before committing to AI development, assess four feasibility factors. First, data: is labeled, representative, and sufficient data available or acquirable? Second, risk: what is the consequence of an incorrect prediction, and who owns that risk? Third, cost: does the expected business value exceed the full cost of development, infrastructure, and ongoing operation? Fourth, operating ownership: is there a named team or individual who will own the model post-deployment?
If any of these factors cannot be answered, the initiative is not ready to proceed to model development. This is not a failure — it is a correct diagnosis that prevents a larger one. Explore how AI proof-of-concept engagements can help validate feasibility before full commitment.
Recognize when AI is not the appropriate solution
AI is not always the right answer. Rule-based automation, process redesign, better reporting, or simple statistical analysis may solve the problem faster, more cheaply, and with less operating risk. AI is appropriate when the input data is too complex or high-dimensional for manual rules, when patterns change over time in ways that static rules cannot capture, or when the volume of decisions exceeds human capacity at acceptable accuracy. In all other cases, simpler approaches should be evaluated first.
Decision principle: Begin an AI initiative by defining the business decision and measurable outcome. If that definition cannot be made specific, the project is not ready for model development.
2. Choose the Right AI Delivery Path
The delivery path — how a business accesses AI capability — is a strategic decision that affects cost, speed, data control, and long-term maintainability. The four primary options are: build a custom model, fine-tune an existing model, integrate via an API, or adopt a managed platform.
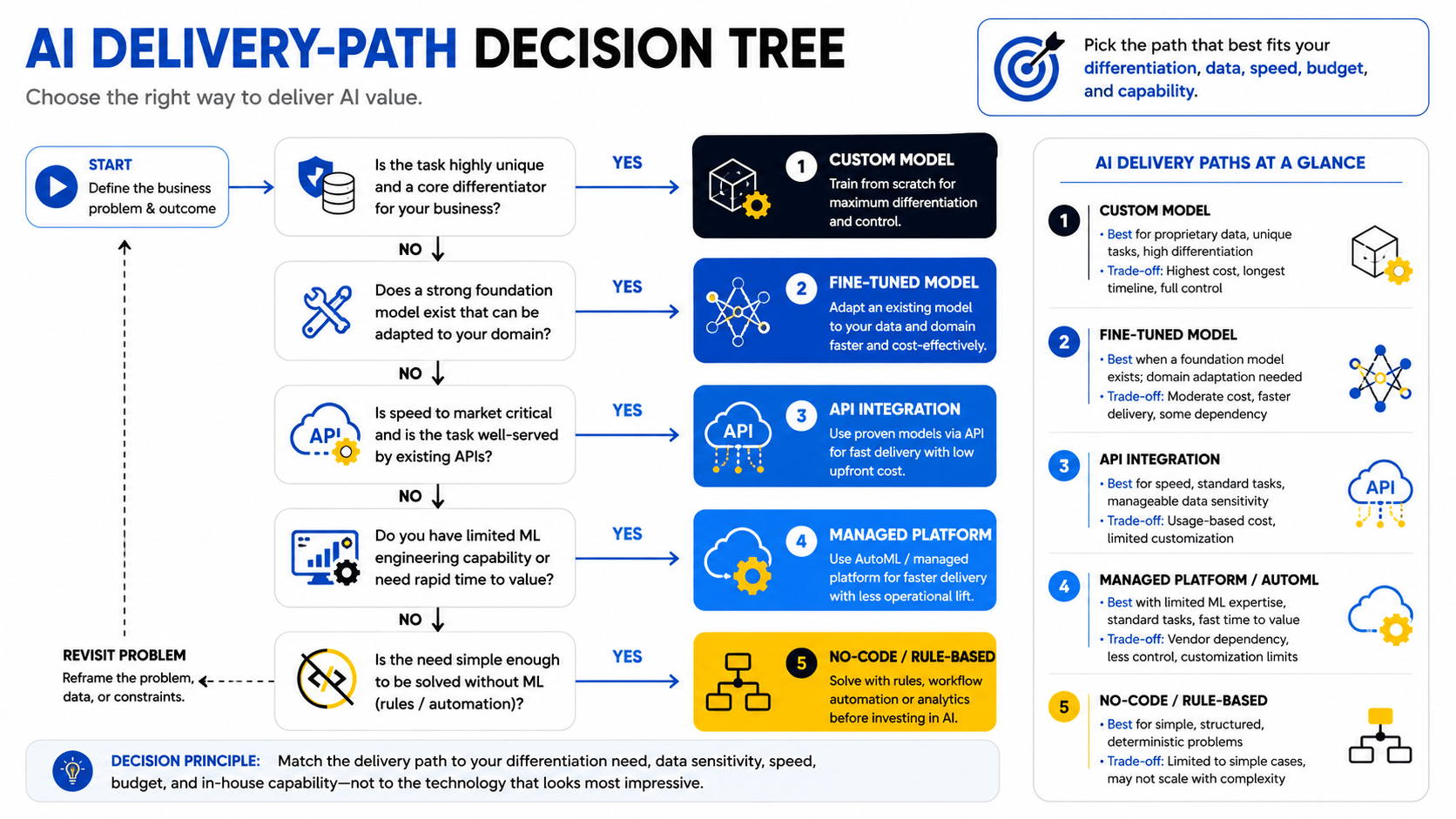
Build, fine-tune, use an API, or adopt a managed platform?
| Path | Best when | Key trade-off |
|---|---|---|
| Custom model (train from scratch) | Proprietary data, unique task, high differentiation requirement | Highest cost, longest timeline, full control |
| Fine-tuned model | General-purpose foundation model exists; domain adaptation needed | Moderate cost, faster delivery, some dependency on base model |
| API integration | Speed is priority; task is well-served by an existing model; data sensitivity is manageable | Low upfront cost; ongoing cost scales with usage; limited customization |
| Managed platform / AutoML | Limited ML engineering capability; standard task; fast time to value | Vendor dependency; less control; ceiling on customization |
Match delivery path to data sensitivity, differentiation, budget, speed, and capability
Use a custom model only when its business value exceeds the added data, engineering, and operating burden. Fine-tuning is often underutilized — it delivers most of the performance benefit of a custom model at a fraction of the cost, provided a suitable foundation model exists for the domain. API integration is appropriate when the task is generic, the data sent to a third-party model is not sensitive, and speed to market matters more than optimization. Managed platforms, including AutoML services from major cloud providers, are the right choice when internal ML expertise is limited and the task is well-defined.
Understand where no-code and AutoML approaches fit
No-code and AutoML tools — such as Google Cloud’s Vertex AI AutoML, Microsoft Azure Automated ML, and AWS SageMaker Autopilot — lower the barrier to entry for structured prediction tasks. They are well-suited to classification, regression, and demand forecasting on tabular data. They are not well-suited to tasks requiring domain-specific architectures, proprietary fine-tuning, or deep integration with internal systems.
Understanding this boundary helps teams avoid over-investing in platform lock-in before they know what the model actually needs to do. For a detailed comparison across implementation routes, see SmartDev’s AI and machine learning services overview.
Decision principle: Use a custom model only when its value exceeds the added data, engineering, and operating burden. Match path to constraint, not to ambition.
3. Understand AI Models and Select an Approach
An AI model is a mathematical system that learns patterns from data to make predictions, classifications, or generate outputs. It differs from traditional software in one fundamental way: instead of following explicitly programmed rules, it derives decision logic from examples. That distinction determines both its power and its risk.
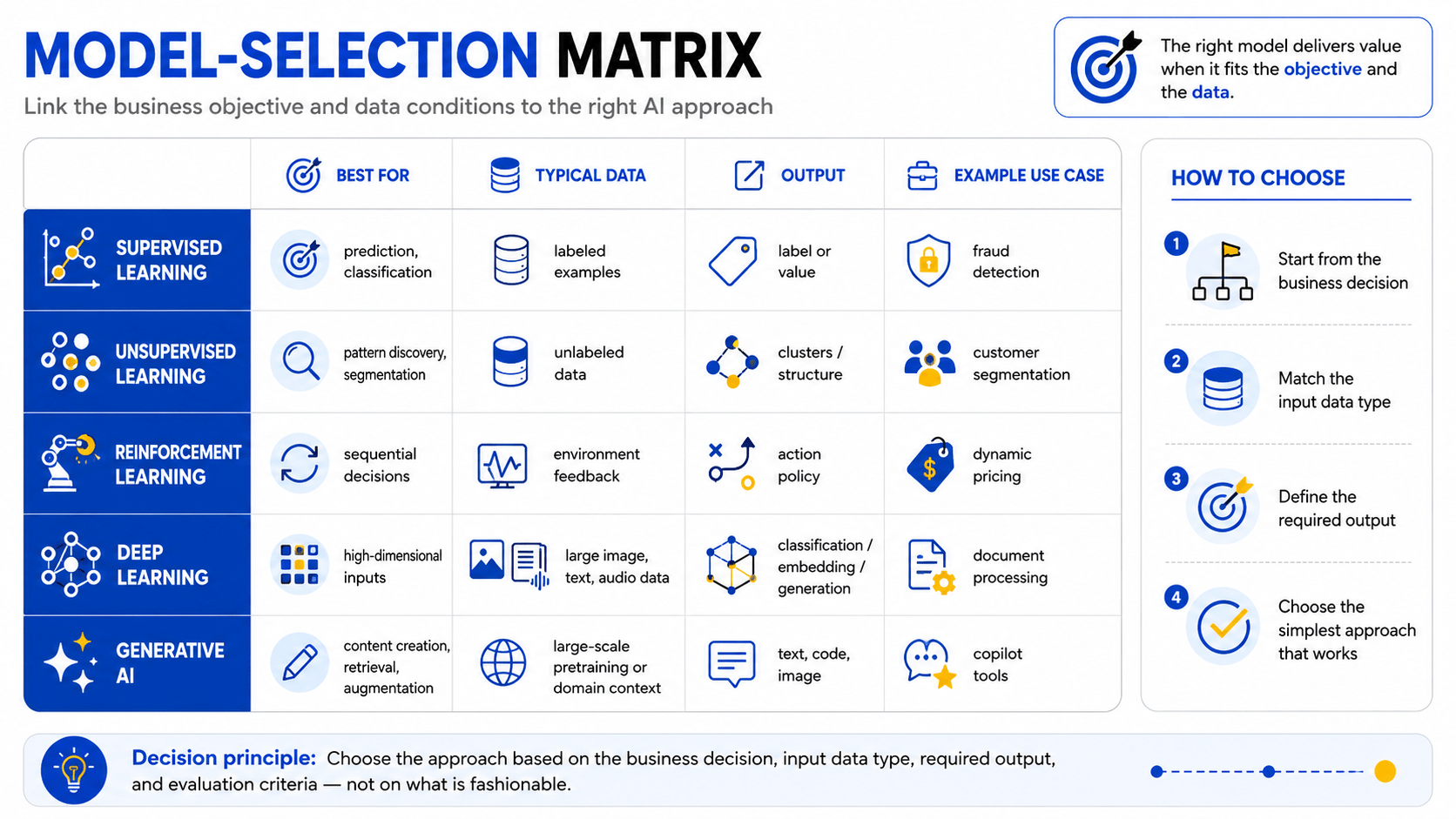
What an AI model is and how it differs from traditional software
Traditional software executes deterministic instructions — given the same input, it always produces the same output by design. An AI model produces outputs based on learned statistical relationships, which means its behavior is governed by the quality and representativeness of its training data, not by the programmer’s intent alone. This makes AI models flexible and capable of handling complex, variable inputs — and it makes data governance and evaluation non-negotiable, not optional.
Match the problem to the right AI approach
| Approach | Problem type | Output | Data requirement | Example use case |
|---|---|---|---|---|
| Supervised learning | Prediction, classification | Label or value | Labeled examples | Fraud detection, churn prediction |
| Unsupervised learning | Pattern discovery, segmentation | Cluster or structure | Unlabeled data | Customer segmentation, anomaly detection |
| Reinforcement learning | Sequential decision-making | Action policy | Environment feedback | Robotics, dynamic pricing |
| Deep learning | High-dimensional inputs (image, speech, text) | Classification, embedding, generation | Large labeled or unlabeled datasets | Image recognition, NLP, document processing |
| Generative AI | Content creation, retrieval, augmentation | Text, code, image, structured data | Large-scale pretraining data or domain fine-tuning | Copilot tools, document Q&A, report generation |
For a deeper breakdown of each category and when to apply it, see SmartDev’s guide to AI model types.
Understand model architecture without overengineering
Architecture — the structural design of how a model processes inputs and produces outputs — should be chosen based on the task, not on what is architecturally sophisticated. Convolutional neural networks (CNNs) process spatial data like images. Recurrent networks and transformers handle sequential data like text and time series. Gradient-boosted trees (XGBoost, LightGBM) consistently outperform deep learning on structured tabular data. Starting with the simplest architecture that plausibly solves the problem reduces development risk and establishes a meaningful baseline.
Decision principle: Choose the approach based on the business decision, input data type, required output, and evaluation criteria — not on what is currently fashionable.
4. Prepare Data and Governance Foundations
Data and governance readiness must be established before model development begins. A model is only as deployable as its data, permissions, and governance controls. Skipping this stage does not accelerate the project — it creates technical and legal debt that surfaces at the worst possible time: just before deployment.
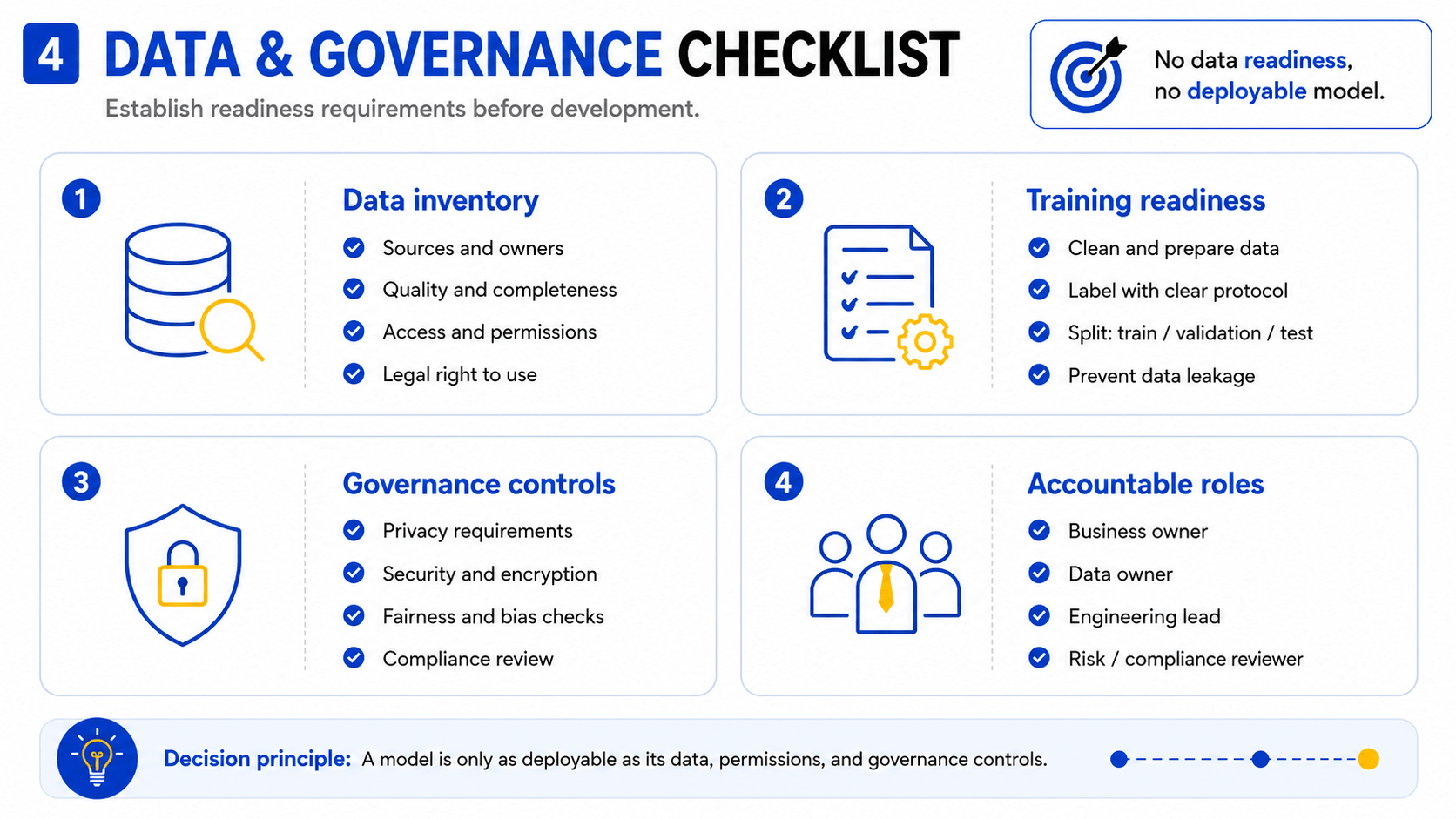
1. Define data sources, quality, access, and permissions
Data preparation starts with a complete inventory: what data exists, where it lives, who owns it, what format it is in, and whether the organization has the legal right to use it for model training. Data access permissions, licensing constraints, and third-party data agreements must be resolved before any model work begins.
Data quality evaluation should assess completeness (missing values), accuracy (labeling errors or measurement noise), consistency (format and schema alignment across sources), and representativeness (whether the data reflects the population the model will serve in production).
2. Prepare, label, and split data for training, validation, and testing
Cleaned data is split into three non-overlapping sets: training (used to fit the model), validation (used to tune hyperparameters and detect overfitting), and test (used once, at the end, to report final performance). The split ratio depends on total data volume, but a common starting point for moderate datasets is 70/15/15. For time-series data, the split must respect chronological order — random shuffling introduces data leakage that makes evaluation results unreliable.
Labeling quality is a direct driver of model quality in supervised learning. Human labeling should include a documented annotation protocol, inter-annotator agreement checks, and a review process for edge cases. Poor labeling cannot be corrected by a better algorithm.
3. Establish privacy, security, fairness, and compliance requirements
Privacy requirements depend on the jurisdiction and data type. In the European Union, the General Data Protection Regulation (GDPR) governs the use of personal data in automated decision-making, including requirements for data minimization, purpose limitation, and the right to explanation (GDPR Article 22). In the United States, sector-specific regulations — including HIPAA for health data and FCRA for credit decisions — apply additional constraints. Organizations operating across jurisdictions should obtain legal review of data use before training begins.
Fairness and bias assessment should be performed on training data before the model is built. Protected attributes — such as age, gender, race, or national origin — must be identified, and the data should be audited for historical bias that could produce discriminatory outputs. For a practical framework on this, see SmartDev’s guide to addressing AI bias and fairness.
Security controls for training data include access logging, encryption at rest and in transit, and data lineage documentation. These controls are not optional for regulated industries — they are prerequisites for audit compliance.
4. Set accountable roles for business, data, engineering, and risk stakeholders
Each AI project requires clearly assigned accountability across four roles: a business owner who defines and accepts the success criteria; a data owner who governs access, quality, and compliance; an engineering lead who is responsible for the model and its infrastructure; and a risk or compliance reviewer who signs off on governance requirements before deployment. Absent this structure, decisions stall, accountability gaps emerge, and post-deployment issues go unaddressed. For detail on the full privacy and data governance landscape, see SmartDev’s resource on AI and data privacy.
Decision principle: A model is only as deployable as its data, permissions, and governance controls. Establish these before writing any training code.
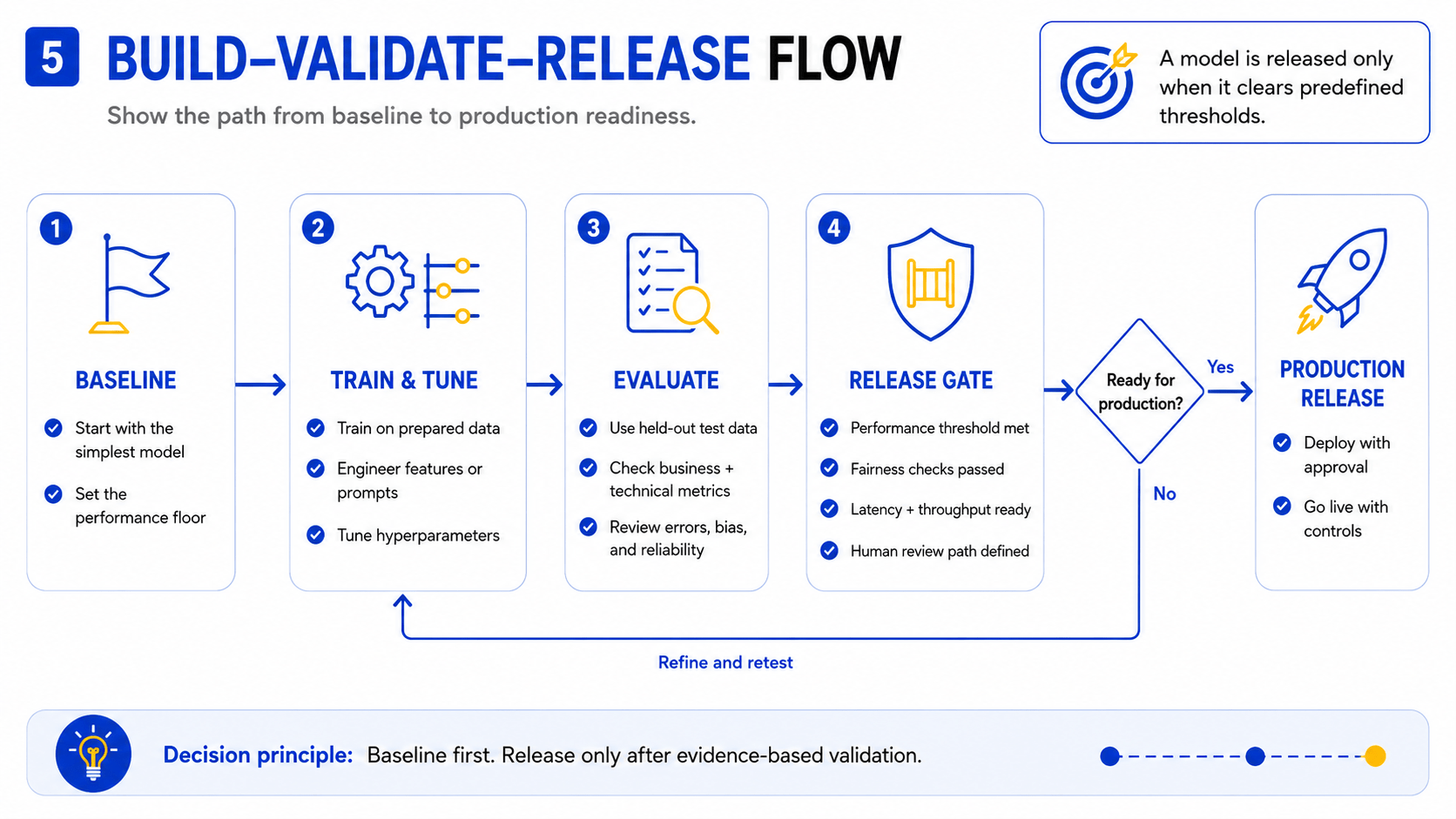
5. Build, Train, and Validate the Model
The build stage translates prepared data and a defined approach into a model that can be evaluated against real performance thresholds. The goal is not to build the most sophisticated model — it is to build one that meets predefined performance, reliability, fairness, and operational thresholds before deployment is authorized.
1. Select tools, frameworks, and infrastructure
Tool selection follows the delivery path established in Section 2. For custom model development in Python, the primary frameworks are TensorFlow and PyTorch for deep learning tasks, and scikit-learn and XGBoost for structured data. Cloud infrastructure from AWS, Google Cloud, or Azure provides scalable compute for training. For fine-tuning large language models, framework-specific tooling — such as Hugging Face Transformers — is the standard. Infrastructure choice should be driven by scale requirements and existing organizational capability, not by vendor marketing.
2. Build a baseline before adding complexity
Every model development process should begin with a baseline: the simplest possible model that can reasonably solve the problem. This might be a logistic regression, a decision tree, or a prompt-engineered call to an existing API. The baseline does two things: it establishes a performance floor against which more complex approaches are measured, and it exposes data and evaluation issues before significant engineering investment is made. A complex model that underperforms a simple baseline is a signal that the problem or data needs re-examination, not that the model needs more layers.
3. Train the model and manage features or prompts
Training involves feeding prepared data through the selected algorithm and optimizing model parameters to minimize prediction error. For traditional ML, this includes feature engineering — selecting, transforming, and creating input variables that capture the patterns relevant to the task. For deep learning, feature engineering is largely replaced by architectural choices and data augmentation. For generative AI and LLM-based approaches, prompt engineering and context management replace traditional feature work.
Hyperparameter tuning — adjusting settings such as learning rate, batch size, regularization strength, or tree depth — is a structured search for the configuration that generalizes best. Techniques include grid search, random search, and Bayesian optimization. Tuning should be performed on the validation set, never the test set. For a deeper treatment of the training process, see SmartDev’s guide to AI model training.
4. Evaluate performance with business-relevant and technical metrics
Model evaluation uses the held-out test set — data the model has never seen — to report performance. Metric selection depends on the task type and business consequence. A classification model used for fraud detection should prioritize recall (catching actual fraud) over accuracy, because a false negative (missed fraud) carries higher cost than a false positive (unnecessary review). A demand forecasting model should minimize MAE or MAPE, which translate directly to inventory cost. No single metric fits every use case; each metric choice should be justified by the business consequence it represents.
| Task type | Primary metrics | Business consequence they capture |
|---|---|---|
| Binary classification | Precision, recall, F1, AUC-ROC | Cost of false positives vs. false negatives |
| Regression / forecasting | MAE, RMSE, MAPE, R² | Magnitude and direction of prediction error |
| Multi-class classification | Macro/weighted F1, confusion matrix | Error distribution across outcome categories |
| Generative / LLM | BLEU, ROUGE, human eval, task-specific rubrics | Output relevance, accuracy, and safety |
For an in-depth guide to evaluation methodology, see SmartDev’s resource on AI model performance evaluation.
5. Diagnose overfitting, underfitting, bias, and error patterns
Overfitting — when a model performs well on training data but poorly on new data — is diagnosed by comparing training and validation metrics. A large gap between them indicates the model has memorized training examples rather than learning generalizable patterns. Remedies include regularization, simpler architectures, dropout, or more training data. Underfitting — when the model performs poorly on both sets — indicates the model lacks the capacity to capture the task’s complexity. Remedies include more expressive architectures, more features, or longer training.
Error analysis — reviewing specific examples where the model fails — often reveals more actionable insight than aggregate metrics alone. Patterns in failures frequently point to data quality issues, labeling inconsistencies, or underrepresented subgroups. For a complete guide to model testing methodology, see SmartDev’s AI model testing guide.
6. Decide whether the model is ready for production
A model is ready for production only when it meets all of the following: predefined performance thresholds on the test set; fairness and bias checks across relevant population subgroups; latency and throughput requirements for the intended deployment environment; documented failure modes and a human-review path for high-confidence-but-high-stakes decisions; and sign-off from the business owner, data owner, and risk reviewer. Releasing a model that has not cleared these gates shifts risk from the development team to the business — and to users.
Decision principle: A model is ready only when it meets predefined performance, reliability, fairness, and operational thresholds — not when development time runs out.
6. Deploy the Model Into a Business Workflow
Deployment connects the model to the users, systems, and controls that determine whether it delivers business value. Deployment is not the end of the project — it is the beginning of its operating life. The deployment pattern should follow the workflow requirements, latency constraints, security controls, and integration needs of the target environment.
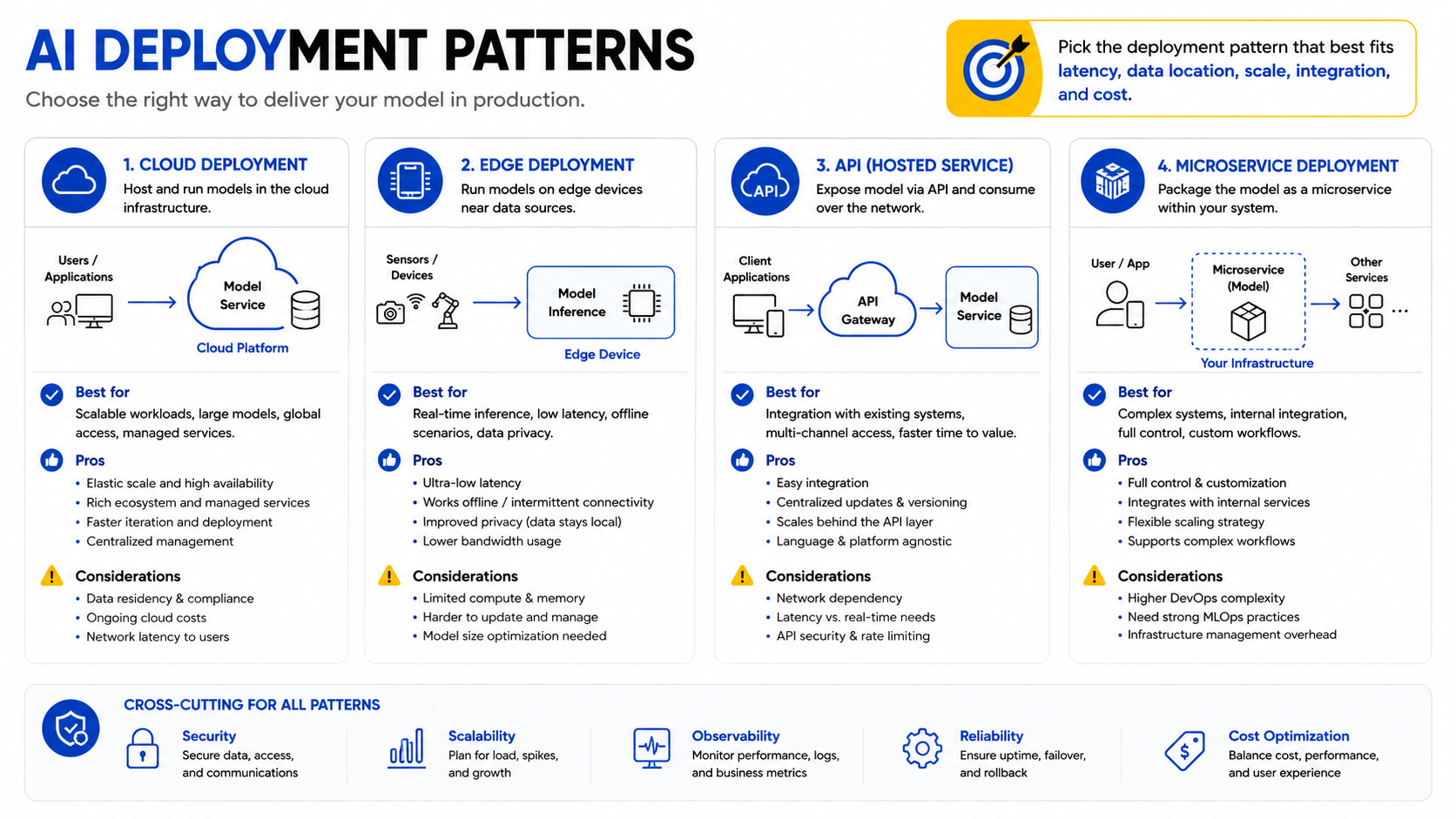
1. Choose cloud, edge, API, or microservice deployment patterns
Cloud deployment — using managed services from AWS SageMaker, Google Vertex AI, or Azure Machine Learning — is appropriate for most enterprise use cases. It provides scalable infrastructure, managed versioning, and built-in monitoring tools. Cloud deployment is the default choice unless specific constraints apply.
Edge deployment runs the model on a local device — a smartphone, an IoT sensor, or an on-premise server — without sending data to the cloud. This pattern is appropriate when latency requirements are extreme (milliseconds), data cannot leave the local environment for security or regulatory reasons, or connectivity is intermittent. Frameworks such as Apple CoreML and NVIDIA Jetson support edge inference for mobile and robotics applications.
API deployment wraps the model in a service endpoint that existing applications can call without exposing model internals. This is the most common pattern for integrating AI into existing software systems. Microservice deployment extends this pattern, isolating the model in an independently deployable service that can be scaled, updated, and rolled back without affecting other system components. This pattern is well-suited to teams with existing DevOps infrastructure and CI/CD pipelines. For an overview of how SmartDev approaches API-based AI integration, see the AI-powered software development solutions page.
2. Integrate the model with users, systems, and business processes
Technical deployment is necessary but not sufficient. The model must be integrated into the workflow where it will be used: connected to the data sources it reads from, the systems it writes to, and the interfaces through which users interact with its outputs. Integration failures — broken data pipelines, mismatched output formats, or disconnected downstream systems — are a frequent cause of post-deployment failure that has nothing to do with model quality.
3. Establish release, versioning, testing, and rollback controls
Production AI systems require the same release engineering discipline as production software. Version every model artifact alongside the code and data pipeline that produced it. Use canary or blue-green deployment strategies to release new model versions incrementally, routing a small percentage of traffic to the new version before full rollout. Automated regression tests should run against every new model version before promotion. A documented rollback procedure — including the trigger criteria, the responsible owner, and the time target for rollback execution — must exist before any model goes live.
4. Define the human-review path for high-impact decisions
For decisions with significant consequences — loan approvals, clinical recommendations, employment screening, content moderation — a human-in-the-loop review path is both an ethical requirement and, in many jurisdictions, a legal one. The review path should define which predictions trigger human review (typically those above a confidence threshold that carries high stakes, or those below a confidence threshold that indicates model uncertainty), who performs the review, what information they are shown, and how their decision is recorded. Deployment architecture must support this path from the start, not as an afterthought.
Decision principle: Deployment includes integration, controls, monitoring hooks, and a rollback plan — not only hosting. A model that cannot be rolled back safely should not be deployed.
7. Operate, Monitor, and Improve the Model
Post-deployment operations are where most AI projects either sustain their value or quietly fail. A model released without a defined operating owner, monitoring plan, and retraining trigger will degrade over time — not because the model was poorly built, but because the world it was built to model will change.
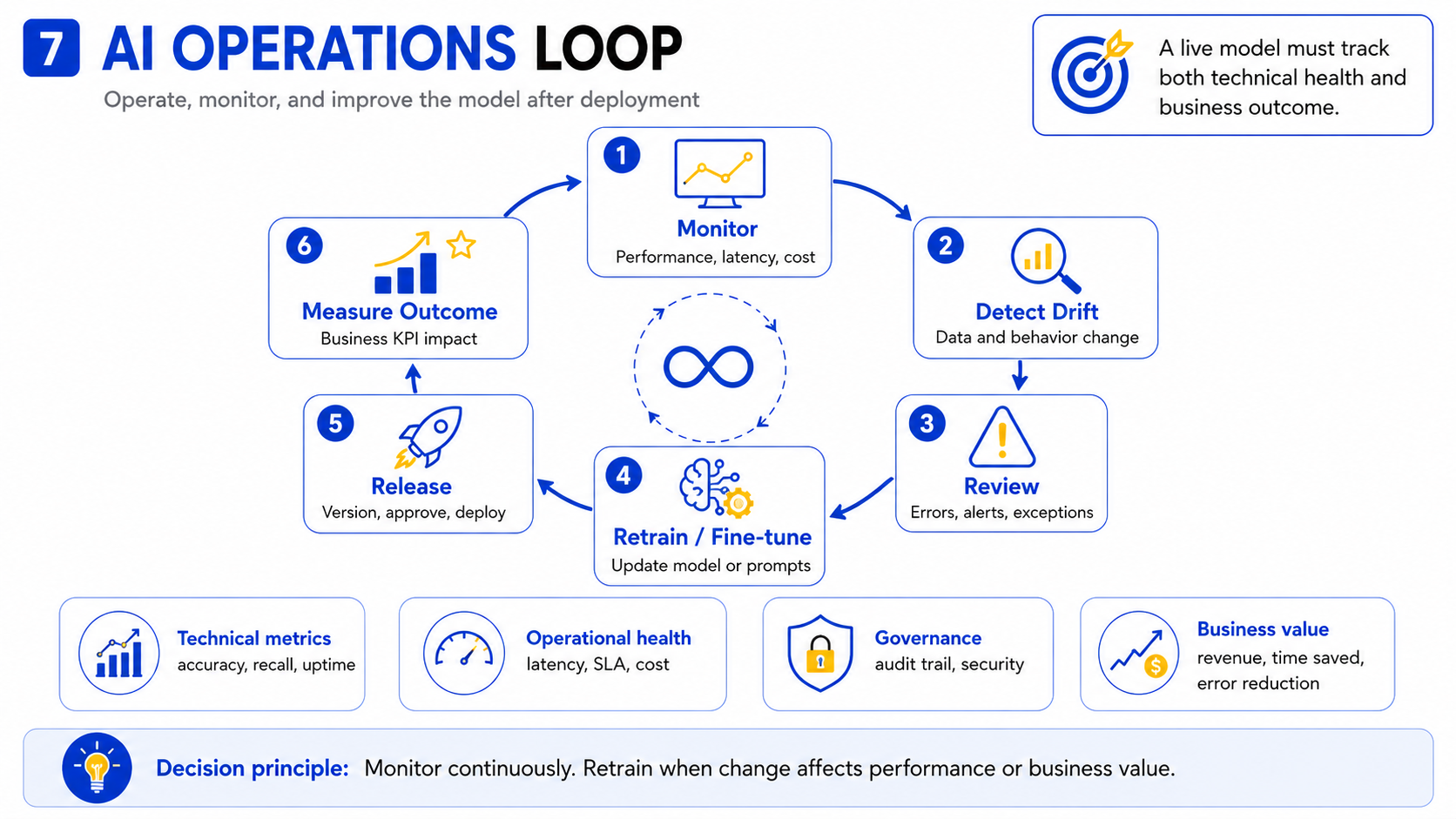
Monitor performance, data drift, cost, latency, and user outcomes
Effective model monitoring covers five dimensions. Technical performance: are accuracy, precision, recall, or other task-specific metrics holding within the thresholds set at release? Data drift: has the distribution of incoming data changed in ways that make the training data less representative? This is the most common cause of silent model degradation. Operational performance: are latency and throughput within SLA? Cost: is inference cost tracking within budget as usage scales? Business outcome: is the metric the model was built to improve — revenue, error rate, processing time, customer satisfaction — still moving in the right direction?
Tools such as Evidently AI and Arize AI provide automated monitoring and alerting for production ML systems, including drift detection and performance tracking without requiring custom instrumentation from scratch.
Retrain, fine-tune, or replace the model when conditions change
Retraining triggers should be defined before deployment, not after degradation is observed. Common triggers include: a monitored metric crossing a predefined threshold; a scheduled calendar interval (monthly or quarterly retraining for slowly-changing domains); a detected data distribution shift above a statistical threshold; or a significant change in the business environment — a new product line, a regulatory change, or a structural market shift. The decision between retraining (using the same architecture on new data), fine-tuning (adapting a current model to a shift), and replacing (building or selecting a new model) depends on the nature and magnitude of the change. For a deeper treatment of the full lifecycle, see SmartDev’s guide to the AI development lifecycle.
Maintain governance, security, documentation, and auditability
Production AI systems must be auditable: every model version should have documented training data provenance, evaluation results, approval records, and deployment history. Security monitoring should cover adversarial input attempts, data pipeline integrity, and unauthorized access to model endpoints. Governance documentation — including the original business objective, the approved evaluation thresholds, and the human-review criteria — should be maintained and updated with each model version. In regulated industries, this documentation is not administrative overhead; it is the evidence base for compliance audits.
Review model value against the original business objective
At regular intervals — no less than quarterly for live production models — the business owner should review whether the model is still delivering measurable value against the original objective. This review may conclude that the model needs retraining, that the objective has changed, or that the model should be retired and replaced with a different approach. Treating this review as routine, rather than exceptional, prevents the accumulation of technical and business debt from models that are running but no longer useful.
Decision principle: Model operations must track both technical performance and the business outcome the model was built to improve. A technically healthy model that is not improving the business outcome should be re-examined.
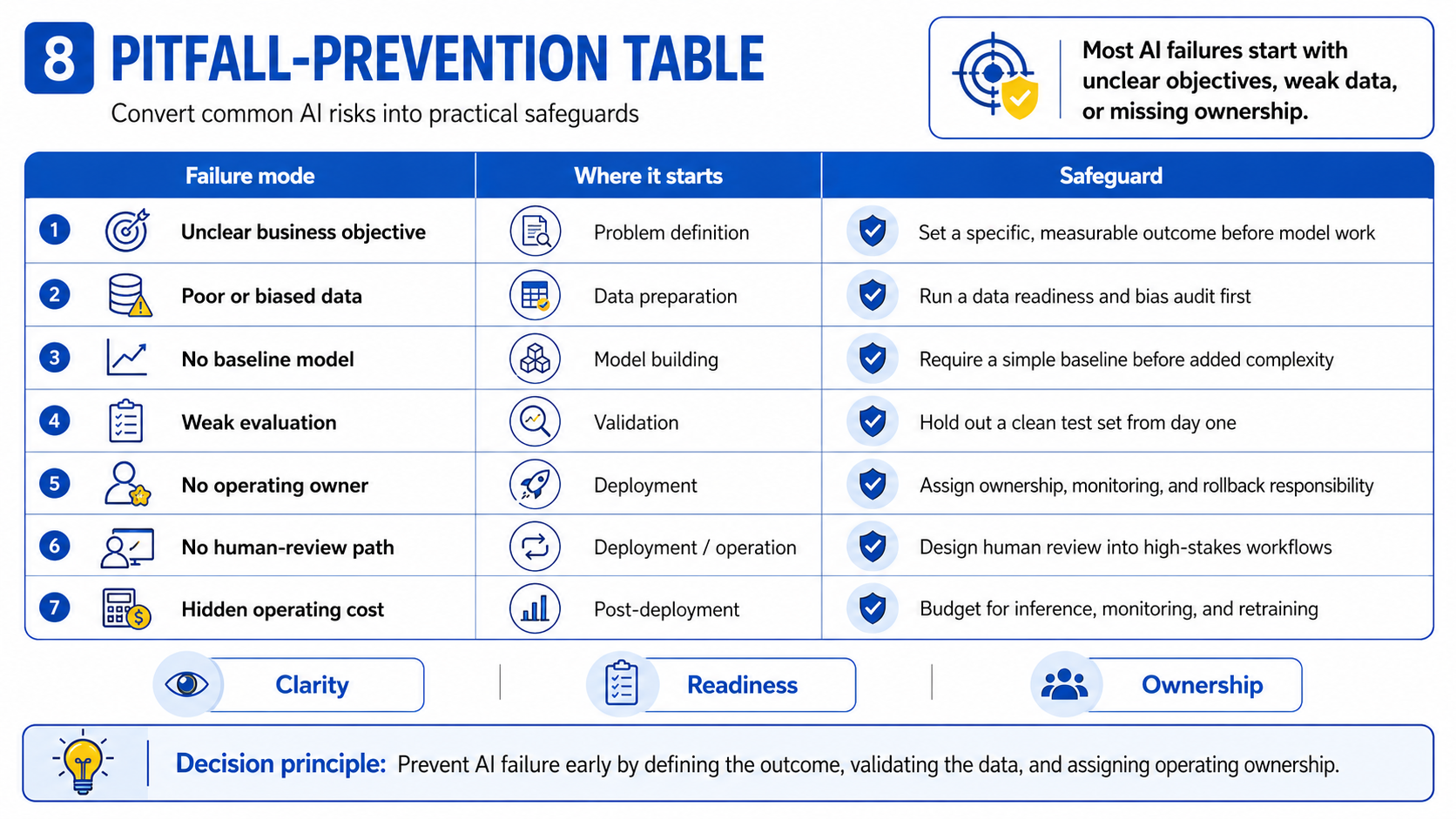
8. Common Pitfalls and How to Avoid Them
Most avoidable AI failures originate in unclear objectives, weak data, or missing operating ownership — not in model architecture. The table below maps common failure modes to the lifecycle stage where they originate and to the preventive action that addresses each one.
| Failure mode | Lifecycle stage | Prevention action |
|---|---|---|
| Undefined business outcome or success metric | Problem definition | Require a specific, measurable objective before any technical work is authorized |
| Poor-quality, inaccessible, or biased training data | Data preparation | Complete a data readiness audit before model development begins |
| No baseline established before adding complexity | Model building | Require a simple baseline model as the first deliverable; gate complexity on baseline performance |
| Evaluation performed on training or validation data only | Evaluation | Hold out a clean test set from the start; report final metrics only from this set |
| Deployment treated as the project end point | Deployment | Name an operating owner before deployment; define monitoring, retraining triggers, and rollback criteria |
| No human-review path for high-stakes decisions | Deployment / operation | Design human review into the architecture before go-live, not as a retrofit |
| Adoption, governance, and operating costs ignored | Post-deployment | Include inference cost, monitoring tooling, and retraining labor in the project budget from the start |
For a detailed treatment of bias-related pitfalls and the governance frameworks that address them, see SmartDev’s guide to AI bias and fairness challenges. For data privacy pitfalls specific to AI development, see the AI and data privacy guide.
9. Practical Business Scenarios
The right delivery path, model approach, and operating model vary with the business decision, data conditions, risk profile, and reliability requirements of each use case. The three scenarios below illustrate how the framework applies across common AI problem types.
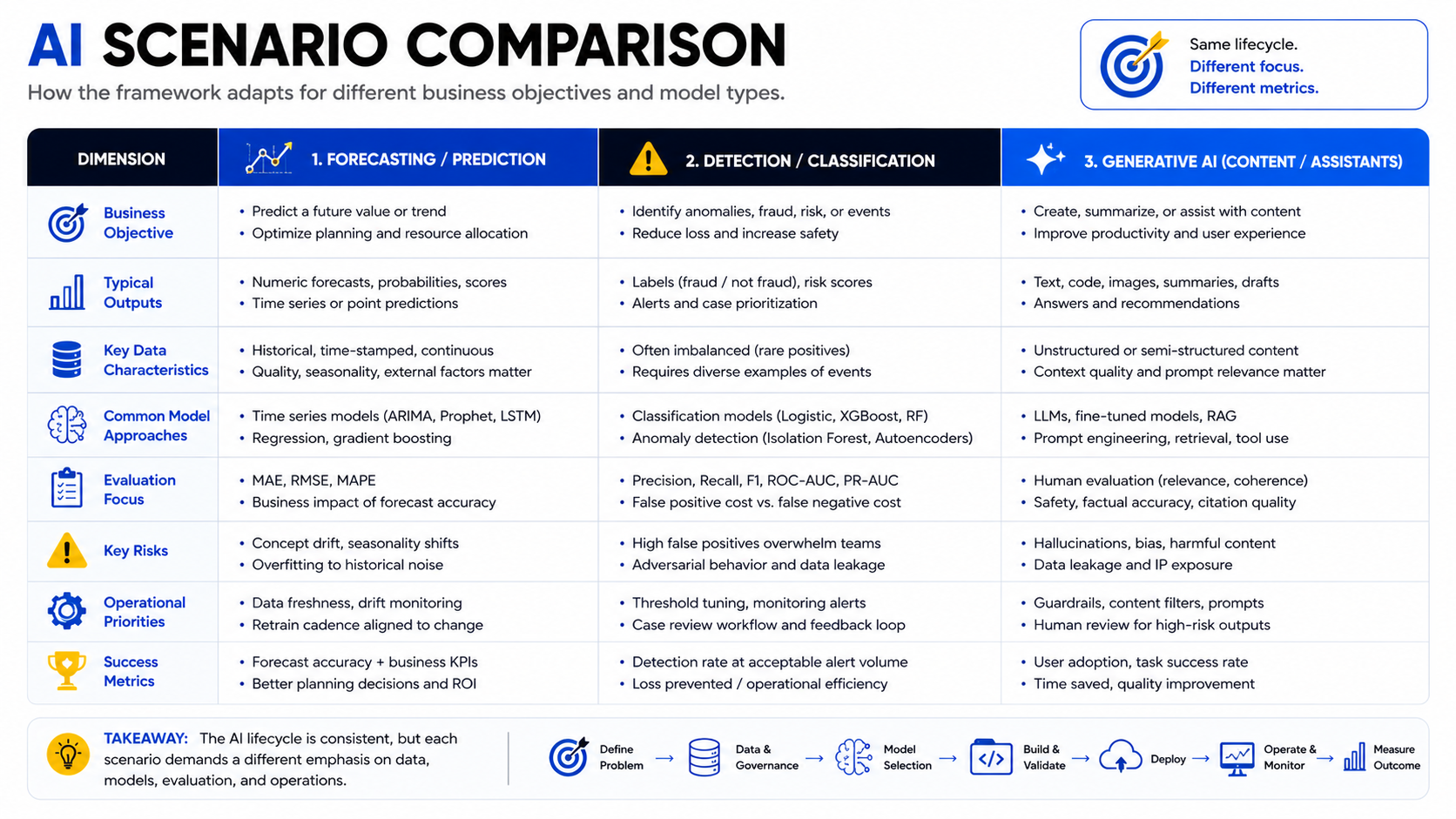
Predictive models for forecasting and risk decisions
Illustrative scenario: A financial services company wants to automate early identification of accounts likely to default within 90 days.
- Delivery path: Custom supervised model, trained on proprietary transaction and behavioral data that cannot be sent to a third-party API
- Approach: Gradient-boosted tree (XGBoost or LightGBM) on structured tabular data; baseline with logistic regression
- Key metrics: Recall (to minimize missed defaults), precision (to limit false positives that trigger unnecessary intervention), AUC-ROC for threshold selection
- Operating risk: Data drift as economic conditions change; regulatory requirement for explainable decisions; human review required before any adverse action
Classification and detection models for operational workflows
Illustrative scenario: A manufacturer wants to automate quality defect detection on a production line using camera footage.
- Delivery path: Fine-tuned computer vision model, adapted from a pre-trained image classification foundation; edge deployment on production line hardware for low latency
- Approach: Convolutional neural network fine-tuned on domain-specific defect images; baseline with traditional image processing rules
- Key metrics: Recall for defect detection (cost of a missed defect exceeds cost of a false alarm); inference latency (<100ms at line speed)
- Operating risk: Visual environment change (lighting, product variants); need for periodic retraining as new defect types emerge
Generative AI and retrieval-based systems for knowledge work
Illustrative scenario: A professional services firm wants to reduce the time analysts spend retrieving and summarizing information from internal policy documents and research reports.
- Delivery path: Retrieval-augmented generation (RAG) system using an API-accessed LLM with a private document index; no proprietary fine-tuning required for initial deployment
- Approach: Embedding model for document retrieval; prompt-engineered LLM for summarization and Q&A; human review on high-stakes outputs
- Key metrics: Retrieval accuracy (are the right documents surfaced?); answer faithfulness (does the output reflect the source documents?); task time reduction for analysts
- Operating risk: Hallucination on documents not in the index; document freshness as policies update; data access controls on sensitive internal content
For how these patterns apply in finance and operations contexts specifically, see SmartDev’s resources on AI in financial services and MLOps services.
FAQ: Creating an AI Model
Can a business create an AI model without building one from scratch?
Yes. Fine-tuning an existing foundation model, integrating a third-party API, or using a managed AutoML platform are all valid routes to production AI capability. Building from scratch is appropriate only when the task requires proprietary architecture, the training data cannot be shared with an external provider, or the differentiation value justifies the full development cost. See Section 2 for a decision framework across all four paths.
What data is required to train an AI model?
Data requirements depend on the task type and approach. Supervised learning requires labeled examples — the volume and quality needed varies with problem complexity, but underprepared or biased data will limit model performance regardless of algorithm sophistication. Generative AI and fine-tuning approaches require domain-relevant text, code, or structured data for adaptation. All approaches require data that is representative of the production environment, cleaned, permissioned, and split into training, validation, and test sets before training begins. See Section 4 for a complete data readiness checklist.
How do you choose between machine learning and generative AI?
Choose supervised machine learning when the task involves predicting a defined output from structured inputs — classification, regression, ranking, or forecasting. Choose generative AI when the task involves producing free-form content, answering questions over documents, generating code, or handling unstructured language inputs and outputs. The two categories are not mutually exclusive: many production systems combine structured ML models with generative components. The decision turns on the input data type, the required output format, and the evaluation criteria. See Section 3’s model-selection matrix for a structured comparison.
How do you know whether an AI model is ready to deploy?
A model is ready for deployment when it has met all predefined performance thresholds on the held-out test set, passed fairness and bias checks across relevant population subgroups, satisfied latency and throughput requirements, completed integration testing in a staging environment, and received sign-off from the business owner, data owner, and risk reviewer. Releasing before these gates are cleared shifts operational and reputational risk to the business. See Section 5 for the full production-readiness criteria.
How often should an AI model be monitored or retrained?
Monitoring should be continuous from the day of deployment — automated alerts on performance metrics, data drift, and operational SLAs remove the dependency on manual checks. Retraining frequency depends on the rate of change in the underlying data environment: fast-changing domains (fraud, demand forecasting, financial markets) may require monthly retraining; slower-changing domains (document classification, stable process automation) may sustain performance for a year or more. Retraining should be triggered by monitored thresholds, not by a fixed calendar schedule alone. See Section 7 for a full operating scorecard framework.
Conclusion
Successful AI models are operating capabilities, not one-time technical projects. They require a defined business problem, a matched delivery path, governed and representative data, evidence-based evaluation, integrated deployment, and sustained operating ownership. Every stage in this lifecycle is a decision point — and each decision shapes whether the model delivers lasting business value or becomes another AI initiative that failed to reach its potential.
The core principle is consistent across use cases and organization sizes: start with the problem, select the path that fits your constraints, prepare the data and governance before writing training code, validate against predefined thresholds, deploy with controls, and operate with measurement. Organizations that follow this sequence build models that are maintainable, auditable, and aligned to the outcomes that justified the investment.
Next Steps: Plan Your AI Model Initiative
Where you go next depends on where your organization currently stands:
- Still defining the problem? Start with Section 1 and complete the AI Opportunity Canvas to establish your baseline, decision criteria, and feasibility assessment before any technical work is authorized.
- Evaluating delivery paths? Use the Section 2 decision matrix to map your data sensitivity, budget, speed requirements, and in-house capability to the right implementation route.
- Ready to build? Review Sections 4 and 5 for data readiness and production-readiness criteria, then explore SmartDev’s AI development services or the 3-Week AI Discovery Program as a structured entry point.
- Already deployed and looking to improve operations? Section 7’s operating scorecard and the SmartDev MLOps services page cover monitoring, drift management, and retraining frameworks.
If you would like expert support at any stage — from problem definition through production operation — reach out to SmartDev’s team to discuss your specific use case.
–
References
- GDPR Article 22 — Automated individual decision-making, including profiling, EUR-Lex / GDPR-info.eu
- Google Vertex AI documentation, Google Cloud
- Core ML framework documentation, Apple Developer
- Arize AI — ML observability and monitoring platform, Arize AI
- AWS SageMaker — Machine learning platform documentation, Amazon Web Services
- Hugging Face Transformers documentation, Hugging Face
- ISO/IEC 42001:2023 — Artificial intelligence management system standard, International Organization for Standardization










