
95% of enterprise AI pilots fail to deliver measurable impact, with multinational chatbot deployments facing even steeper odds. The culprit isn’t technical complexity—it’s avoidable strategic mistakes that CTOs make during planning and development phases.
Multilingual NLP chatbots demand fundamentally different architecture decisions than single-language implementations. CTOs must navigate language-specific AI model performance, cultural communication patterns, and regulatory compliance across multiple jurisdictions simultaneously. Nearly 90% of large enterprises pursue digital transformation but project success rates consistently fall below 40%, making these pitfalls critical to understand for global market expansion.
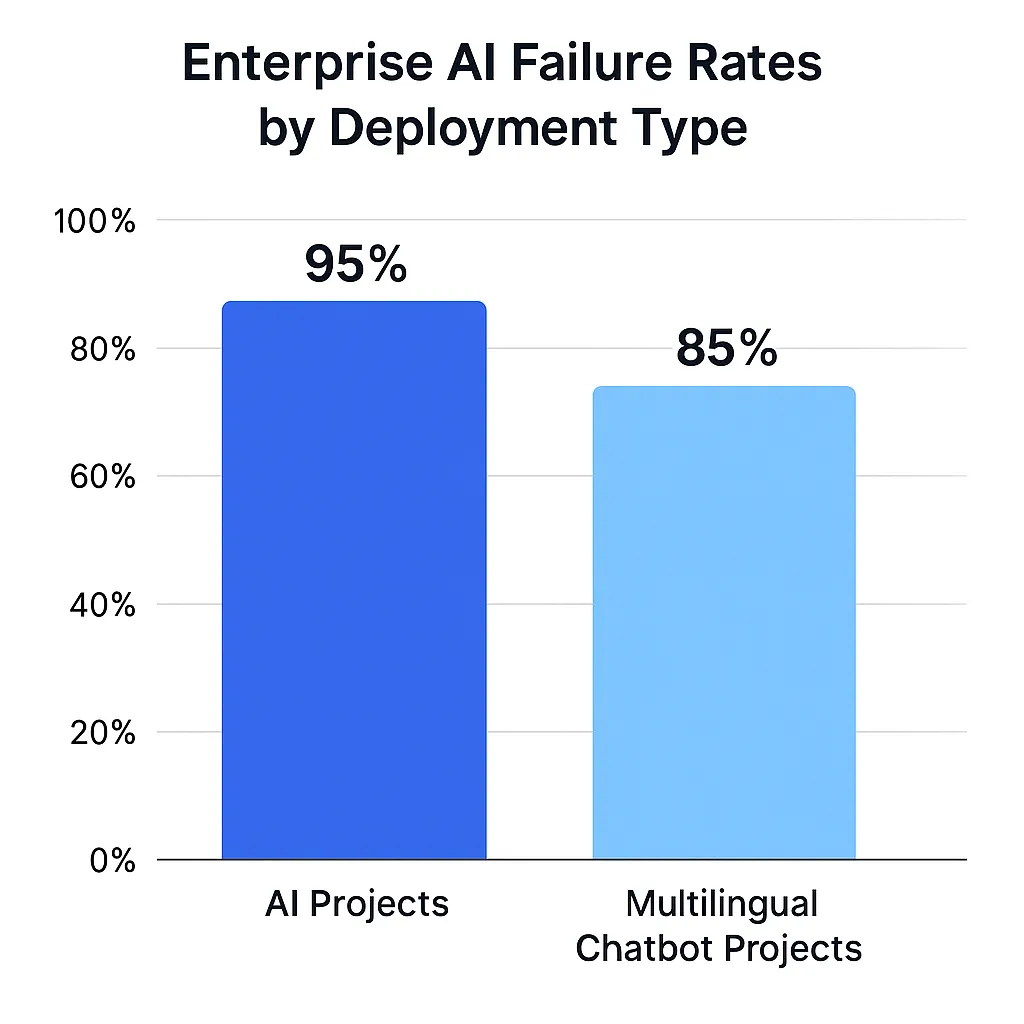
Fig1. Enterprise AI failure rates by deployment type
The stakes are particularly high in regulated industries where chatbot failures trigger compliance violations, user abandonment, and competitive disadvantage across diverse cultural markets.
The Seven Deadly Mistakes That Kill Global Chatbot Success
CTOs building multilingual chatbots face seven critical pitfalls that derail global deployments:
- Wrong language model architecture – Universal models vs. language-specific clusters
- Cultural context misalignment – Ignoring high-context vs. low-context communication styles
- Inadequate data strategies – English-heavy training datasets and translation artifacts
- Scalability oversights – Resource multiplication and latency issues
- Compliance gaps – Data sovereignty and jurisdiction-specific requirements
- Testing inadequacies – English-only QA missing real-world multilingual scenarios
- Integration failures – Legacy system incompatibility with Unicode and RTL scripts
Properly implemented solutions deliver 4-7x better engagement in non-English markets despite 3-5x higher development costs.
Critical Mistake #1: Universal Models Kill Accuracy in Multilingual Contexts
Universal language models degrade accuracy compared to language-specific approaches, with some benchmarks showing performance drops up to 30% when handling structurally different languages. CTOs often underestimate how this architectural decision impacts long-term performance and user satisfaction.
The temptation to use a single model stems from cost and complexity concerns, but this approach fails catastrophically when dealing with structurally different languages. Arabic, Chinese, and Finnish have vastly different grammatical patterns that universal models struggle to handle consistently.
Why Token Multiplication Destroys Performance
Context window limitations create another challenge many CTOs overlook. A conversation requiring 1,200 tokens in English can demand 1,800-2,400 tokens when switching between languages with different grammatical structures. This token multiplication affects both response latency and operational costs.
Performance degradation accelerates exponentially (not linearly) when handling code-switching within conversations. CTOs should plan for 40-60% accuracy drops during multilingual conversations to set appropriate success metrics.
Best Practice: Language-specialist model clusters outperform universal approaches, particularly for languages with different writing systems or grammatical structures.
Critical Mistake #2: Cultural Communication Patterns Destroy User Experience
Chatbots designed for direct, low-context communication see significantly higher error rates when deployed in high-context cultures like Japan and the Middle East. This failure stems from fundamental misunderstandings about how different cultures approach digital interactions.
Western direct communication patterns catastrophically fail in high-context cultures that rely heavily on:
- Implicit understanding and contextual cues
- Relationship acknowledgment protocols
- Hierarchical recognition patterns
- Power distance expectations
Communication Style Mapping by Region
High-Context Markets:
- Japan: Hierarchical acknowledgment, implicit formality cues
- Middle East: Relationship-building before task completion
- Korea: Age/status recognition protocols
Low-Context Markets:
- Germany: Formal, structured interactions initially
- United States: Casual, direct task completion
- Scandinavia: Efficiency-focused, minimal pleasantries
Cultural taboos and sensitive topics represent another critical oversight. Failing to implement culture-specific content filtering leads to brand damage and legal complications across different markets.
Critical Mistake #3: English-Heavy Training Data Creates Performance Bias
Training multilingual models with English-heavy datasets creates performance bias that favors English speakers over other language users. As documented in SmartDev’s multimodal AI research, Meta’s Seamless M4T represents best practices with translation and transcription across nearly 100 languages using both text and voice inputs, demonstrating that multilingual training with balanced language representation achieves superior contextual understanding by processing diverse data sources together, while academic research training six identical 2.6B parameter LLMs—five monolingual and one multilingual trained on equal distribution of data across English, German, French, Italian, and Spanish—consistently demonstrates that multilingual training with balanced language representation effectively mitigates bias and achieves not only lower bias but also superior prediction accuracy compared to monolingual models.
CTOs who maintain balanced data representation per target language—as evidenced by the equal-distribution multilingual training approach—report measurable improvements in NLP parity across languages, with multilingual models showing better overall accuracy and reduced bias compared to their monolingual counterparts.
The Translation Artifact Problem
Relying primarily on translated training data instead of native language conversations reduces chatbot naturalness by 35-45%. Machine-translated training data introduces artifacts that make responses sound artificial to native speakers, undermining user trust and engagement.
Native content requirements:
- Mexican Spanish differs significantly from Argentinian Spanish in vocabulary, formality expectations, and cultural references
- Mainland Chinese vs. Hong Kong Cantonese require separate model training
- Egyptian Arabic vs. Gulf Arabic have distinct conversational patterns
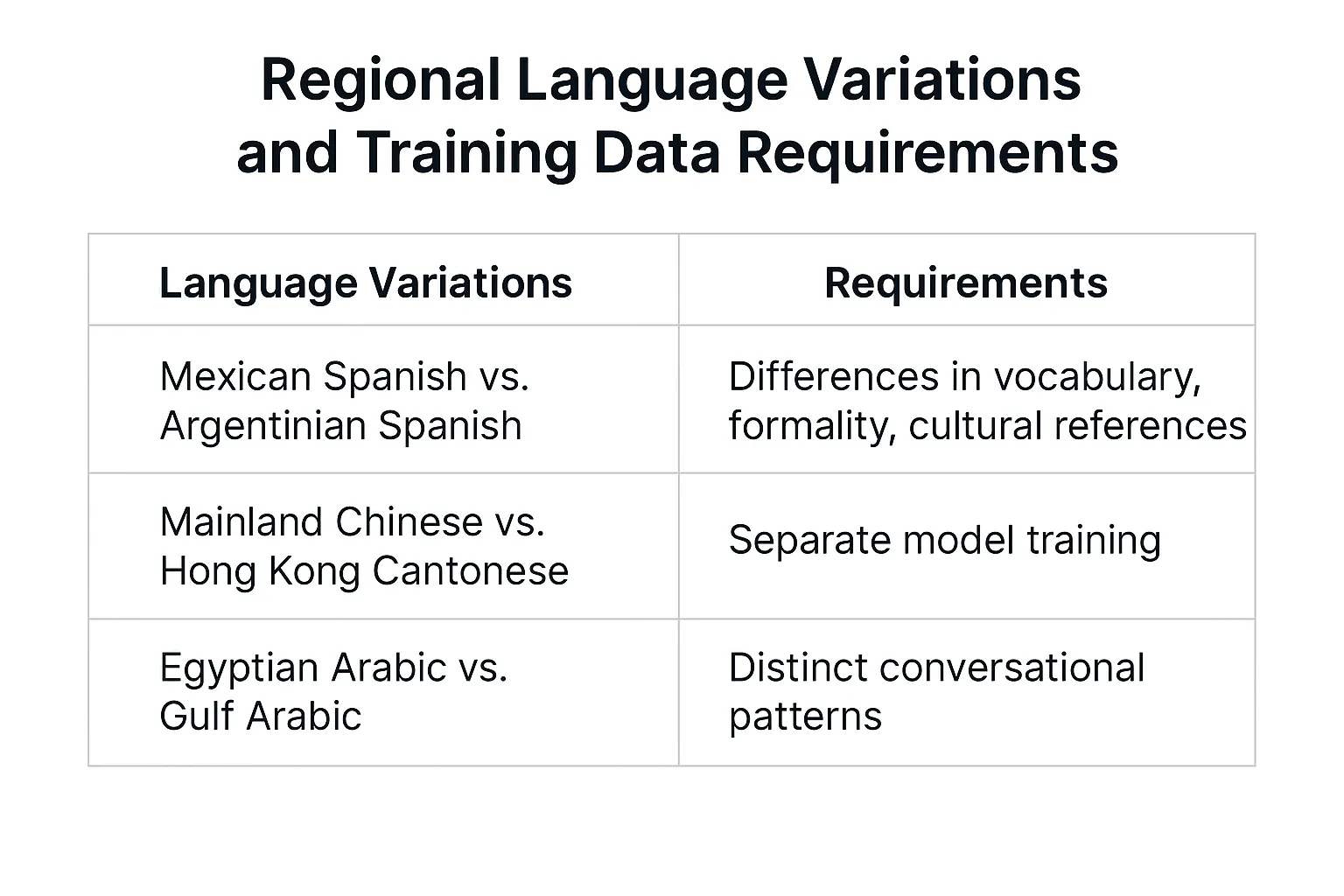
Fig2. Regional language variations and training data requirements
Leading NLP vendors now require dialect detection for Chinese, Arabic, and Spanish, with regional segmentation as standard practice for chatbots targeting more than 10,000 monthly users.
Critical Mistake #4: Infrastructure Planning Failures Create Latency Disasters
Multilingual NLP processing requires 2-4x more computational resources than English-only implementations. CTOs who don’t plan for this resource multiplication face performance degradation during traffic spikes and unexpected cost escalations.
Edge Deployment Becomes Critical
Centralizing language models in single data centers creates unacceptable latency for global users. Edge deployment strategies become critical when response times exceed 800ms in multilingual contexts, but many CTOs underestimate the complexity of distributing specialized language models geographically.
Resource scaling challenges:
- Japanese-Arabic conversations require different computational resources than English-Spanish interactions
- Standard auto-scaling triggers designed for uniform workloads fail with multilingual chatbots
- Language-aware scaling policies require sophisticated monitoring and prediction algorithms
Top-performing multilingual chatbots use geo-aware auto-scaling policies. As documented in SmartDev’s enterprise chatbot development research, AI chatbots scale to handle multilingual interactions seamlessly, enabling businesses to serve diverse markets with omnichannel integration across websites, mobile apps, and social media while managing larger volumes of inquiries without increasing resource costs through dynamic scaling, while academic research on heterogeneous autoscaling demonstrates that workload-centric autoscaling pipelines maintain optimal prefill/decode ratios throughout workload fluctuations, reducing GPU usage by 41.3% while stabilizing latency metrics (TTFT and TBT) compared to uniform scaling approaches, with LLMOps best practices confirming that auto-scaling dynamically adjusts compute resources based on real-time demand patterns, ensuring businesses scale up during peak usage and scale down during low-traffic periods, while geographical distribution directs requests to regional data centers closest to users to reduce latency and improve response times.
Uniform scaling models underperform during peak traffic conditions by significant margins—up to 41.3% higher resource consumption and unstable latency—compared to intelligent geo-aware and workload-adaptive autoscaling strategies.
Avoid the hidden pitfalls that derail multilingual chatbot projects before launch.
Learn from SmartDev’s AI and localization experts how to architect GPT-4-powered chatbots that deliver culturally accurate, compliant, and scalable conversations across languages.
Prevent costly mistakes in data handling, translation logic, and compliance — and position your chatbot for sustainable global growth.
Read the 7 Critical Mistakes CTOs Must AvoidCritical Mistake #5: Data Sovereignty Violations Trigger Massive Compliance Risks
In 2025, multinational deployments face complex data sovereignty requirements when storing cross-border conversations. As documented in SmartDev’s comprehensive analysis of healthcare AI compliance, Southeast Asian data sovereignty laws create significant cross-border restrictions: Singapore’s Healthcare Services Act requires all patient data processing within national borders, Malaysia’s Personal Data Protection Act 2010 mandates explicit consent for cross-border transfers, Thailand’s PDPA classifies healthcare data as “special category personal data” requiring enhanced local processing protections, and Indonesia’s data localization laws similarly restrict offshore processing of sensitive information, while organizations operating across multiple regions must navigate overlapping regulations including GDPR, China’s PIPL, and India’s DPDP, requiring organizations to map where data resides, how it flows, whether transfers are lawful, whether localization obligations apply, and whether contractual and technical safeguards are in place. Multi-location providers face the challenge of complying with 5+ distinct data localization laws simultaneously, making standardized offshore solutions practically impossible to implement legally.
Financial Services Face Additional Compliance Complexity
Financial services chatbots must comply with language-specific disclosure requirements that vary by jurisdiction:
- German financial advice disclosure differs significantly from Japanese requirements
- Arabic disclosure standards have unique formatting and content rules
- EU accessibility requirements differ from American ADA compliance standards
Compliance architecture requirements:
- PII redaction by language and jurisdiction
- Cross-border conversation residency checks
- Language-specific audit trails
- Regional data retention policies
Financial chatbots with compliant multilingual architecture receive faster market approvals and maintain lower ongoing audit costs.
Critical Mistake #6: English-Only Testing Misses 60-70% of Real Issues
Testing multilingual chatbots primarily in English misses the majority of real-world conversation issues. Large-scale linguistic bias studies of ChatGPT analyzing ten English dialects found that models default to “standard” varieties of English—responses to non-standard varieties consistently exhibit stereotyping (19% worse than standard varieties), demeaning content (25% worse), lack of comprehension (9% worse), and condescending responses (15% worse)—demonstrating that English-only testing completely misses real-world performance gaps for non-English dialects and languages, while academic research on multilingual LLMs proves that cultures with different linguistic structures require native-language testing rather than English translation, as prompting in native languages captures cultural and linguistic nuances that English-translation-based evaluation fundamentally misses, particularly for culture-related tasks requiring deep language understanding.
Real-world chatbot testing reveals that automated English-focused QA testing fails to catch critical issues: slang and dialects confuse bots, cultural references that work in English insult international users, and edge cases combining multiple languages expose logical failures that synthetic testing completely overlooks, while comprehensive analysis of 2,000+ multilingual benchmarks documents persistent gaps: English remains disproportionately evaluated despite intentional exclusion of English-only benchmarks, language coverage remains fragmented, and most academic benchmarks fail to reflect real-world, culturally authentic use cases.
CTOs must establish native speaker testing protocols for each target language, but many underestimate the complexity and cost of comprehensive multilingual QA.
Code-Switching Creates Invisible Testing Gaps
Multilingual users frequently:
- Code-switch between languages mid-conversation
- Use borrowed words from other languages
- Mix scripts within single conversations (Arabic + English, Japanese + romaji)
Testing strategies that don’t account for these patterns fail to identify critical usability issues that only emerge in production environments.
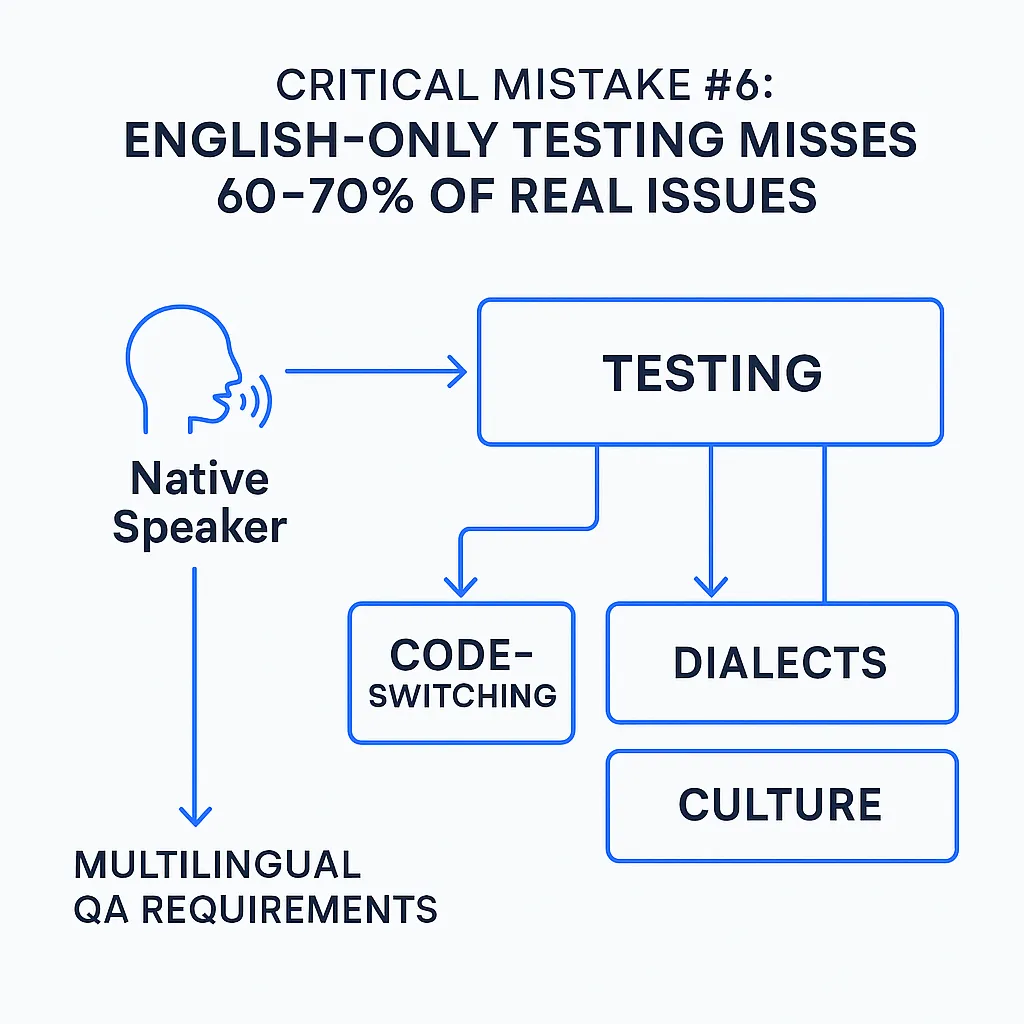
Fig3. Multilingual QA requirements
Using English-language performance metrics as benchmarks for other languages creates false quality assessments. Each language requires culturally appropriate success metrics and evaluation criteria that reflect local user expectations.
Critical Mistake #7: Legacy System Integration Failures Block Global Deployment
38% of multilingual chatbot deployments fail initial integration due to legacy backend or third-party systems lacking Unicode and right-to-left text support. CTOs often discover these compatibility issues only during late-stage testing.
Unicode and Script Rendering Requirements
Integration challenges include:
- Character encoding problems with CRM systems
- Right-to-left text rendering for Arabic and Hebrew
- Asian script rendering requiring special display considerations
- External API limitations for non-English languages
Relying on external APIs that don’t support target languages creates functionality gaps. Payment processors, verification services, and analytics tools often have limited multilingual capabilities that only become apparent during integration testing.
Critical integration checkpoints:
- Unicode support across all backend systems
- RTL text handling in user interfaces
- Script-specific rendering capabilities
- Third-party API language compatibility
- Analytics tool multilingual support
Strategic Recommendations: How CTOs Can Avoid These Mistakes
Multilingual chatbot development costs 3-5x more than English-only solutions, but pilot launches in two to three linguistically diverse languages reduce post-launch rework by significant margins. This staged approach allows architectural validation before full global deployment.
Vendor Selection Criteria
CTOs should prioritize vendors with:
- Demonstrated multilingual expertise with native language teams
- Region-specific case studies in target markets
- Proven track records in cultural adaptation
- Technical capabilities for dialect detection and regional segmentation
Risk Mitigation Framework
Stage 1: Linguistic Diversity Pilots
- Launch with 2-3 structurally different languages (e.g., English, Arabic, Chinese)
- Test architectural assumptions before full deployment
- Validate cultural adaptation approaches
Stage 2: Regional Expansion
- Add related dialects and regional variations
- Implement geo-aware scaling and edge deployment
- Establish language-specific success metrics
Stage 3: Full Global Deployment
- Scale to 10+ languages with proven architecture
- Implement continuous cultural calibration
- Monitor performance by language and region
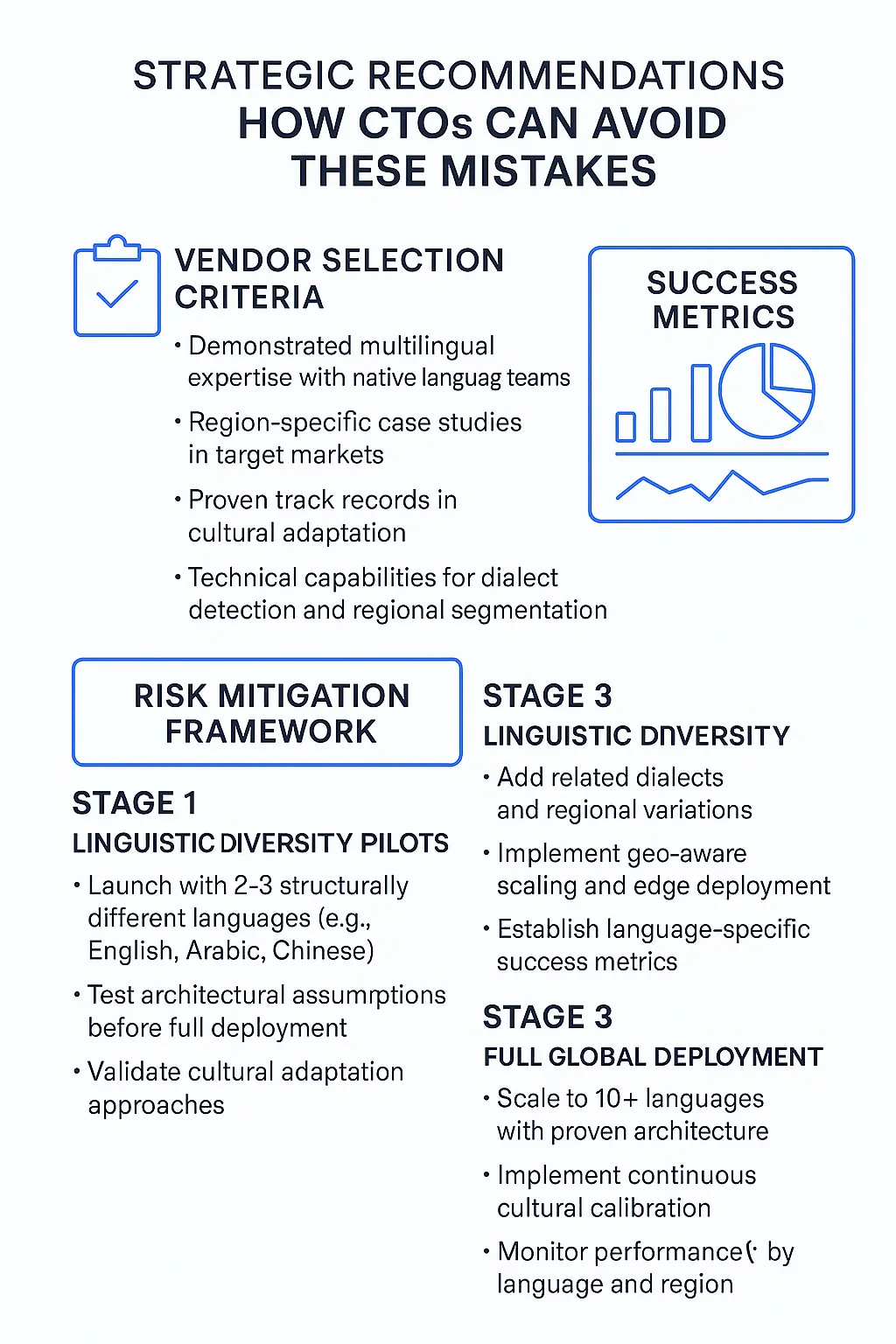
Fig4. Language-specific KPIs
Measuring Success: Language-Specific KPIs Matter
Properly implemented multilingual chatbots deliver 4-7x better user engagement and higher conversion rates in non-English markets when regional metrics are measured separately. Universal metrics mask critical performance variations across markets.
As documented in SmartDev’s GPT-5 e-commerce integration case study, H&M deployed an AI-powered multilingual chatbot across web, mobile, and social channels, automating nearly 80% of standard inquiries with instant responses in customers’ native languages, significantly improving customer satisfaction and demonstrating measurable engagement gains when measuring performance by region rather than aggregate metrics, while SmartDev’s enterprise chatbot research confirms that AI chatbots for personalized customer experiences—when properly localized—lead to higher engagement and better conversion rates, as customers respond more readily to offers tailored specifically for their language and region.
Industry data shows that businesses implementing multilingual chatbots report a 30% increase in engagement from non-English-speaking territories, with multilingual support delivering 40% higher customer satisfaction and 25% increased conversion rates, while comprehensive AI chatbot statistics document that shoppers using AI chat have 4x higher conversion rates (400% uplift) and multilingual implementations see 15-30% conversion rate increases when engaging customers in their native language, with 17% decreases in cart abandonment through proactive, localized support.
Advanced multilingual chatbots boost customer satisfaction by 40% and conversion rates by 25% when deployed with proper localization, validating that regional performance measurement reveals significantly higher ROI than aggregate, English-focused metrics.
Essential Metrics by Language Group
User Satisfaction Metrics:
- Task completion rates by language
- Response accuracy by cultural context
- User abandonment patterns by region
Technical Performance Metrics:
- Response latency by language combination
- Resource utilization by script type
- Error rates during code-switching
Business Impact Metrics:
- Conversion rates by market
- Customer retention by cultural group
- Support ticket reduction by language
Global chatbot success requires measuring these metrics separately for each language and cultural context rather than relying on universal averages that hide market-specific issues.
Building Long-Term Global Success
Multilingual chatbots require ongoing cultural calibration and language model updates as communication patterns evolve. CTOs must budget for continuous improvement, not just initial deployment costs. This includes regular retraining, cultural sensitivity updates, and performance optimization across all supported languages.
Despite higher initial costs, the ROI justification becomes clear when considering market expansion potential. Companies that properly implement multilingual chatbots gain competitive advantages in global markets where localized digital experiences drive customer preference and loyalty.
The path to success requires acknowledging that multilingual deployment isn’t just translation—it’s architectural, cultural, and operational transformation that demands specialized expertise and long-term commitment.
Ready to build a multilingual chatbot that actually works across global markets? SmartDev’s AI consulting team has delivered successful multilingual deployments across 16 countries. Contact our experts to avoid these costly mistakes and accelerate your global expansion.











